# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在人工智能领域,对比语言 - 图像预训练(CLIP) 是一种流行的基础模型,由 OpenAI 提出,支持零样本分类、检索等下游任务,并可作为多模态大语言模型(MLLM)的视觉编码器。
尽管 CLIP 已经成功地在数十亿规模的英语图文对上进行了训练,但进一步扩展到全球范围内的数据仍面临以下两项挑战:
为了解决这些挑战,来自 Meta、MIT、普林斯顿大学、纽约大学的研究者提出了 MetaCLIP 2,这是首个从零开始在原生全球图文对上训练 CLIP 的方法,不依赖任何外部资源,包括私有数据、机器翻译或蒸馏。可以看到,作者中有 AI 圈知名的学者刘壮和谢赛宁。
实验证明,CLIP 中的「多语言诅咒」实际上是由训练规模不足造成的,而这种不足源于缺乏针对全球数据的有效整理与模型训练策略。研究者发现,当元数据、数据筛选、模型容量与训练方法被共同精心设计并进行同步扩展时,英语与非英语之间的性能权衡会消失,并且二者之间能够实现互相促进。
这种「全球尺度」的训练方式具有极高的价值,尤其考虑到英语互联网数据即将耗尽的背景。

具体来讲,MetaCLIP 2 方法建立在英文版本的 MetaCLIP 基础之上,并刻意与 OpenAI CLIP 的原始架构保持最大程度的一致。这种架构上的重合,使得本文的研究发现可以被更广泛地应用于 CLIP 及其变体,而不仅仅是某些追求 SOTA 的系统性工作,因为后者往往依赖于大量技术组合,涉及混合因素或使用外部资源来比较,而不是专注于 CLIP 本身。
为了实现真正意义上的全球扩展能力,MetaCLIP 2 提出了三项核心创新:首先是元数据拓展,将英文 MetaCLIP 使用的元数据扩展到了 300 多种语言,涵盖维基百科与多语言 WordNet。其次是数据筛选算法,设计了按语言划分的子串匹配与均衡算法,使非英语数据的概念分布尽可能接近英文数据。最后是训练框架,首次设计了全球范围的 CLIP 训练方案,其中在训练过程中,随着非英语数据量的引入,成比例地增加图文对的使用次数,并研究了在全球数据规模下所需的最小可行模型容量。
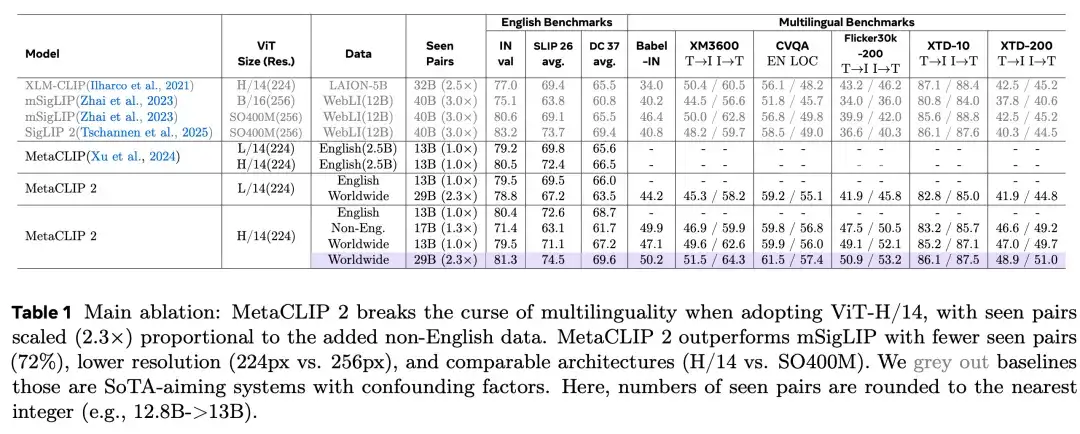
如下图 1 所示,虽然 ViT-L/14(OpenAI 使用的最大模型)仍然受到「多语言诅咒」的影响,但更大的 ViT-H/14 模型则打破了这一限制。在 ImageNet 上的英语准确率从 80.5% 提升到了 81.3%,并且在多语言图文检索任务中也创下了新的 SOTA 成绩(XM3600 64.3%、Babel-ImageNet 50.2%、CVQA 57.4%),而这一切几乎没有改变 CLIP 的核心架构。
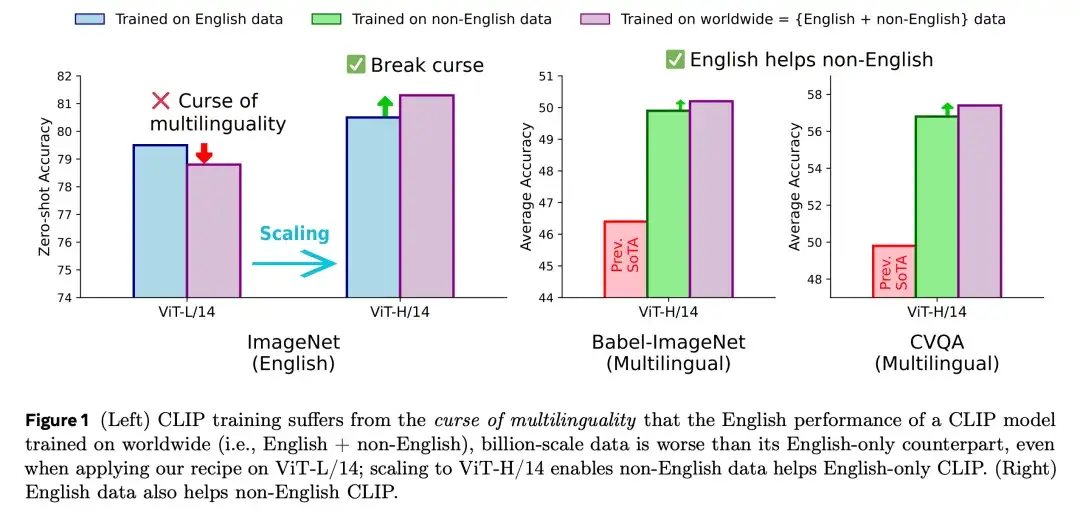
综合来看,MetaCLIP 2 实现了多项令人期待的成果。
一,英语与非英语数据之间实现了互利:非英语数据能够更好地增强英语模型的能力,反之亦然,这一点在英语互联网数据日益枯竭的当下尤为关键。
二,完全支持多语言:MetaCLIP 2 从不因语言而丢弃图文对,模型性能全面超越现有多语言系统,如 mSigLIP 和 SigLIP 2。
三,原生语言监督:模型直接学习来自母语使用者所写的图像描述,而非依赖机器翻译生成的合成文本。
四,文化多样性:MetaCLIP 2 保留了全球图像的完整分布,涵盖了广泛的文化和社会经济背景,有助于提升地理定位与区域识别的能力。
五,无过滤理念:通过面向全球设计的数据筛选算法,MetaCLIP 2 移除了整个训练流程中最后一个语言过滤器(即是否为英文描述),提升了多样性并减少了人为偏差。
六,基础数据影响力更广泛:本研究提供了一个全球规模的图文对基础数据集,不仅有利于 CLIP 本身,也为其他使用 CLIP 数据的工作提供了支持,例如多模态大模型(MLLM)、自监督学习(如 Web-DINO)以及图像生成(如 DALL-E 和扩散模型)。
论文一作 Yung-Sung Chuang 在社媒 X 上表示,「是时候舍弃语言过滤器了。」
MetaCLIP 2 架构算法
扩展 CLIP 到原生全球数据包含三个步骤,(1)构建全球范围的元数据,(2)实施全球范围的数据筛选算法,以及(3)搭建面向全球模型的训练框架。为了确保方法和结论具有泛化性,MetaCLIP 2 在设计时尽量与 OpenAI CLIP 和 MetaCLIP 保持一致,仅在必要之处做出调整,以更好地从全球数据中学习。
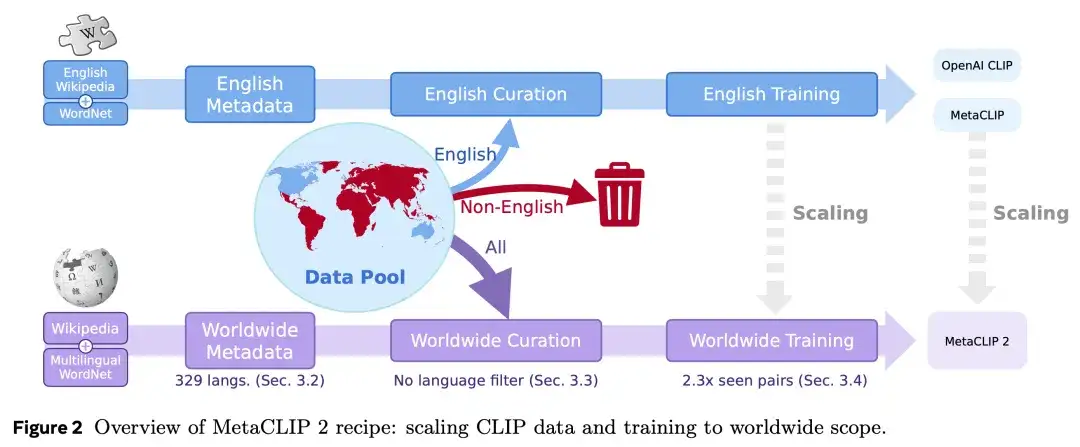
世界范围内的元数据
本文通过构建覆盖非英语世界所缺失的元数据,来解决全球规模化进程中的首要挑战。他们为每种语言维护独立的元数据集,这种设计既符合直觉(例如同一个单词 mit 在英语和德语中含义不同),又能提升系统性能,同时便于未来灵活地新增和优化其他语言版本。
元数据与 OpenAI CLIP 和 MetaCLIP 同源(均来自四大数据源),但覆盖了英语之外的语种。核心改进如下:
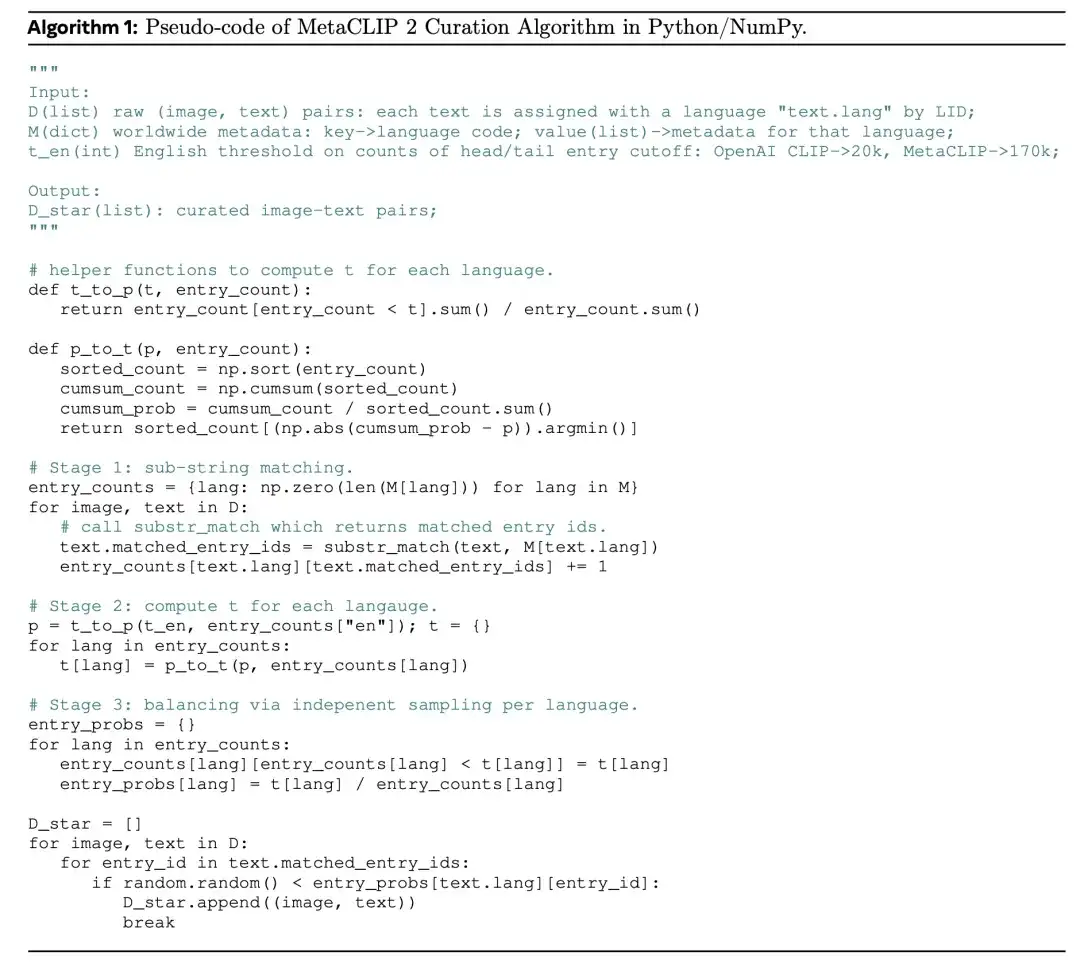
筛选数据算法的伪代码如算法 1 所示,原始图文对数据集 D、元数据集 M 等作为输入,经过三个阶段,输出一个平衡且多样化的训练数据集 D∗ 。
训练框架
本文进一步设计了全球数据范围内的 CLIP 训练框架。为确保该框架及研究成果能推广至 CLIP 及其衍生模型,本文延续了 OpenAI/MetaCLIP 的训练设置和模型架构,并新增三个关键组件:(1) 多语言文本 tokenizer,(2) 可见训练对的规模扩展(scaling seen training pairs),以及 (3) 最小可行模型容量研究。
可见训练对规模扩展。当数据分布从单一英语扩展到全球多语言时,可用图文对数量随之增长。若在全球版 CLIP 训练中保持与英语 CLIP 相同的训练对采样量,将导致英语训练对被降采样,进而损害模型在英语任务上的性能。为此,本文根据非英语数据规模的增长比例同步扩大训练对总量,确保英语训练对数量在全球训练过程中保持不变。
具体实现上,本文通过扩大全局训练批次规模(同时保持其他超参数不变)来实现这一目标 —— 此举既能维持英语数据比例,又能促进跨语言学习。基于英语数据占训练集 44% 的实际情况,本文选择将全局批次扩大 2.3 倍。
实验结果
关于数据集和训练设置,研究者遵循 MetaCLIP 的流程,从互联网上收集公开可用的图文对。在进行语言识别之后,大约 44% 的图像描述(alt-text)为英文,这一比例与 MetaCLIP 中英文数据的规模相当。
为了让本文的训练方法和实验结果具有普遍适用性,研究者主要基于 OpenAI 的 CLIP-ViT-L/14 模型和 MetaCLIP-ViT-H/14 模型进行训练。完整的训练细节见下表 6。

研究者首先在一系列英文与多语言的零样本迁移评测基准上,展示了 MetaCLIP 2 的主要消融实验结果,并与其他多语言版本的 CLIP 模型进行对比。
结果如下表 1 所示,在 ViT-H/14 模型上使用全球数据并扩大训练中所见图文对数量时,MetaCLIP 2 在英文和多语言任务上都稳定优于仅用英文(1.0 倍)或非英文(1.3 倍)数据的对照组,有效地打破了「多语言的诅咒」。而在图文对数量未扩展的情况下(如 Worldwide 1.0 倍)或者使用较小的 ViT-L/14 模型(即使使用了 2.3 倍的全球数据),这一诅咒仍然存在。
尽管 MetaCLIP 2 的目标并不是追求 SOTA,但其完整的训练方法在使用更少图文对(仅为 SigLIP 系列的 72%)和更低分辨率(224px,mSigLIP 为 256px)的前提下,依然展现出了强劲性能。
在多个基准上,MetaCLIP 2 超越了 mSigLIP(如 IN、SLIP 26、DC 37)以及最近的 SigLIP 2(后两个任务)。更重要的是,MetaCLIP 2 在多个多语言评测中创下新的 SOTA 纪录,例如在 Babel-ImageNet 上提升 3.8%、在 XM3600 上提升 1.1% / 1.5%、在 CVQA 上提升 3% / 7.6%、在 Flickr-30k-200 上提升 7.7% / 7% 以及在 XTD-200 上提升 6.4% /5.8%。
相比之下,SigLIP 2 更侧重英文训练(其训练数据中有 90% 为英文),因此在多语言任务上的表现不如 mSigLIP,在大多数英文评测上也不如 MetaCLIP 2,唯一的例外是 ImageNet。
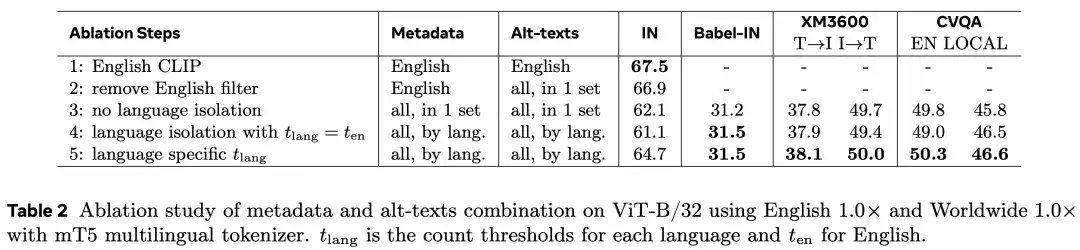
研究者进一步进行消融实验,探讨了从「仅基于英文的元数据和筛选策略」过渡到「面向全球多语言的设置」对模型性能的影响。为了提高实验效率,他们在 ViT-B/32 编码器上进行训练,并在 ImageNet(IN)上评估英文零样本迁移性能,在 Babel-ImageNet、XM3600 和 CVQA 上评估多语言表现。
如下表 2 所示,实验从英文版 CLIP 开始。首先移除图像描述(alt-text)的英文过滤器,使所有描述都使用英文元数据进行筛选。这样做导致 ImageNet 上的性能下降了 0.6%,说明在匹配文本或元数据之前按语言识别对英文内容进行隔离非常重要。
接着,研究者将英文元数据替换为不分语言、混合而成的多语言元数据。结果表明,英文性能进一步下降,但模型开始具备一定的多语言能力。随后采用逐语言处理的子串匹配策略,在所有语言中使用统一的前十个匹配关键词(ten)进行筛选。这一做法导致英文性能再次下降,因为「ten」值对于非英语语言来说过高,导致数据筛选偏向高频语言,从而影响整体均衡。
最后,研究者引入了一个名为「t_lang」的调整机制,用于保持每种语言中高频与低频概念的比例一致。该机制在提升英语和非英语表现的同时,也优化了各语言之间的均衡分布。不过,即便如此,在 ViT-B/32 模型规模下,「多语言诅咒」依然未能彻底解决,直到在主消融实验中引入更大模型与更大规模训练对数据后才实现突破。
为了尽量减少对模型架构的修改,研究者仅将英文 tokenizer 替换为多语言 tokenizer。在零样本评测中,他们测试了四种主流的 tokenizer。正如表 3 所示,XLM-V 的词汇表在英文和非英文任务中都表现出最优的性能。
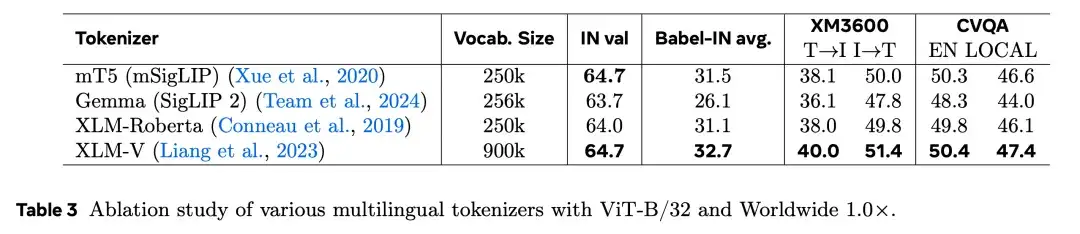
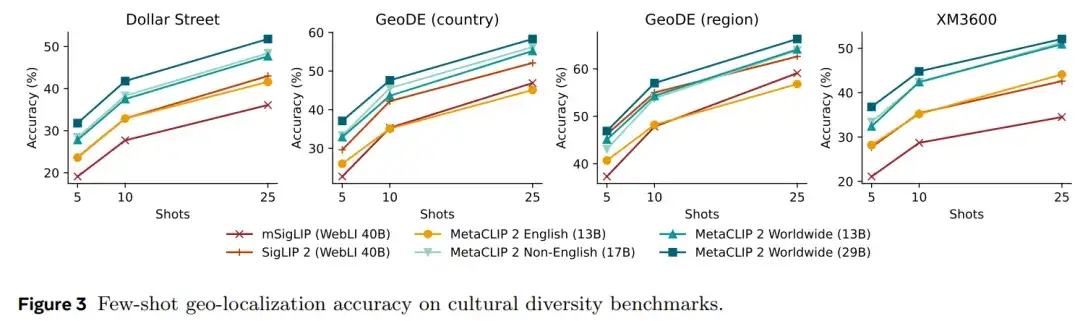
图 3、表 4 表明,仅仅将训练数据的分布从 130 亿对英语图文对切换为 130 亿对全球图文对,就能带来显著的性能提升;进一步扩展到 290 亿对全球图文对时,性能继续提升,唯一的例外是 GeoDE,表现与前者持平,可能已经接近饱和。图 3 中的小样本地理定位评估也呈现出类似趋势。

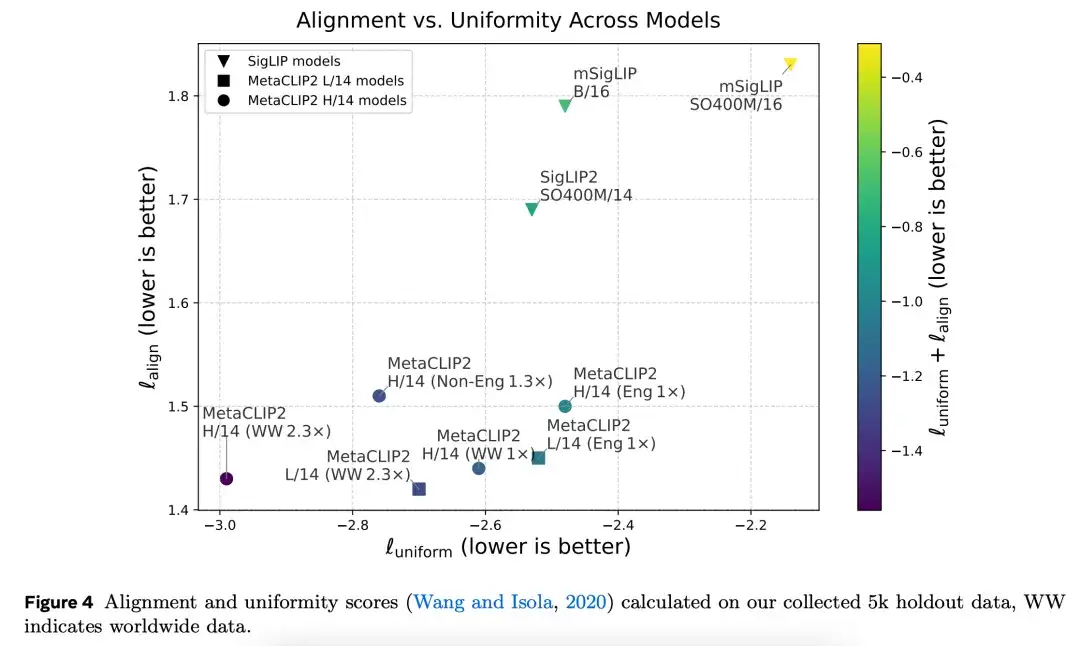
研究者进一步评估了不同 CLIP 模型在嵌入质量方面的表现。从图 4 可以看出,MetaCLIP 2 在对齐度和均匀性两个指标上均表现良好(值更低),而 mSigLIP 、 SigLIP 2 存在一定的偏差。
文章来自公众号“机器之心”


