# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近年来, 大语言模型 (LLM) 在数学、编程等 "有标准答案" 的任务上取得了突破性进展, 这背后离不开 "可验证奖励" (Reinforcement Learning with Verifiable Rewards, RLVR) 技术的加持。RLVR 依赖于参考信号, 即通过客观标准答案来验证模型响应的可靠性。这种方法在具有明确定义解决方案的任务中特别有效, 如数学推理和代码生成, 其中简单的基于规则的验证器可以提供清晰的二元信号 (正确或错误)。但是, AI 在 "写作" 这种没有标准答案、评价高度主观的任务上, 总是差点意思。比如, AI 写的文章容易啰嗦、解释冗余、甚至自卖自夸, 难以真正打动人心。
这里分享一篇文章们最近提出的 Writing-Zero, 在以 Creative Writing 为代表的 Non-Verifiable Tasks 领域首次尝试利用 Reasoning GenRM 来进行 的 RLVR 训练
标题: Writing-Zero: Bridge the Gap Between Non-verifiable Tasks and Verifiable Rewards
地址: https://arxiv.org/pdf/2506.00103
公司: 夸克 LLM, 阿里

现在的 LLM 训练过程中, 针对不同的 Tasks, 存在一个从可验证到不可验证的连续谱 (Spectrum):
对于较难验证或不可验证的问题, 现有研究主要依赖于通过人类偏好数据训练的标量奖励模型 (Scalar Reward Model) 进行 RLHF (Reinforcement Learning from Human Feedback) 训练。传统的 AI 写作训练, 就是主要靠 "人类偏好打分" 来指导模型, 但这种方法有两个大问题:
1.泛化能力差: 人类打分的数据有限, 模型学到的只是 "表面套路"。
2.Reward Hacking: 容易被 "投机取巧", 比如 AI 发现 "写得越长、解释越多" 就能拿高分, 于是疯狂灌水, 内容质量反而下降。
研究目标 && 关键创新点
基于以上工作, 我们能发现一个明显趋势: RLVR 的应用场景正在从 Verifiable 任务向 Non-Varifiable 任务演变, 而近期出的 Reasoning GenRM 的有效性, 给 Non-Varifiable Tasks 提供 Verifiable Rewards 指明了方向。当下最显而易见的问题是: 怎么使用 GenRM, 在 Non-Varifiable Tasks 上, 通过 RLVR 取得稳定、Scalable 的提升? 因此, 我们旨在弥合不可验证任务和可验证奖励之间的差距, 为不可验证的写作任务提出新的训练范式。
具体而言, 我们提出了一套全新的训练范式, 首次让 AI 在 "写作" 这种主观任务上, 也能像做数学题一样获得 "可验证" 的奖励信号, 主要包含以下三个关键创新点:
1.Pairwise Writing Generative Reward Model
2.Bootstraped Relative Policy Optimization (BRPO)
3.Writing-Zero 无需监督微调, 直接 RL 训练, 探索 LLM 在没有监督数据的情况下发展写作能力的潜力
Pairwise Writing GenRM
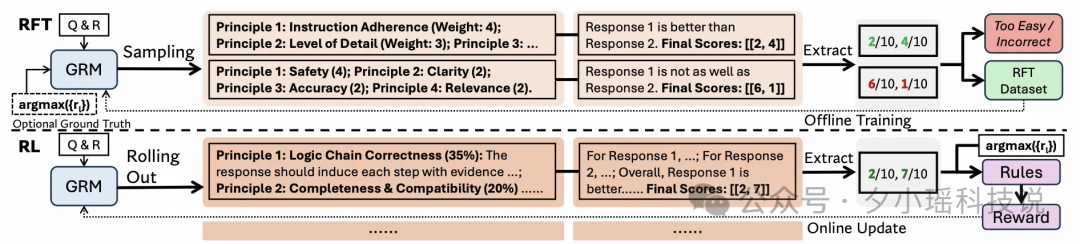
参考 Deepseek-GRM 的方法, Pairwise Writing GenRM 分成 4 个步骤进行训练:
1.数据筛选: 从原始 Preference 数据 (之前 Scalar RM 的人工标注训练数据) 中筛选出高质量的数据
2.Prompt 设计

3.Cold-Start Data Collection
4.通过 RLVR (GRPO) 优化 GenRM, 判断 Preference 预测是否正确, 相关训练细节如下:
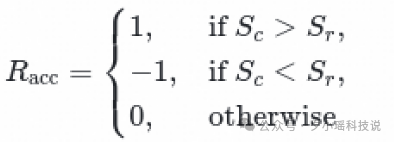
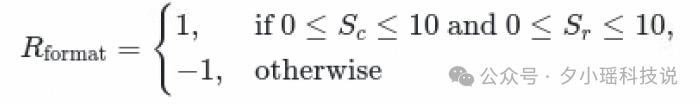
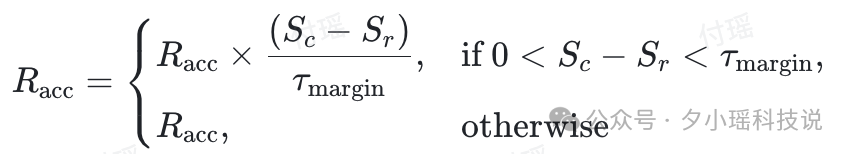
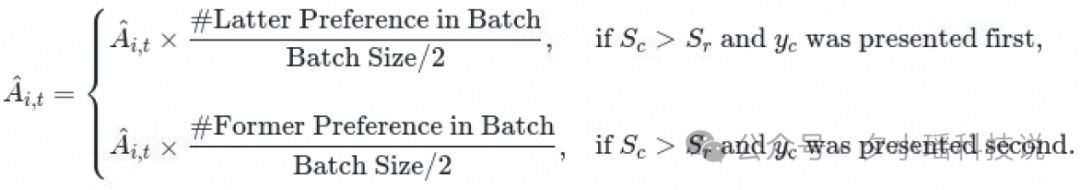
Dynamic Sampling:对Score 全为0或全为1的 Prompt 进行 Drop
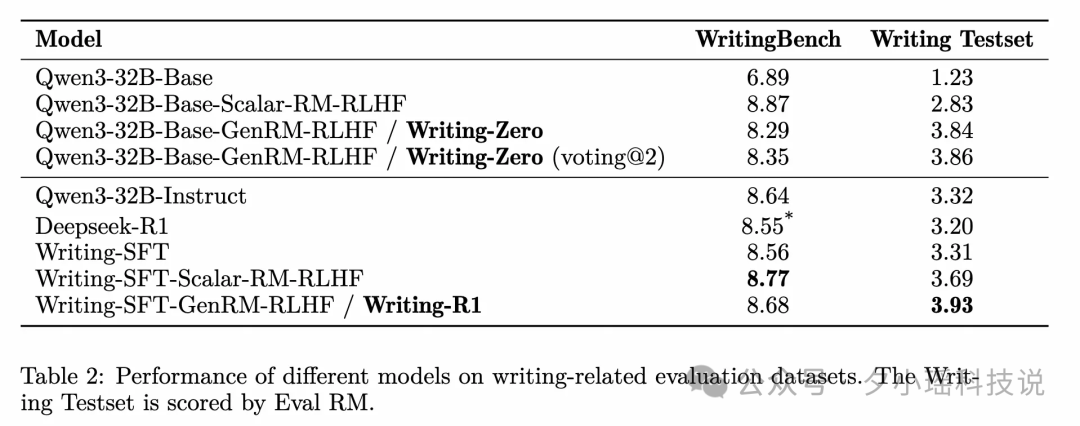
GenRM 实验结果
GenRM 的 RL 效果:
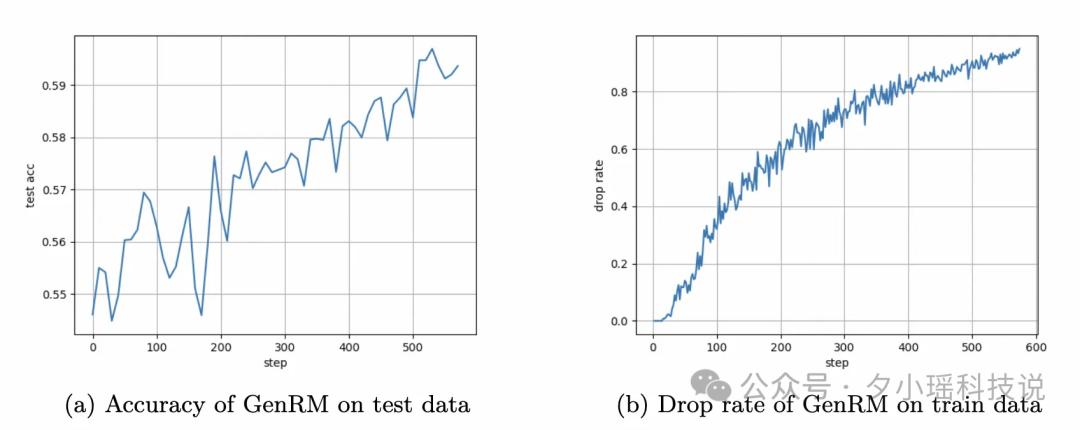
在 RM 的 Benchmark 上取得不错的成绩 (前两个是内部测试集, 后两个是开源测试集)
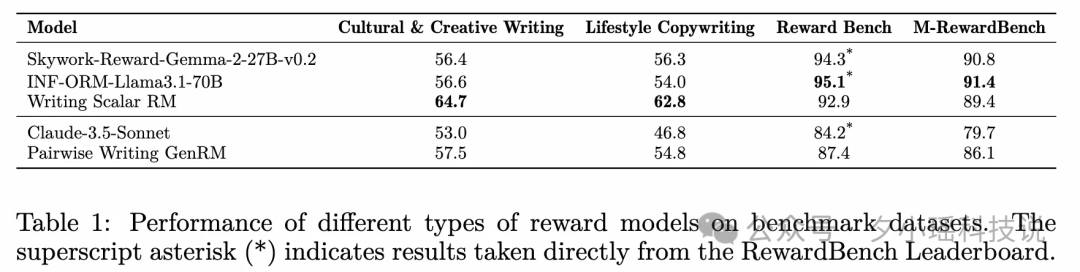
具备 Test-Time Scaling 的能力
Bootstraped Relative Policy Optimization (BRPO)
Non-Varifiable Tasks 和其他任务最大的区别是没有标准答案, Ground Truth Answres。为此我们通过 Policy Model 自举 (Bootstrap) 的方式随机采样得到一个 Reference 做一个相对 (Relative) 的比较。
我们提出的 BRPO 是对 GRPO 的一种改进, 具体地

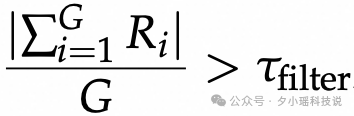
Writing-Zero: 在我们内部专门训练的文创 Eval RM 上, GenRM 训练稳定且达到了 SFT + RL 的效果, Scalar RM 训练不稳定且很早就出现明显的 Hacking 问题
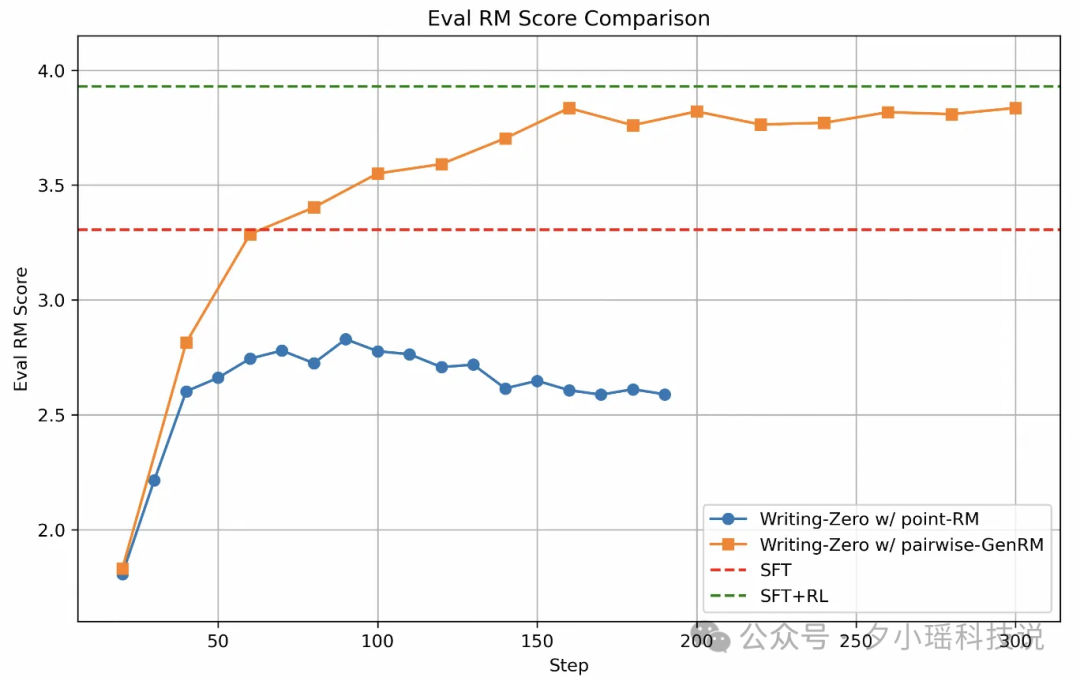
Writing-R1: 在我们内部文创测试集 Writing Testset 上胜出, 同时人工送评对比 SFT、SFT + Scalar RL 的 GSB 也胜出
Case 分析
通过对比下面 3 个 Case, 可以发现 GenRM 训练出来的模型更加人性化和有文艺气息。
Case 1: 请为陪伴 15 年的猫咪设计告别卡片文字, 要体现我和猫咪的深厚感情


Case 2: 作为《罗马假日》影迷, 在西班牙台阶拍摄打卡照时需要配文, 要求含蓄致敬经典但避免直接引用台词

Case 3: 你的朋友刚失恋, 想去他家探望。给他发条信息, 用食物隐喻表达你的安慰, 既不直接提及失恋又能让他感受到你的理解和支持。

文创场景的 Reward hacking
Scalar RM 在 RL 训练中比较常见的 Hacking 现象: 过度解释、谄媚、长度越训越长, GenRM 表现出对 Hacking 问题的抗性。

GenRM 的位置偏差问题和 Test-Time Scalability
在冷启动阶段后, 模型表现出明显的位置偏好 (倾向于给后一个响应更高的分数), 这种偏差在强化学习阶段可以自动校准, 通过引入额外的权重项, 成功降低了偏好比例的方差。
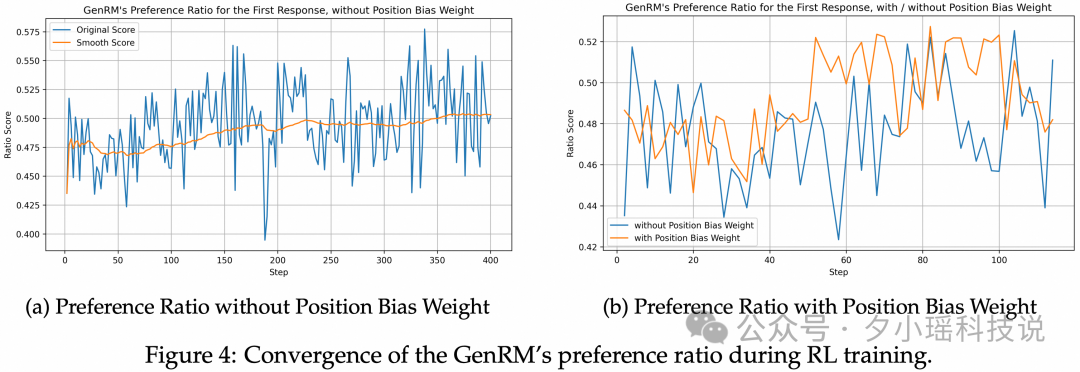
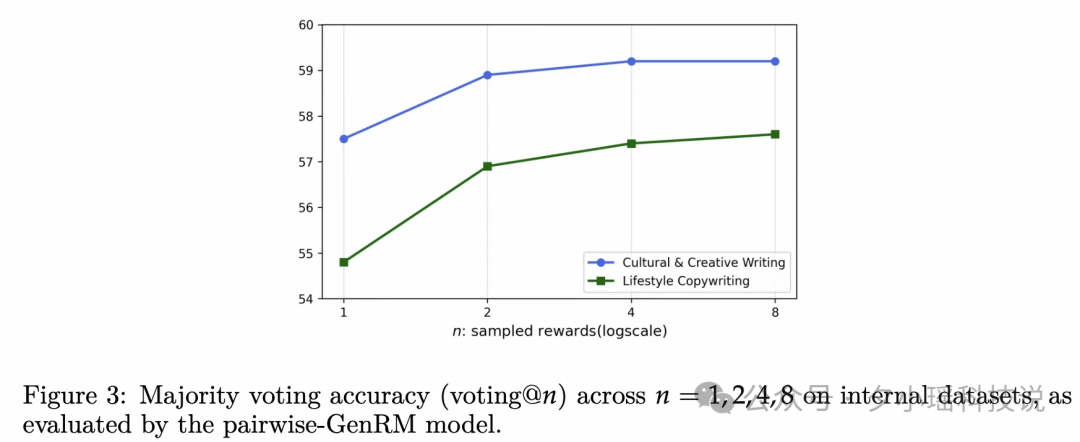
GenRM 可以通过交换位置、多次采样投票的方式提高 RM 和 RL 的效果, 当 GenRM 的效果提升之后, Test-time scaling 的潜在收益会更值得挖掘。比如, 在 GenRM voting 数量超过 1 的情况下, 有可能出现预测不一致的问题, 我们预期只鼓励稳定胜出 Reference 的样本, 对于不一致的结果, 可以不鼓励也可以打压。
Intuition Behind Reference Selection of BRPO
文创场景和 QA 问答等场景最大的区别在于, 没有 Ground-Truth Answer 标准答案作为参考, "文无第一", Reward 好坏只能通过比较出来的。
我们初步实验有考虑保留每次 Group Rollout 中最好的一个 Response 作为下次训练用于比较的 Reference, 但是我们发现在训练过程中, Policy 的整体效果已经有很大的提升, 使用旧 Reference 会引入 Offline 问题, 影响效果。而且我们始终是在做 Relative 的比较, 而不是绝对的排序, 无法通过 Pairwise 的结果来得到一个最终 Listwise 的顺序, 要想有绝对顺序还需要引入 Pointwise 的 RM, 如无必要勿增实体。于是最终有了 BRPO 的 Policy 自举比较的方法。
研究意义
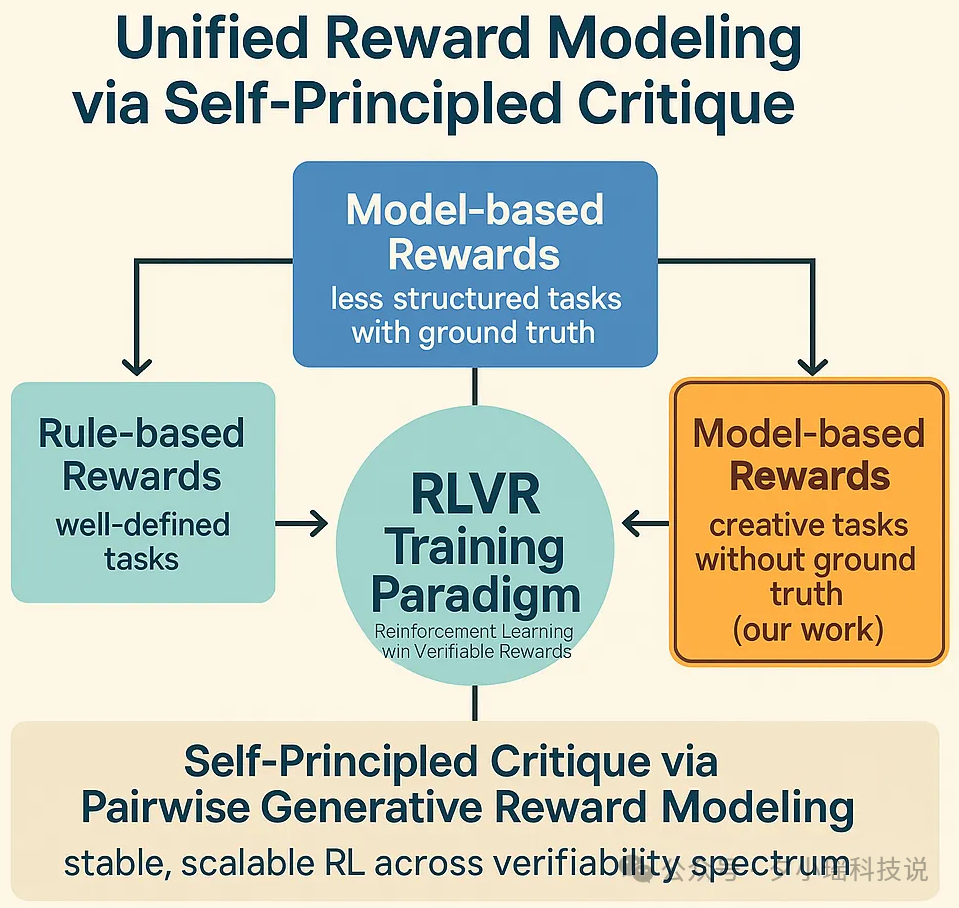
我们的工作代表了在 RLVR 训练框架下统一不同奖励建模范式的最后一块拼图, 通过利用具有自原则批评 (Self-Principled Critique) 的成对生成式奖励建模 (Pairwise Generative Reward Modeling), 即使是创意写作 (Creative Writing) 等不可验证的任务也能从稳定和可扩展的强化学习训练中受益。这为统一三种主要的 Reward Modeling Approaches 铺平了道路:
我们的工作为建立全面且一致的 RLVR (Reinforcement Learning with Verifiable Rewards) 训练范式铺平了道路, 该范式可以应用于从高度可验证 (Highly Verifiable) 到完全不可验证 (Completely Non-Verifiable) 的整个语言任务谱系 (Spectrum of Language Tasks)。
Future work
基于 Reasoning GenRM 在 Creative Writing 任务上的出色效果, 我们正在进行在 GenRM + Non-Verifiable Tasks 的下一阶段探索, 相关的报告也在整理中, 很快就会发布出来, 主要有以下核心工作:
1.引入 GenRM 和 Writing Model 的对抗训练来进一步提升最终模型的效果
2.魔改 Verl, 支持 Multi Models Pipeline Training + Rollout, 并复用同一 GPU Group 资源 (主要是卡少, 否则可以直接开多个 Group)
AI 写作的 "天花板" 其实是奖励机制的天花板, 我们希望通过 Writing-Zero, 推动 AI 从 "会写" 到 "写得好", 让 AI 真正成为人类创意的得力助手。如果你对 AI 写作、奖励建模、RLHF 等话题感兴趣, 欢迎留言交流, 或阅读我们的论文原文!
文章来自于微信公众号“夕小瑶科技说”。



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
