# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
离开OpenAI,只是为了Meta天价薪资?Jason Wei离职博客,泄露天机:未来AI更令人向往!
硅谷人才争夺战,火热升级!
过去,是OpenAI从谷歌等公司吸引人才;现在,Meta直接砸钱抢人。
顶尖AI人才的薪酬包可谓天价,1亿美元还是扎克伯格给的起步价!
思维链之父、华人AI科学家Jason Wei,就是从谷歌跳槽到OpenAI,刚刚又跳槽到Meta。

在AI领域,Jason Wei非常高产。
根据谷歌学术统计,他有13篇被引次数超过1000的论文,合作者包括Jeff Dean、Quoc V. Le等知名AI研究员,参与了OpenAI的GPT-4、GPT-4o、o1、深度研究等项目。
离职消息被媒体爆出之前,他发表了两篇博客,或许能让我们看出他为何选择离开
意外的是,这些灵感都来自强化学习!


过去一年,他开始疯狂学习强化学习,几乎每时每刻都在思考强化学习。
RL里有个核心概念:永远尽量「on-policy」(同策略):与其模仿他人的成功路径,不如采取行动,自己从环境中获取反馈,并不断学习。
当然,在一开始,模仿学习(imitation learning)非常必要,就像我们刚开始训练模型时,必须靠人类示范来获得基本的表现。但一旦模型能产生合理的行为,大家更倾向于放弃模仿,因为要最大化模型独特的优势,就只能依靠它自己的经验进行学习。
一个很典型的例子是:相比用人类写的思维链做监督微调,用RL训练语言模型解数学题效果更好。
人生也一样。
我们一开始靠「模仿」来成长,学校就是这个阶段,合情合理。
研究别人的成功之道,然后照抄。有时候确实有效,但时间一长就能意识到,模仿永远无法超越原版,因为每个人都有自己独特的优势。
强化学习告诉我们,如果想超越前人,必须走出自己的路,接受外部风险,也拥抱它可能给予的奖励。
他举两个他自己更享受、却相对小众的习惯:
有一次收集数据集时,他花了几天把每条数据读一遍,然后给每个标注员写个性化反馈;数据质量随后飙升,他也对任务有了独到见解。
今年年初,他还专门花了一个月,把过去研究中「瞎搞」的决策逐条消融。虽然费了不少时间,但因此弄清了哪种RL真正好用,也收获了很多别人教不会的独特经验。
更重要的是,顺着自己的兴趣去做研究不仅更快乐,我也感觉自己正在打造一个更有特色、更属于自己的研究方向。
所以总结一下:模仿确实重要,而且是起步的必经之路。但一旦你站稳脚跟,想要超越别人,就得像强化学习那样on-policy,走自己的节奏,发挥你独有的优势与短板😄
验证非对称性,意指某些任务的验证远比求解更为简单。
随着强化学习(RL)的突破,这一概念正成为AI领域最重要的思想之一。
细察之下,验证非对称性无处不在:
有些任务的验证耗时与求解相当。例如:
有些任务验证比解决还费时。例如:
通过前置研究,可以让验证变得更简单。例如:
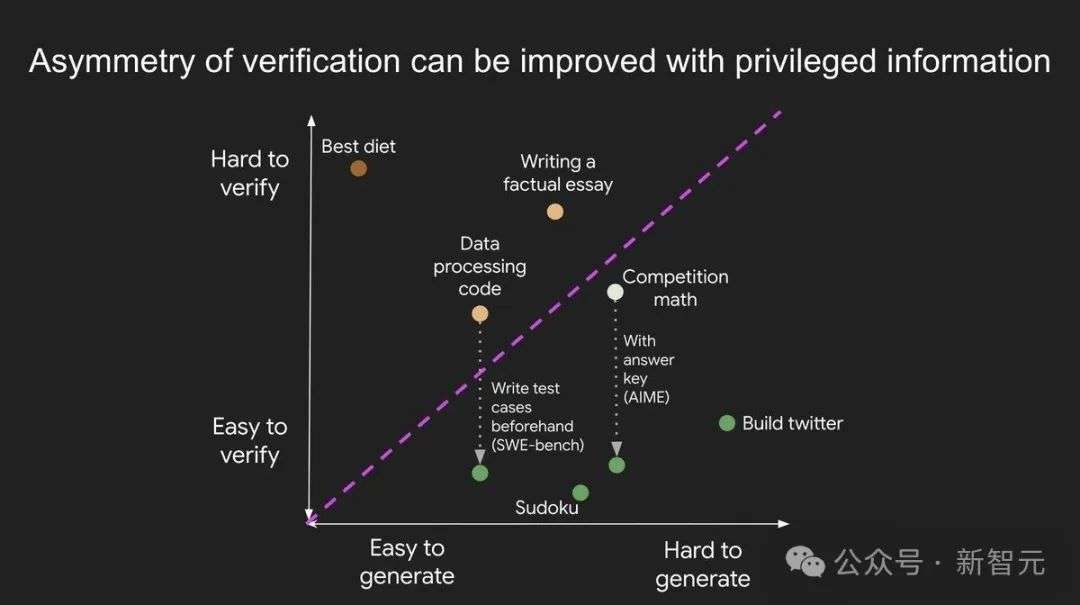
为什么验证非对称性如此重要?
深度学习史证明:凡是能被测量的,都能被优化。
在RL框架下,验证能力等同于构建训练环境的能力。由此诞生验证者定律:
AI解决任务的训练难度,与任务可验证性成正比。所有可解且易验证的任务,终将被AI攻克。
具体来说,AI训练的难易程度取决于任务是否满足以下条件:
1.客观真相:所有人对什么是“好答案”有共识。
2.快速验证:验证一个答案只需几秒钟。
3.可扩展验证:可以同时验证多个答案。
4.低噪声:验证结果与答案质量高度相关。
5.连续奖励:可以对多个答案的质量进行排序。
过去十年,主流AI基准测试均满足前四项——这正是它们被率先攻克的原因。尽管多数测试不满足第五项(非黑即白式判断),但通过样本平均仍可构造连续奖励信号。
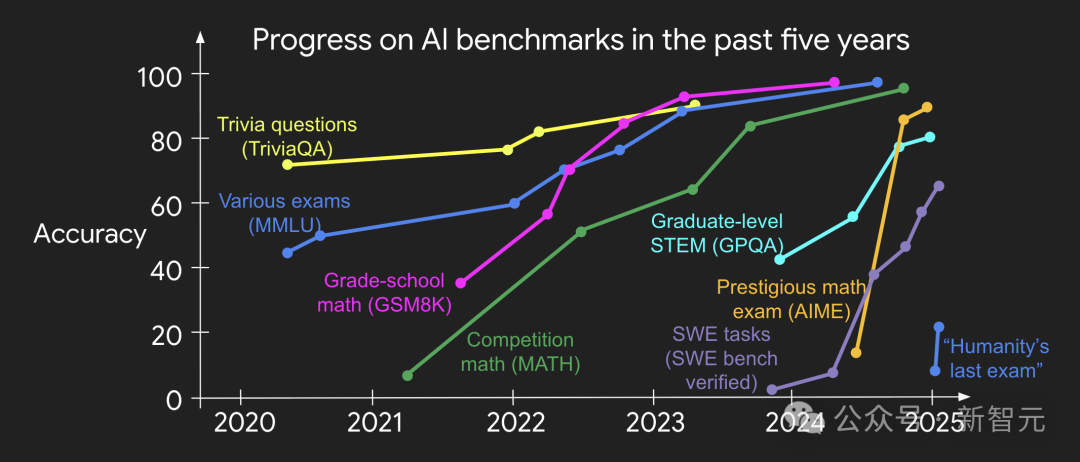
为什么可验证性重要?
根本原因是:当上述条件满足时,神经网络每一步梯度都携带高信息量,迭代飞轮得以高速旋转——这也是数字世界进步远快于物理世界的秘诀。
AlphaEvolve的案例
谷歌开发的AlphaEvolve堪称「猜想-验证」范式的终极形态。
以「求容纳11个单位六边形的最小外接六边形」为例:
悟透此理后,方觉验证之不对称,宛如空气无孔不入。
试想这样一个世界:凡能衡量的问题,终将告破。
智能的边界必将犬牙交错:在可验证任务中,AI所向披靡,只因这些领域更易被驯服。
这般未来图景,怎不令人心驰神往?
参考资料:
https://www.jasonwei.net/blog/asymmetry-of-verification-and-verifiers-law
https://www.jasonwei.net/blog/life-lessons-from-reinforcement-learning
文章来自于微信公众号“新智元”。


【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
