# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
图像生成不光要好看,更要高效。
混元基础模型团队提出全新框架MixGRPO,该框架通过结合随机微分方程(SDE)和常微分方程(ODE),利用混合采样策略的灵活性,简化了MDP中的优化流程,从而提升了效率的同时还增强了性能。

基于MixGRPO,研究人员提出了一个更快的变体MixGRPO-Flash,在保持相近性能的同时进一步提升了训练效率。
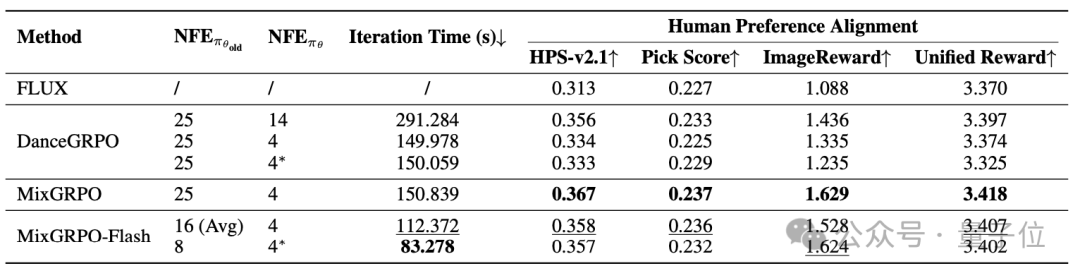
MixGRPO在人类偏好对齐的多个维度上均表现出显著提升,效果和效率均优于DanceGRPO,训练时间降低近50%。值得注意的是,MixGRPO-Flash可将训练时间进一步降低71%。
开源代码请参考文末链接。
近年来,文本到图像(Text-to-Image,T2I)任务的最新进展表明,通过在后训练阶段引入基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)策略以最大化奖励,流匹配模型的性能得到了显著提升。
具体而言,基于组相对策略优化(Group Relative Policy Optimization,GRPO)的方法近期被提出,能够实现与人类偏好的最佳对齐。
当前概率流模型中的GRPO方法,如Flow-GRPO和DanceGRPO,在每个去噪步骤中利用随机微分方程(Stochastic Differential Equations,SDE)采样引入图像生成的随机性,以解决RLHF中对随机探索的依赖。
它们将去噪过程建模为随机环境下的马尔可夫决策过程(MDP),并使用GRPO优化整个状态-动作序列。
然而,由于去噪迭代过程带来的巨大开销,这显著降低了训练速度。

虽然DanceGRPO提出了随机选择部分去噪步骤进行优化的方法,但研究团队在图1中的实证分析表明,随着所选子集规模的缩小,性能会出现显著下降。

△图1.不同优化去噪步骤数量下的性能对比

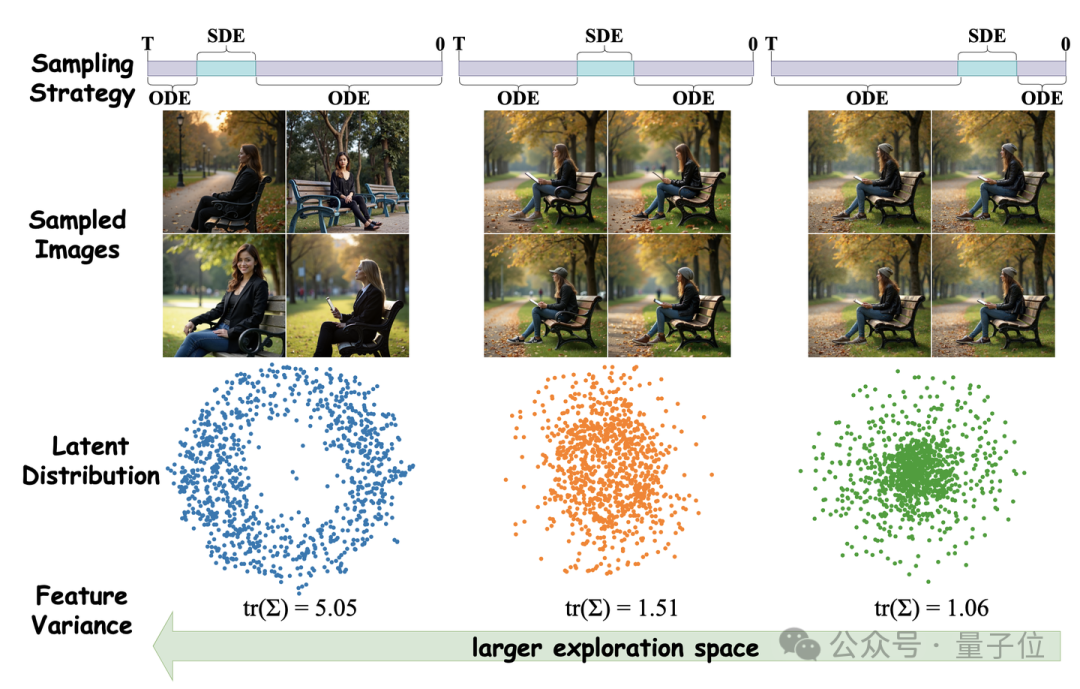
△图2.不同采样策略下采样图像的t-SNE可视化

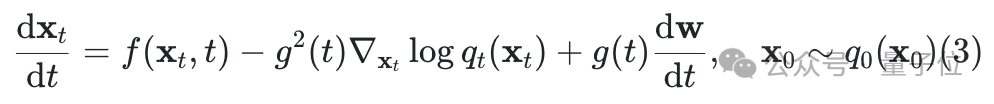
在MixGRPO中,研究团队将ODE和SDE混合用于采样,具体形式如下:
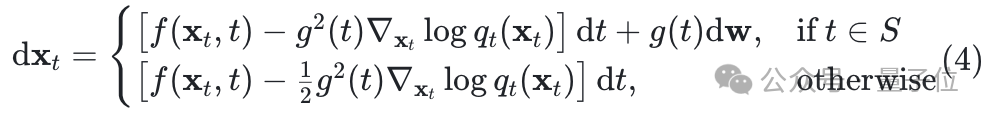





△算法1.MixGRPO的训练过程
限制在滑动窗口内使用SDE采样,不仅保证了生成图像的多样性,还使模型能够集中精力优化该窗口内的流动。沿着去噪方向的移动反映了概率流从强到弱的随机性,如图2所示。
这本质上是一种贪心策略,类似于强化学习中为处理奖励而分配折扣因子的做法,即在早期过程给予来自更大搜索空间的奖励更高的权重。
研究团队发现,即使滑动窗口保持不动(Frozen),仅优化较早的时间步,MixGRPO依然能够取得良好效果,尤其是在ImageReward和UnifiedReward指标上表现突出。

MixGRPO在滑动窗口内采用SDE采样,窗口外则采用ODE采样,从而允许使用高阶ODE求解器加速GRPO训练时的采样过程。
利用ODE采样的时间步被划分为滑动窗口之前和之后两部分。
滑动窗口之后的时间步仅影响奖励计算,而窗口之前的时间步既影响奖励,也会对策略比率计算中的累积误差产生贡献。
因此,研究团队重点关注滑动窗口之后时间步的加速。
gao2025diffusionmeetsflow已证明流匹配模型(FM)的ODE采样与DDIM等价,且上述过程也表明扩散概率模型(DPM)与FM在去噪过程中共享相同的ODE形式。
因此,专为DPM采样加速设计的高阶ODE求解器,如DPM-Solver系列、UniPC,同样适用于FM。
研究团队已将DPM-Solver++重新形式化,以便在FM框架中应用于 ODE 采样加速,详细推导见附录B。

采样的加速,这本质上是在计算开销与性能之间的权衡。
过度加速会导致时间步数减少,必然引起图像生成质量下降,进而在奖励计算中积累误差。
实践中研究团队发现,二阶DPM-Solver++足以显著加速,同时保证生成图像与人类偏好高度一致。
最终,他们采用了渐进式和冻结式滑动窗口策略,提出了MixGRPO-Flash和MixGRPO-Flash*。算法的详细描述见附录C。这些方法相比MixGRPO实现了更大程度的加速,同时在性能上也优于DanceGRPO。
数据集
研究团队使用HPDv2 数据集中提供的提示词进行实验,该数据集是 HPS-v2 基准的官方数据集。
训练集包含103,700条提示词;实际上,MixGRPO 在仅使用9,600条提示词训练一个epoch后,就已取得良好的人类偏好对齐效果。
测试集包含400条提示词。提示词风格多样,涵盖四种类型:“动画”(Animation)、“概念艺术”(Concept Art)、“绘画”(Painting)和“照片”(Photo)。
模型
继承自DanceGRPO,研究团队采用基于流匹配的先进文本生成图像模型 FLUX.1 Dev作为基础模型。
开销评估
在评估计算开销时,研究团队采用了两个指标:函数调用次数(NFE)和训练过程中每次迭代的时间消耗。

此外,GRPO每次迭代的平均训练时间能够更准确地反映加速效果。
表现评估
研究团队使用四个奖励模型作为训练中的奖励指导及性能评估指标,分别是HPS-v2.1、Pick Score、ImageReward和Unified Reward。
这些指标均基于人类偏好,但侧重点不同,例如ImageReward强调图文对齐和图像保真度,而Unified Reward更关注语义层面。
DanceGRPO也证明了多奖励模型的使用能带来更优效果。为验证MixGRPO的鲁棒性,研究团队同样遵循DanceGRPO,进行了仅使用HPS-v2.1单一奖励以及结合HPS-v2.1与CLIP Score的多奖励对比实验。

在训练设置上,所有实验均在32块Nvidia GPU上进行,批量大小为1,最大训练迭代次数为300次。
优化器采用AdamW(loshchilov2017decoupled),学习率设为1e-5,权重衰减系数为0.0001。训练过程中使用混合精度,采用bfloat16(bf16)格式,而主权重参数保持全精度(fp32)。
在主实验中,四个基于人类偏好的奖励模型按照优势函数(advantages)进行了加权聚合,具体算法见算法1。
研究啊团队对MixGRPO与DanceGRPO的开销和性能进行了对比评估,结果汇总于表1。
△表1.计算开销与性能的对比结果显示

对于MixGRPO-Flash,他们评估了渐进式(progressive)和冻结式(frozen)两种策略,并且为了公平起见,也对DanceGRPO采用了冻结式策略。
研究团队选取了多个场景提示语,对FLUX.1 Dev、官方配置的DanceGRPO以及MixGRPO的生成结果进行了可视化展示,见图3。

△图3.定性比较
结果表明,MixGRPO在语义表达、美学效果及文本-图像对齐度方面均取得了最佳表现。


△图4.不同训练时采样步数的定性比较
沿用DanceGRPO的实验设计,研究团队还在HPDv2数据集上,分别使用单一奖励模型和双奖励模型进行了训练与评估。
结果(见表2)显示,无论是单奖励还是多奖励,MixGRPO 在域内和域外奖励指标上均取得了最佳性能。更多可视化结果详见附录D。
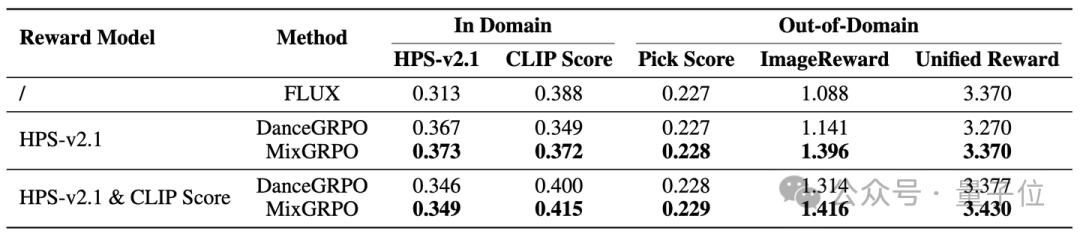
△表2.域内与域外奖励指标的比较结果
滑动窗口超参数

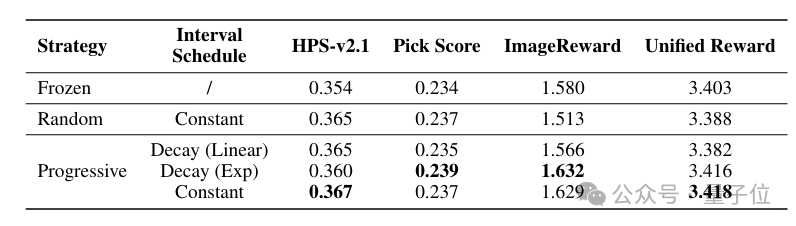
△表3.移动策略的对比

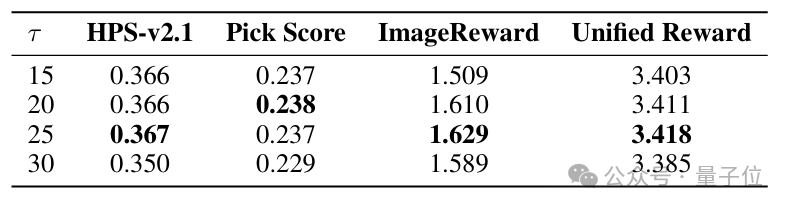
△表4.移动间隔的对比

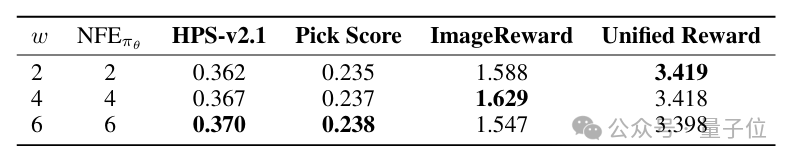
△表5.窗口大小对比

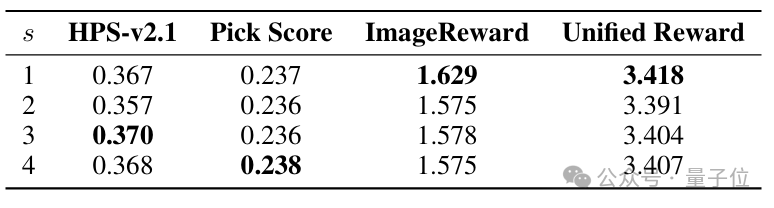
△表6.窗口步长对比
高阶ODE求解器
MixGRPO通过结合随机微分方程(SDE)和常微分方程(ODE)的采样方法,实现了利用高阶ODE求解器加速ODE采样的可能性。
研究团队首先针对求解器的阶数进行了消融实验,使用DPM-Solver++作为高阶求解器,并采用progressive策略。结果如表7所示,表明二阶中点法是最优设置。
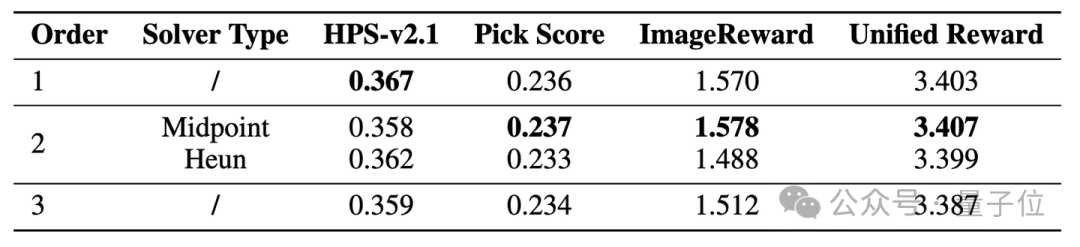
△表7.不同阶数求解器的性能比较
随后,研究团队比较了两种加速方案:一种是采用progressive窗口移动策略的MixGRPO-Flash,另一种是采用frozen移动策略的MixGRPO-Flash*。
两者均通过减少窗口后端的ODE采样步数,在开销与性能之间取得了平衡。
然而,实际应用中,MixGRPO-Flash需要窗口在整个训练过程中持续移动,导致被加速的ODE部分较短。
因此,平均来看,MixGRPO-Flash的加速效果不及MixGRPO-Flash*明显。
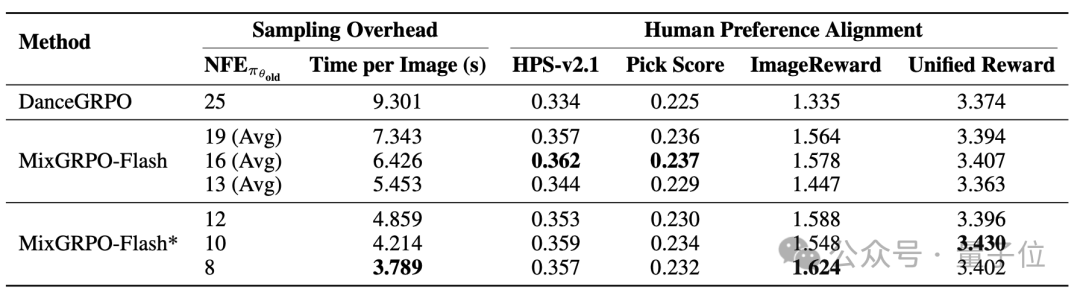
△表8.MixGRPO-Flash中progressive和frozen策略的比较
由于现有基于流匹配的GRPO面临采样效率低和训练缓慢等挑战,研究团队提出了MixGRPO,一种结合了SDE和ODE采样的新型训练框架。
该混合方法使得优化能够聚焦于SDE采样流部分,降低了复杂度的同时保证了奖励计算的准确性。
受强化学习中衰减因子的启发,研究团队引入了滑动窗口策略来调度优化的去噪步骤。实验结果验证了所提方法在单奖励和多奖励设置下的有效性。
此外,MixGRPO解耦了去噪阶段的优化与奖励计算,使得后者能够通过高阶求解器实现加速。
基于MixGRPO,研究团队进一步提出了MixGRPO-Flash,在开销与性能之间实现了平衡。
最后,他们希望MixGRPO能够激发图像生成后训练领域的深入研究,进一步推动通用人工智能的发展。
项目主页:https://tulvgengenr.github.io/MixGRPO-Project-Page/
论文链接:https://arxiv.org/abs/2507.21802
代码链接:https://github.com/Tencent-Hunyuan/MixGRPO
文章来自于微信公众号“量子位”。


【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
