# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近期,随着OpenAI-o1/o3和Deepseek-R1的成功,基于强化学习的微调方法(R1-Style)在AI领域引起广泛关注。这些方法在数学推理和代码智能方面展现出色表现,但在通用多模态数据上的应用研究仍有待深入。
DocTron团队提出的Chart-R1模型在这一背景下应运而生,针对图表这一信息密集型多模态数据类型,开发出一套思维链监督和强化的图表推理方法,通过逐步骤的思维链监督和数值敏感的强化学习微调实现复杂图表推理能力。图表分析不仅需要视觉理解,还需要进行多步骤的数值推理和关系分析,因此这项工作的重要性不言而喻。
DocTron是一个在通用视觉语言模型架构上实现结构化内容解析和理解的开源项目,而无需定制化的模块开发,覆盖通用文档、学科公式、图表代码等场景。
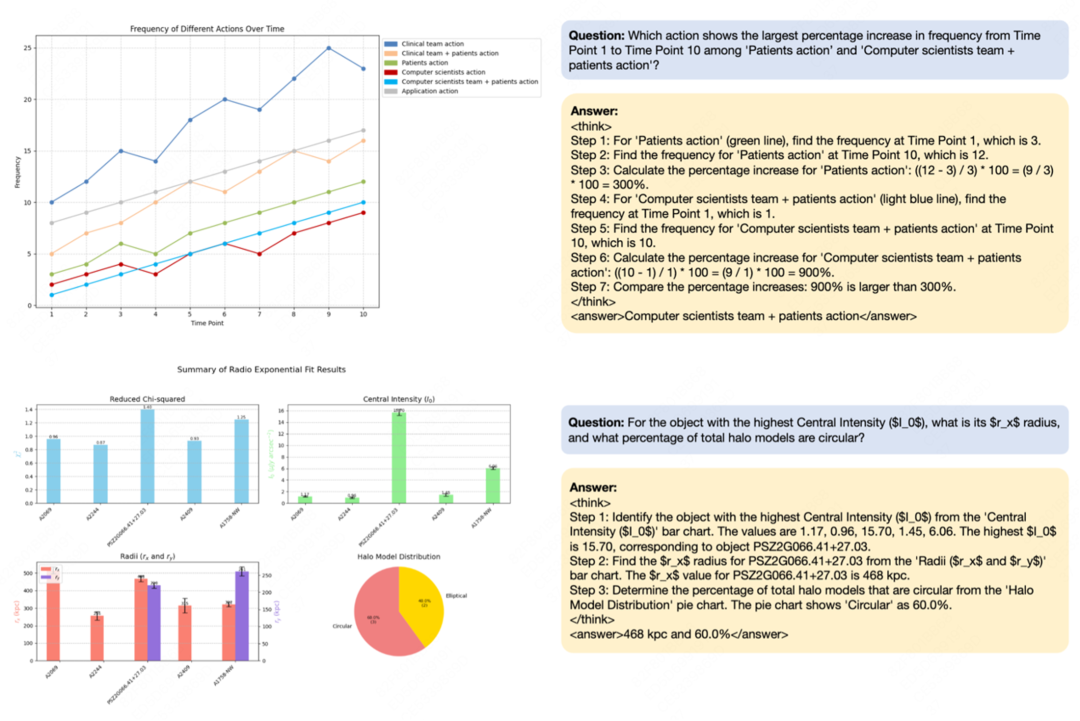
Chart-R1 的核心创新在于其两阶段训练策略和高质量数据合成方法:
1. 程序化数据合成技术:
研究团队开发了一种新颖的程序化数据合成技术,利用 LLM 生成图表绘制代码,并基于这些代码构建复杂问题、多步骤思维链推理过程和最终答案。
这种方法生成了覆盖单图表和多子图表的高质量推理数据,构建了包含 258k 多步推理样本的 ChartRQA 数据集。与现有方法相比,该技术避免了有损解析过程,确保了数据的多样性和真实性。
2. 两阶段训练策略:
这种两阶段策略的独特之处在于为两个阶段使用不同的数据集,避免了在强化学习过程中模型探索能力的受损。
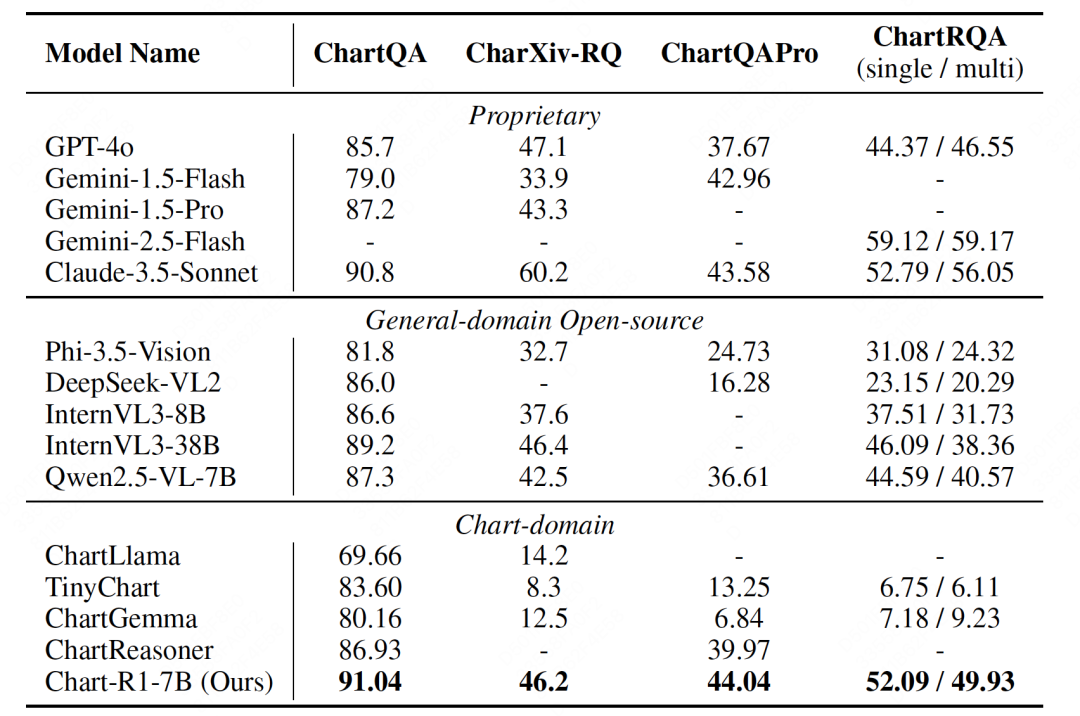
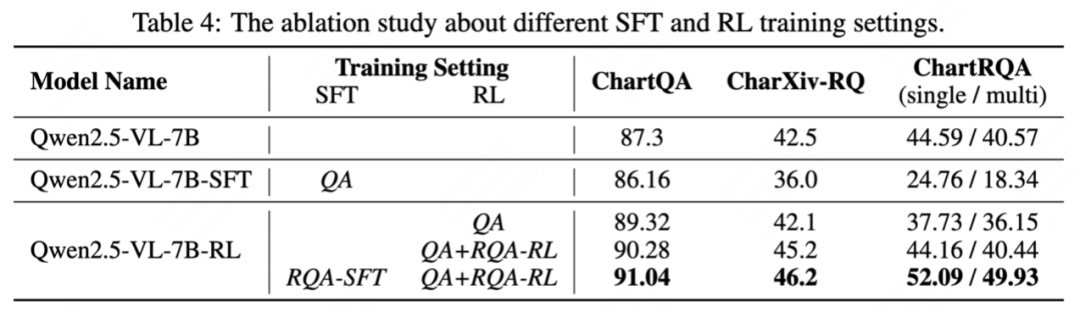
实验结果令人瞩目:Chart-R1 在各种公开基准测试和自建的 ChartRQA 数据集上表现卓越,不仅超越了现有的图表领域方法,甚至在多个任务上媲美 GPT-4o 和 Claude-3.5 等闭源大型模型。
在复杂图表推理任务上,现有视觉语言模型的性能大幅下降,而 Chart-R1 依然保持稳定的高水平表现,这充分证明了该方法在复杂推理任务上的优越性。
该研究不仅在技术上取得了突破,也为图表理解和推理领域提供了新的研究方向:
在实际应用方面,Chart-R1 可广泛应用于商业智能分析、科学研究数据解读、金融报告分析等需要深度图表理解的场景,大幅提升自动化分析效率。
Chart-R1 的成功表明,通过精心设计的训练策略和高质量数据,即使是参数规模相对较小的模型也能在特定领域达到与大型闭源模型相媲美的性能。这一研究为构建高效、专业的领域特定 AI 模型提供了宝贵经验,也为未来多模态推理研究指明了方向。
该工作不仅是对 R1-Style 方法在多模态领域有效性的验证,更是对如何构建高效专业领域模型的重要探索,值得学术界和产业界的高度关注。
文章来自于微信公众号“机器之心”。


【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
