# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
又一个SOTA基础模型开源,而且依然是国产。
刚刚,阶跃星辰兑现了WAIC上的承诺,将最新多模态推理模型Step-3正式开源!
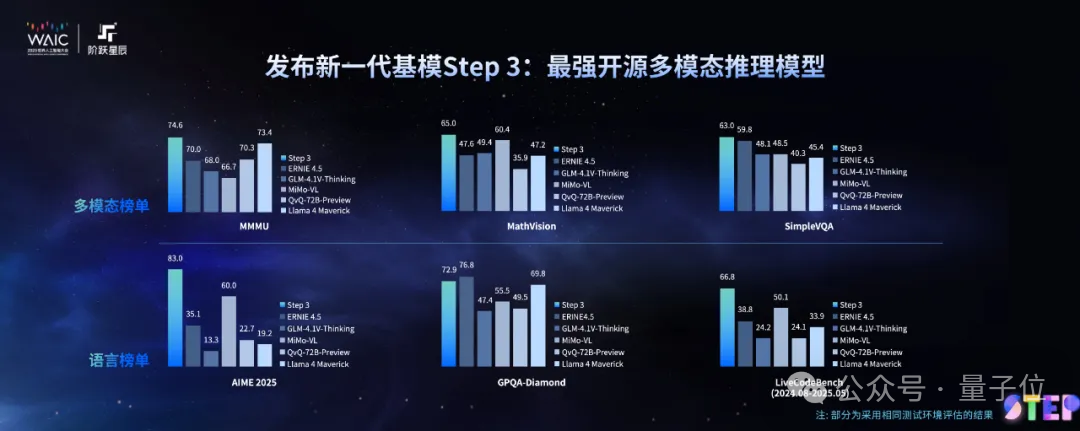
在MMMU等多个多模态榜单上,它一现身就取得了开源多模态推理模型新SOTA的成绩。
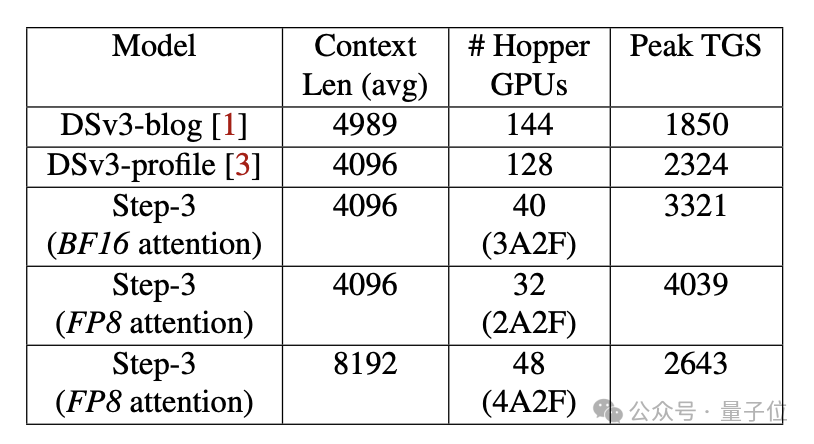
并且速度飞快,在Hopper GPU上每秒可以解码4039个Token(4K上下文、FP8、无MTP),是DeepSeek-V3的174%。
这一表现,也给大模型解码设定了新的帕累托前沿(资源分配的一种理想状态)。
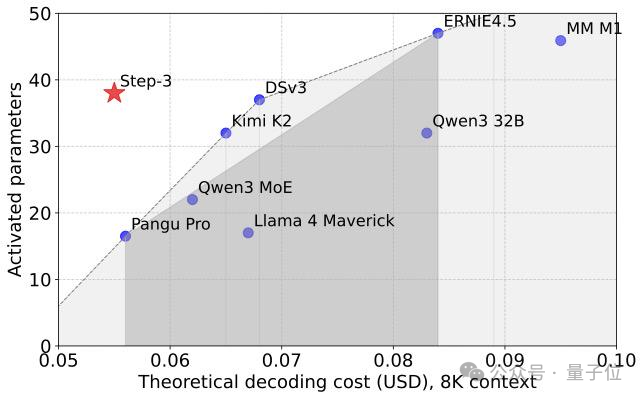
另外,Step-3采用了模型-Infra一体化设计,因此性价比也极高。
它有321B参数,但可以运行在8块48GB的GPU上,处理多达80万个token。
如果直观比较,Step-3在H20上的解码成本仅有DeepSeek-V3的30%。
Huggingface工程师评价,这种模型-Infra共同设计的理念,代表了一种前进方向。
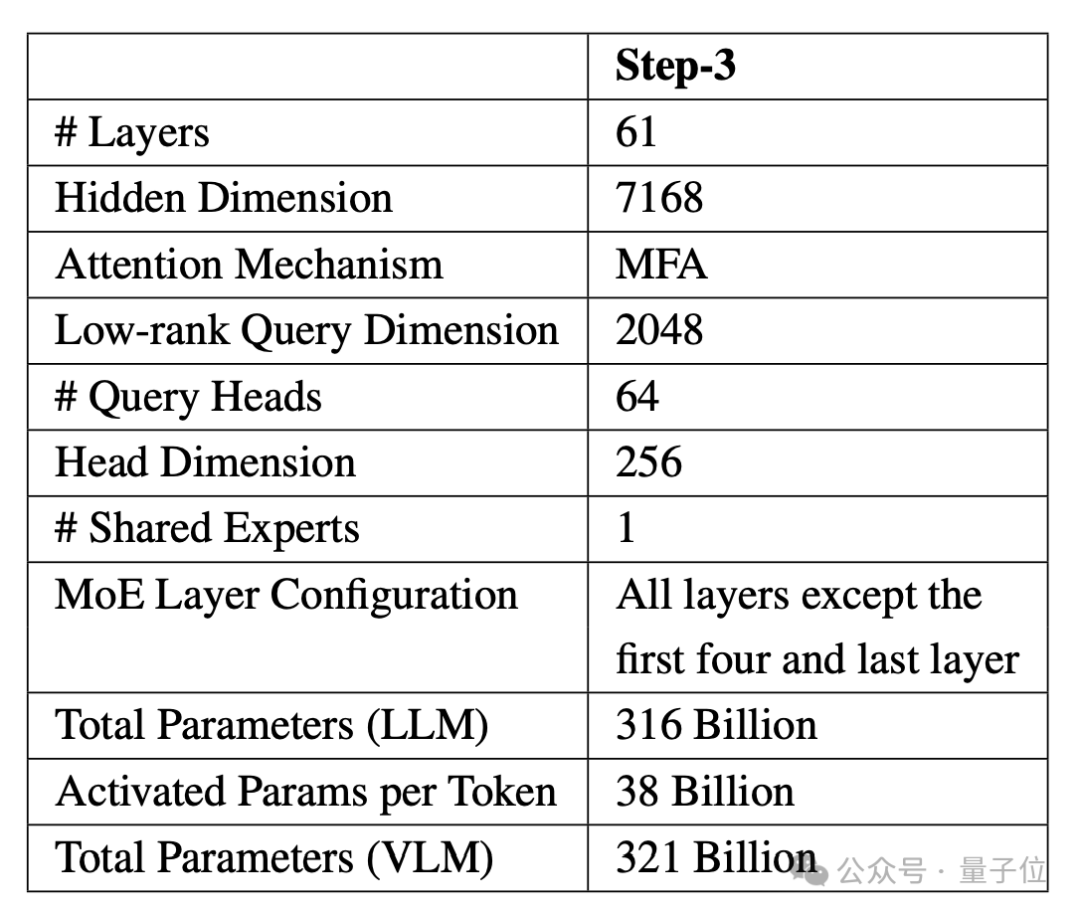
Step-3是一款MoE模型,包含48个专家,总参数量321B,其中316B为语言模型,5B为视觉编码器,激活参数量则为38B(3个专家)。
在MMMU、AIME25、LiveCodeBench等多个数学、代码及多模态榜单中,Step-3都达到了开源SOTA水平。
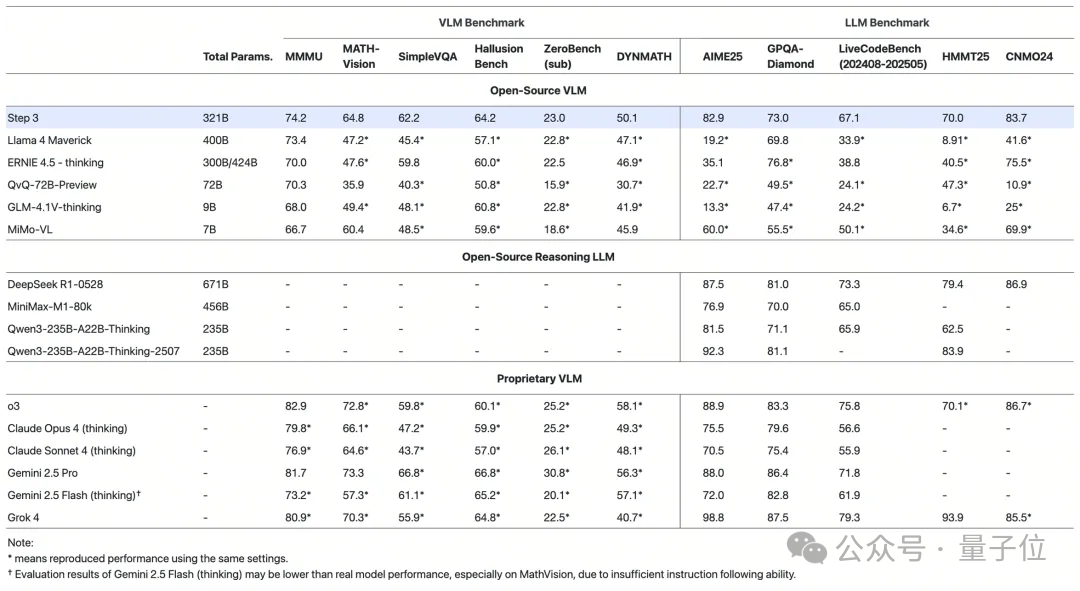
而且Step-3主打一个高效能,在4K上下文长度下,平均解码吞吐达到了3910token/GPU/秒,峰值4039 token/GPU/秒,比DeepSeek-V3的峰值高74%。
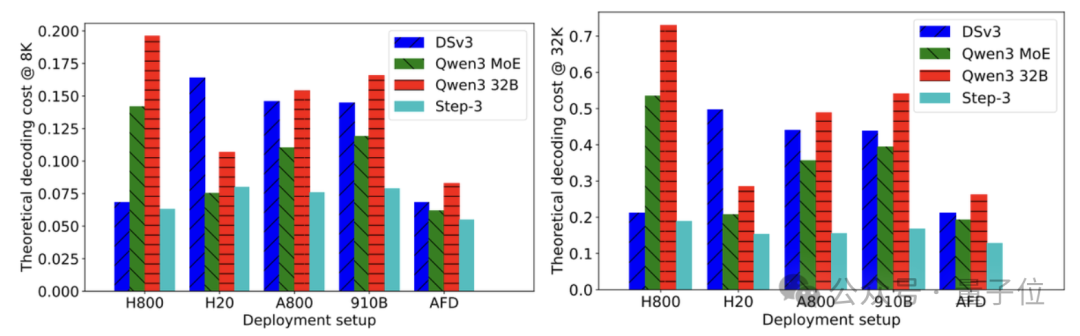
成本方面,Step-3使用H20+H800的异构组合,8K长度下每百万Token成本为0.055美元,合人民币不到4毛钱。
相比于只用H800的DeepSeek-V3,Step-3激活参数量更高,但成本只有V3的80%。
如果对比采用同样异构组合的Qwen MoE,Step-3的成本也要少将近12%。
如果不使用异构,Step-3在各个芯片上的成本,也低于DeepSeek-V3和Qwen。
例如在32K长度下,H20计算卡上,Step-3的解码成本只有V3的30%
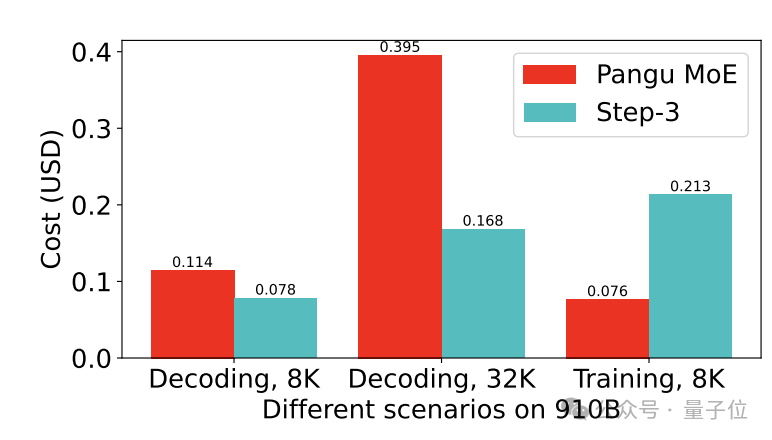
特别值得一提的是,在昇腾910B上,Step-3的解码成本甚至比华为自家的盘古大模型还要低。
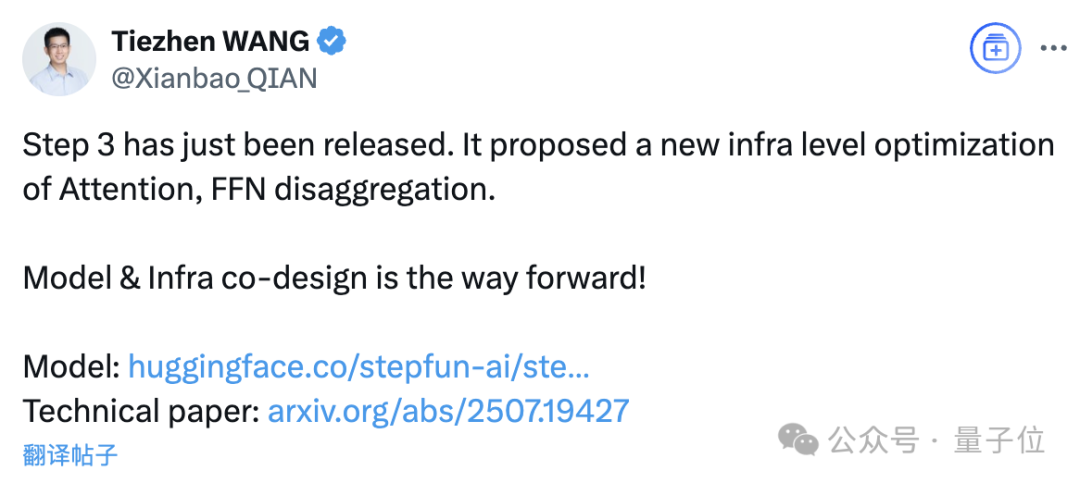
之所以能实现如此高的性价比,关键就在于Step-3采用了模型-Infra协同设计。
Step-3通过“模型—系统”一体化思路,把注意力、前馈网络和集群调度当作同一个优化对象,而不是单独微调某个算子。
核心中的核心是阶跃自研的MFA(Multi-Matrix Factorization Attention,多矩阵因子分解)注意力机制。
MFA在Query-Key路径上进行低秩分解,并让多个查询头共享同一组Key/Value表示,从根源上压缩 KV 缓存和乘加量。
技术报告显示,Step-3的KV缓存大小小于DeepSeek-V3,使得Step-3更适用于长上下文场景。
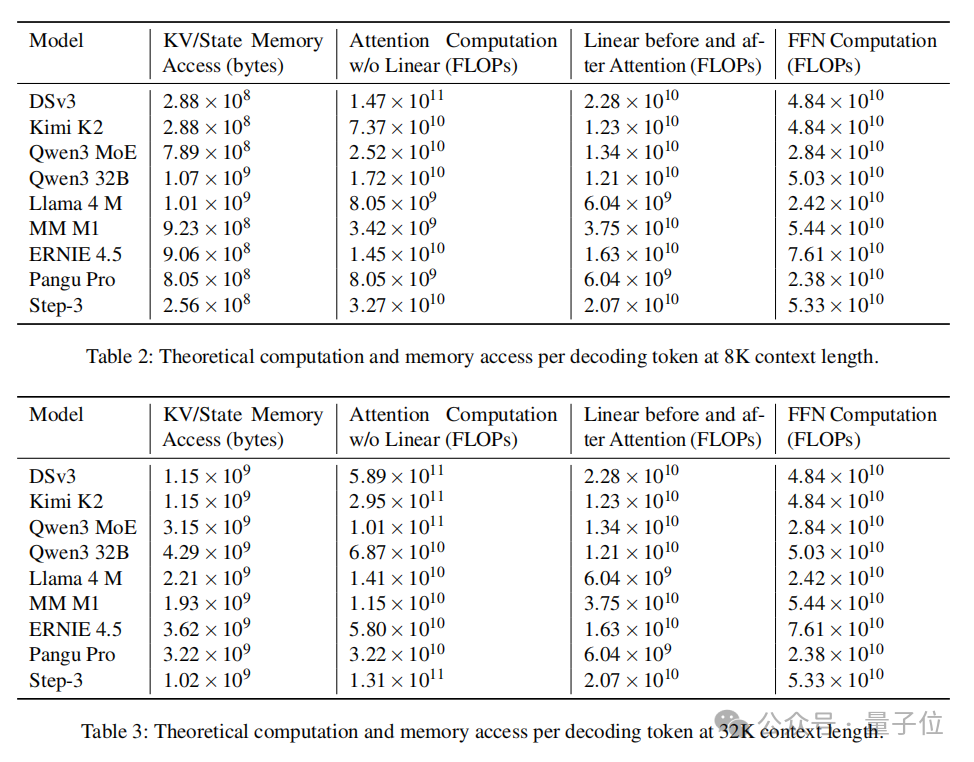
并且与传统稀疏或线性注意力不同,MFA还特地把算力-带宽比调到刚好略低于主流GPU的屋脊线,让同一套权重在高带宽卡和算力卡上都能维持高利用率。
系统层面,阶跃团队提出了AFD(Attention-FFN Disaggregation)机制。
传统情况下,模型关于Attention和FNN的推理计算任务,会同时交给同一组GPU同时处理,常常导致资源浪费。
AFD则把注意力和 FFN 分拆到各自最擅长的GPU群组,通过专门的三阶段流水线把隐藏态在两端之间“穿针引线”。
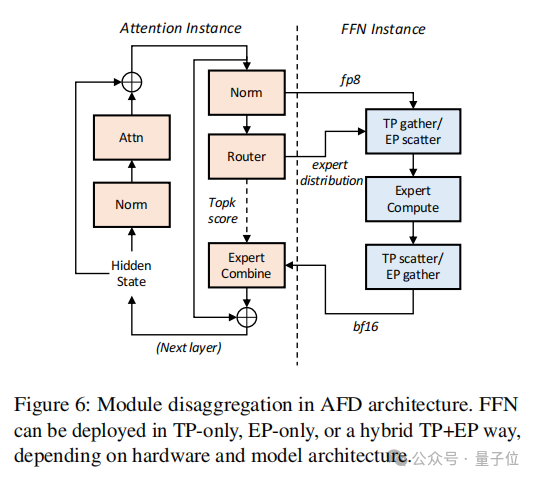
这样一来,每类算子都能选用最合拍的硬件和并行策略,同时流水线把通信延迟掩藏在计算之下,实现小规模集群就能跑满卡的解码吞吐。
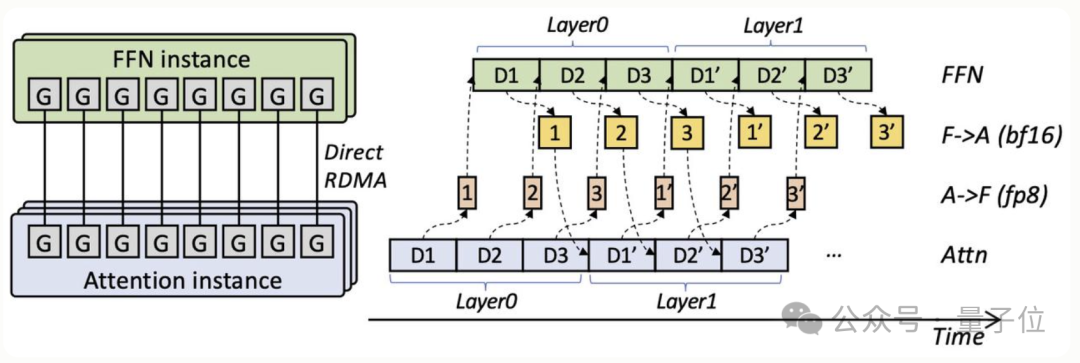
为支撑这一细粒度拆分,阶跃团队编写了StepMesh通信库,通过GPUDirect RDMA实现,SM占用为0,可在子毫秒时间内完成双向流式传输。
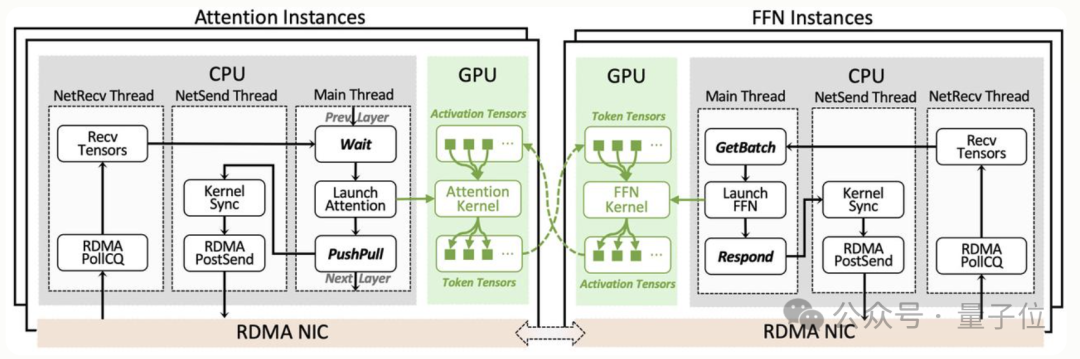
并且StepMesh库已随模型一同开源,提供可跨硬件的标准部署接口。
Hugging Face模型榜单,已经被中国开源模型占据主导,前十名中有8个模型全都来自中国。
其中第一名是智谱AI的GLM-4.5,第二名是腾讯推出的混元世界模型,4-6名为不同版本的Qwen。
之后的国产模型包括智谱GLM-4.5的Air版本,以及同一团队的Wan2.2视频生成模型,第十名则是上海AI Lab的Intern-S1。
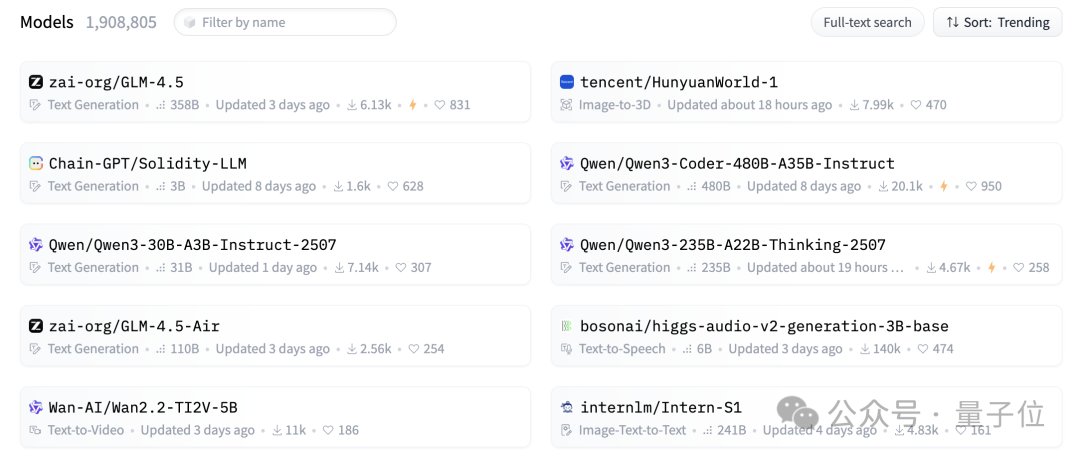
Kimi-K2则位列第十一,之前也曾进入过前十,这次的Step-3也位列第一页。
此外,第一页中还能看到字节Seed、昆仑万维、上交大PowerInfer等中国团队研发的模型。
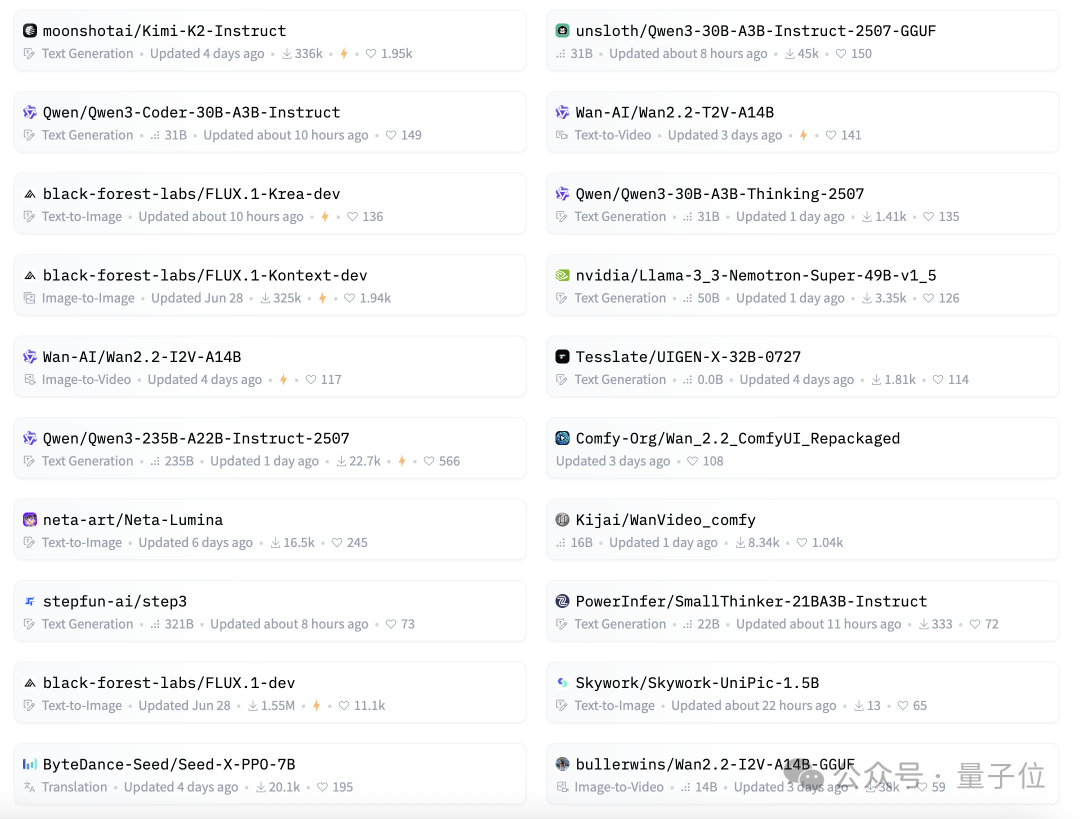
并且这些厂商都选择了把自家的王牌模型直接开源,而不是发布新一代才开源上一代。
在开源世界,国产模型已成为当之无愧的领军者。
Github:
https://github.com/stepfun-ai/Step3
Hugging Face:
https://huggingface.co/stepfun-ai/step3
魔搭ModelScope:
https://www.modelscope.cn/models/stepfun-ai/step3
https://www.modelscope.cn/models/stepfun-ai/step3-fp8
技术blog:
https://www.stepfun.com/research/zh/step3
StepMesh开源地址:
https://github.com/stepfun-ai/StepMesh
文章来自于微信公众号“量子位”,作者是“克雷西”。



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
