
0员工、月烧120万美元账单,AI初创公司Polsia被中国开源模型救了
0员工、月烧120万美元账单,AI初创公司Polsia被中国开源模型救了AI账单却差点让他破产。
来自主题: AI资讯
7585 点击 2026-07-28 15:35
 搜索
搜索
AI账单却差点让他破产。

就在刚刚,全球首个3万亿参数级开源模型Kimi K3正式开源!https://github.com/MoonshotAI/Kimi-K3/tree/main。Moonshot AI宣布,发布Kimi K3的模型权重、技术报告,并开源支撑Kimi K3模型训练的关键Infra技术:MoonEP、FlashKDA和AgentEnv。

刚刚,英伟达创始人黄仁勋发出了自己人生第一条推特:在老黄的第一篇帖子中,他分享了一封英伟达签署的信函《开放权重与美国 AI 领导力》,阐述为什么开源模型很重要。他表示,人工智能将改变每个行业,赋能每个公司,并由每个国家构建。开源模型加强安全性和网络安全,加速创新和传播,并实现主权。

最近硅谷有点魔幻。一边被中国开源模型吓得不轻,专门造了个词叫「Kimi panic」;另一边,美国最大的模型托管平台刚被自家模型攻击,救场的偏偏又是一个中国开源模型。就在这个节骨眼上,老黄又整活了。
这家公司是Fireworks AI,按现在流行的话说,Fireworks AI是一家Token工厂。既不训练前沿大模型,也不做面向消费者的AI应用,只做推理,帮企业把开源模型微调好、托管好,然后按调用量收钱。今年GTC大会上,黄仁勋和Lin Qiao有场对谈,老黄直言,“In a lot of ways, you're the TSMC of AI factories.”

这是今天 AI 圈最大的瓜。 OpenAI 的神秘模型,主动对开源平台 Hugging Face 发起了攻击。Hugging Face 随后追踪展开还击,用的是智谱的开源模型 GLM 5.2。闭源模型一举攻破开源社区,社区用开源模型自救,这离谱的剧情听起来都能拍一部电影了。

GPT-5.6-Sol 的攻防能力超越了 Claude Mythos 5!

7 月 16 日,月之暗面正式发布 Kimi K3:总参数量 2.8 万亿(2.8T),原生视觉理解,100 万 token 上下文,并且——开源权重。这是历史上第一个摸到 2.8 万亿参数量级的开源模型。前任"开源最大模型"的纪录保持者?也是它自己。
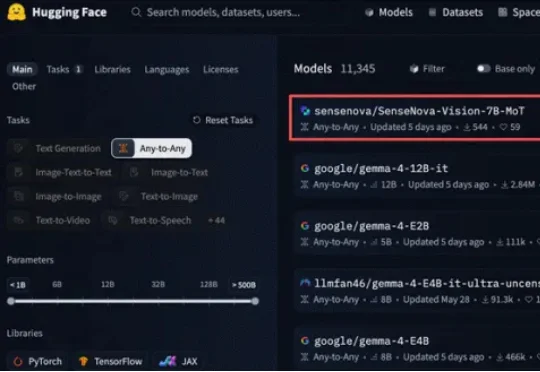
近日,商汤科技发布并全面开源日日新SenseNova-Vision理解生成统一视觉大模型,试图宣告视觉AI“缝合怪”时代的终结。截至当前,该模型综合得分登顶Hugging Face Any-to-Any Leaderboard,位列该全模态任意输入输出开源模型榜单全球第一。

2026 年 6 月,HuggingFace 上一个名为 Boogu-Image-0.1 的开源模型,在上传以后迅速引爆了 AI 圈。这款模型最引人注目的地方,在于它以区区 10B 的参数规模,就在多项关键能力上超过了很多参数量更大的模型。