# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT


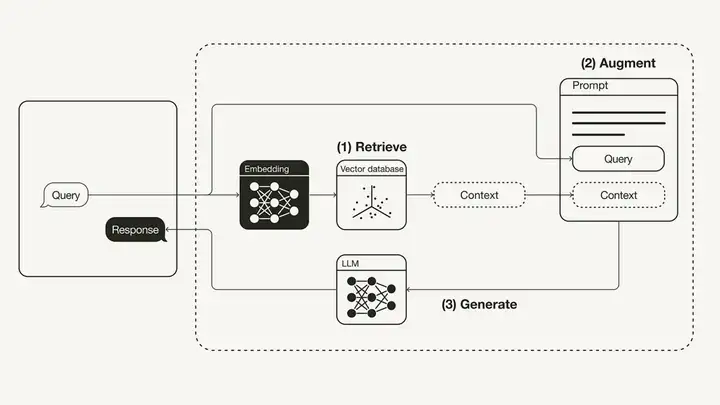
随着ChatGPT等通用大模型风靡,业界逐渐认识到仅凭模型本身难以满足企业对实时、准确知识的需求。这催生了“检索增强生成”(Retrieval-AugmentedGeneration,RAG)架构的兴起:通过检索机制为模型提供最新且相关的上下文,被视为解决大模型“幻觉”和知识时效性问题的关键。自2020年以来,RAG已成为企业部署聊天机器人等生成式AI应用的主流范式。
RAG技术为大模型的大脑植入了“即时查询接口”,让模型不再局限于训练语料,而是可随时获取外部知识。典型的RAG流程包括:
•从企业知识库中检索与用户查询相关的内容:系统首先根据用户查询,将自然语言问题转化为检索指令;通过嵌入向量检索(embedding search)、关键词检索(keyword search)或混合检索(hybrid retrieval),从企业知识库中迅速筛选出与问题最相关的一组文档片段。这一过程不仅比传统全文检索更灵活高效,还能处理语义相似但措辞不同的问题。
•动态构建上下文提示(prompt):检索回来的内容经过筛选、重排序,并被自动组织成新的提示上下文,与用户原始提问一起拼接,形成“携带知识”的复合输入。这一动态构建的上下文,是 RAG 系统生成准确回答的基础。
•模型生成推理式回答:最终,大语言模型(LLM)在接受到包含检索知识的新提示后,基于外部知识和自身推理能力,生成针对性的自然语言回答。
简单来说,RAG就像是给大模型装了一个随身小图书馆,每次回答问题前,它可以先去翻翻书,再动笔答题。这大幅提升了回答的准确性和时效性,使RAG被视为现代AI应用栈中的重要架构——连接通用大模型与面向企业的高效AI应用的的关键纽带。

目前,在RAG架构领域,主要有以下几种类型的公司:
•开源工具链提供者:如 LangChain 和 LlamaIndex,提供构建 RAG 系统的基础组件,适合开发者自行搭建和定制。
•专注 RAG 平台的初创公司:如 Vectara、Fixie 和 Contextual AI,提供端到端的 RAG 解决方案,强调系统的集成性和企业级应用。
•大型云服务商:如 Microsoft Azure、AWS 和 Google Cloud,提供 RAG 相关的 API 和服务,便于企业在其云平台上集成 RAG 功能。
•行业应用公司:如 Cohere 和 Perplexity AI,将 RAG 技术应用于特定行业场景,提供定制化的解决方案。
Contextual AI正是瞄准为企业提供RAG部署平台的初创公司,由最早在Meta提出RAG技术的研究人员创建。其使命是“改变世界运作方式”,通过RAG2.0技术,开发能够应对最复杂、知识密集型任务的专用型AI智能体。

Contextual AI产品工作流
1.企业使用agent时,首先需要向Contextual AI提供企业知识库。Contextual AI允许企业将其内部数据源(如文档、数据库)与平台集成,建立全自动的工作流,实现数据的实时更新和访问,避免了需要手动上传数据的繁琐过程。

2.在Contextual AI首页可以看到,它已预部署了金融、法律等垂直领域的解决方案,这些方案基于特定行业的上下文精度要求、常见工作流和基础知识库开发,企业用户可快速自建或调用现有智能体完成相关工作。
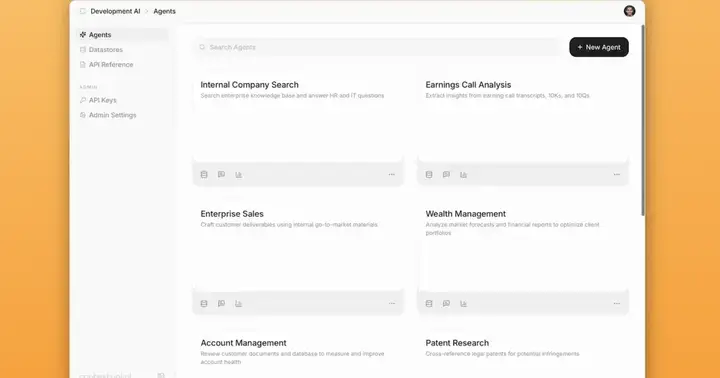
3.以Bond Investment Analysis智能体为例,用户提出问题后,Contextual AI按如下步骤进行思考:
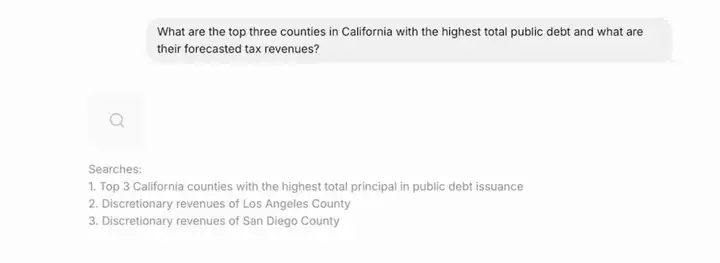
a.问题理解与拆解
系统首先识别出这是一个包含双重查询意图的问题,需要回答:哪些县的公共债务总额最高?这些县的未来税收收入是多少?
b.生成检索子任务
系统据此生成具体检索指令:Top 3 California counties with the highest total principal in public debt issuance(依此类推生成多条子查询)
c.执行检索与数据获取(retrieve)
每个子查询被映射到企业知识库中进行向量检索或混合检索,系统从结构化和非结构化的表格、PDF 报告、财务数据库等多源异构数据中提取出相关资料。
d.推理与回答生成
检索回来的各子任务结果,按逻辑链条组合在一起,大模型在此基础上完成最终推理,生成面向企业决策的高精度的自然语言回答,并附带来源引用,确保可追溯。
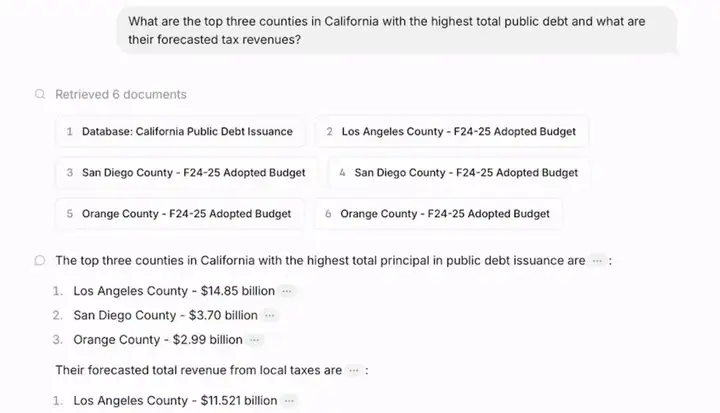
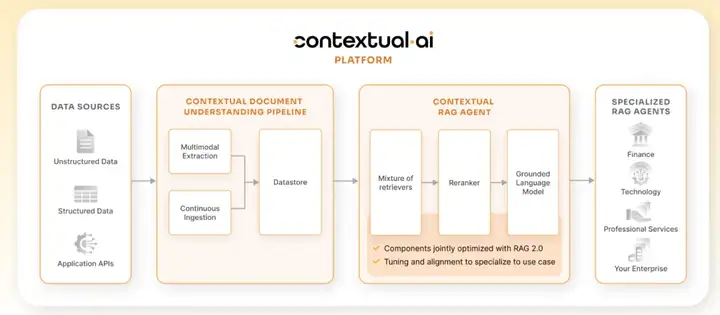
作为企业级解决方案,Contextual AI平台在功能上覆盖了从数据接入、检索、到生成的一整套流程,并针对复杂场景提供了多种增强能力:
•多模态检索:例如,对包含时间序列信息的视频资料采用善于理解时序关系的图结构检索,对文本/表格类资料并行采用向量检索,再由神经Reranker重排序汇总结果。
•结构化与非结构化数据接入:内置对企业内各种数据源的支持。平台可持续摄取海量非结构化文档(如含有图片、表格、代码片段的PDF报告或网页)以及数据仓库、数据库、电子表格等结构化数据,将它们融入检索库。此外还提供对Slack、Google Drive、GitHub等主流SaaS应用的预构建连接器,方便将实时业务数据纳入RAG的知识语境中。
•结果可解释性与可靠性:针对企业高要求的场景,平台生成的每个答案都附有精细的来源引用(标注具体出处文档并高亮相关片段)。同时提供“有根性”评分机制,自动标记缺乏依据的回答以提示潜在的幻觉风险。
•Contextual AI的工作流和输出形式与传统LLM产品类似,但传统大模型要达到企业生产环境要求的高准确性、可审计性和安全合规却极具挑战,而Contextual AI的RAG智能体则在根本上解决了大模型“宁愿杜撰也不会承认无法查询到数据”的常见幻觉问题。
•Contextual AI将自家平台定位为端到端的解决方案,帮助企业“轻松构建和部署高准确、可追溯、专为业务定制的RAG智能agent”,确保生成结果的高度可用性。为此,Contextual AI在传统RAG方案外提出了RAG2.0的技术路线。
•传统方案中,RAG往往通过将LLM预训练的模型、新增企业数据库和一个黑箱LLM生硬组合,通过一套固定的提示词或编排框架单线程串联,被Contextual AI比喻为“弗兰肯斯坦式”的怪物。
•相比之下,Contextual AI推崇的“RAG2.0”强调对检索模型和语言模型进行一体化的联合优化。该平台通过端到端的反向传播训练,让检索器和生成模型不再各自为政,而是统一对齐并协同调校参数。这样融合的架构虽然实现难度很高,但带来了检索与生成模块更紧密的耦合,大幅提升了系统的精准度和响应质量。如果说RAG1.0是给图书管理员布置任务,然后让其去翻书,RAG2.0就是一位边找资料、边思考和重塑策略的更聪明的consultant。
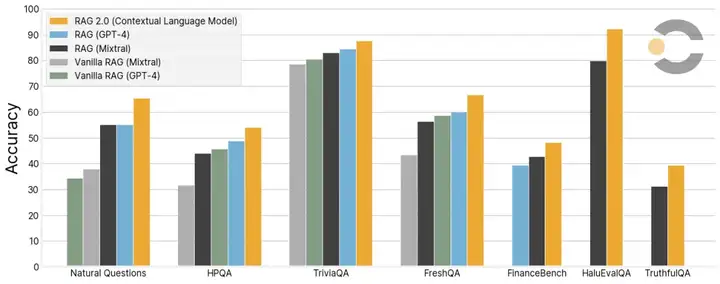
•2025年3月,Contextual AI更是推出了专为高可靠性场景优化的有根语言模型(Grounded Language Model, GLM),从架构层走向了自研模型。这款模型专为企业RAG场景优化,极大减少了AI回答中凭空捏造内容的情况,确保回答严格依据提供的资料,即具备很高的“groundedness”(有根性)。例如,面对一份包含“此结论只在多数情况下成立”字样的文档,GLM会忠实地提醒该限制条件,而非像普通模型那样,忽略细节直接给出普适答案。GLM在DeepMind发布的FACTS基准中取得了88%的事实正确率分数,明显高于同期Google、Anthropic和OpenAI等公司的最新模型。

团队:
•CEO Douwe Kiela是RAG理念的先行者——他在Meta(Facebook)负责的团队首创了RAG技术,此后担任HuggingFace的研究主管,并在斯坦福大学兼任教授,在业界和学界均有建树。
•联合创始人兼CTO Amanpreet Singh此前则在Meta的AI部门和HuggingFace从事研究工程工作,专注于多模态基础模型的开发与部署,在将模型应用到推荐排序、内容搜索等大规模生产系统方面积累了丰富经验。
融资情况:
•2023年,Contextual AI获得由Greycroft领投的2000万美元种子轮融资,用于启动研发。
•2024年8月,公司宣布完成8000万美元的A轮融资,投后估值约达6.09亿美元。本轮由老股东Greycroft继续领投,种子投资方之一Bain Capital Ventures(BCV)和Lightspeed等跟投;英伟达的投资部门NVentures也参与了此轮融资。
客户案例:
•汇丰银行(HSBC)正与该公司合作开发AI驱动的研究分析和流程指导助手,通过检索并综合最新的市场观点、财经新闻和内部文件,为员工提供决策支持。
•高通公司(Qualcomm)也与Contextual AI签署了多年合同,在客户工程团队部署其定制模型,用于从海量技术文档中精准检索答案,协助工程师更高效地解决客户问题。
创始人DouweKiela指出,RAG不只是生成式AI的辅助组件,而是发展成为主动检索与推理智能体系统的基础设施。“RAG仅仅是一个开始”。这为Contextual AI在未来智能体领域中的扩展,奠定了更大的技术与战略基础。
References:
https://contextual.ai/introducing-rag2/
https://www.mckinsey.com/featured-insights/mckinsey-explainers/what-is-retrieval-augmented-generation-rag
https://aimresearch.co/ai-startups/can-contextual-ai-monetize-rag-as-a-horizontal-infrastructure-layer-in-ai?ts=1745707084
https://venturebeat.com/ai/contextual-ais-new-ai-model-crushes-gpt-4o-in-accuracy-heres-why-it-matters/
https://blogs.nvidia.com/blog/contextual-ai-retrieval-augmented-generation/
https://www.crunchbase.com/organization/contextual-ai
https://www.computerworld.com/article/3843220/finally-some-truth-serum-for-lying-genai-chatbots.html
https://medium.com/@researchgraph/rag-2-0-is-coming-9dd3a5b1986a
文章来自于“Z Potentials”,作者“Z Potentials”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
