# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

“我始终相信,技术世界需要理想主义。”
在 AI 圈,如果你关注基础设施、尤其是向量数据库,那你大概率听说过 Zilliz。2023 年,黄仁勋在 GTC 大会上的一次点名推荐,让这家公司进入大众视野。但真正吸引我注意的,是 Zilliz 创始人星爵年初的一篇访谈文章,标题叫做:《我们没有对手》 ——在商界如此直白地表达自信非常罕见,这让我确信他对自己做的事有极强的信念和实际领先优势。因此,深入了解后,我发现 Zilliz 不仅技术硬核,故事也很丰富。
这期播客我们特地在上海的 AI Hacker House 线下录制,也是十字路口第一次尝试视频版内容。完整视频也会同步发布在小红书、B站、视频号等平台,欢迎搜索收看。
👦🏻 Koji
你的毕业院校是什么?
👨🏻 星爵
华中科技大学。
👦🏻 Koji
Zilliz 创业几年了?
👨🏻 星爵
到现在为止八年
👦🏻 Koji
创业前你做过什么?
👨🏻 星爵
数据库工程师。
👦🏻 Koji
你的 MBTI 和星座?
👨🏻 星爵
ENTP、天蝎座。
👦🏻 Koji
一句话介绍公司和产品?
👨🏻 星爵
我们是 AI 时代的数据 Infra 公司,专注于非结构化数据平台的建设。
👦🏻 Koji
收入和利润情况?
👨🏻 星爵
不方便透露具体数字,但过去 12 个月营收增长了 3.3 倍。
👦🏻 Koji
目前团队的规模?
👨🏻 星爵
全球大概有 130 人。
👦🏻 Koji
黄仁勋在 GTC 2023 大会上提到你们时,你当时的心情是?
👨🏻 星爵
我觉得这是「向量数据库」这个品类的高光时刻。2018 年我们刚开始做时,几乎没人知道这个赛道,连我们自己都在怀疑这个市场是否存在。但到 2023 年,整个行业终于认识到,AI 尤其是 GenAI,离不开向量数据库。

👦🏻 Koji
对你来说,那是一个命运转折点吗?
👨🏻 星爵
其实不是。做 Infra 这条路很苦。跟算法突破不同,我们几乎不会因为某个灵光一闪就超越对手、赢得更多客户。数据库属于重投入、慢产出的领域,靠的是长期打磨和产品复利。
👦🏻 Koji
从 GTC 2023 到现在,GenAI 变化巨大。有哪些趋势至今依然没变?又有哪些发生了明显转变?”
👨🏻 星爵
不变的是 AI 创新速度越来越快,对数据平台的需求也持续上升。但过程中也有波折。2023年很多公司跟风创业,拿到融资。但到 2024 年的 10、11 月份,很多项目并没有找到真正的 PMF,产品也比较同质化。很多公司拿不到下一轮融资,集中性的倒闭了。
👦🏻 Koji
我们很多听众未必有技术背景。能否先给大家科普一下什么是向量数据库?再介绍一下 Zilliz 和 Milvus 这个产品?
👨🏻 星爵
数据库的本质,是用系统化的方式存储和管理大量数据。几千年前人类用文字记录信息时,图书馆就是数据管理工具。
到了 IT 时代,数据被数字化,关系型数据库随之诞生,广泛应用于金融、电商、ERP 等领域。
而在 AI 时代,计算机开始处理人类自然生成的信息——语言、图像、视频这些非结构化数据。而深度学习的出现,让这些内容可以转化为“特征向量”(embedding)。AI 的迅猛发展给这种数据结构也带来了爆发式增长。
有了这么多的特征向量,AI 开发者需要新的数据库来存储和管理数据。这就是向量数据库的用途。它能用自然语言和语义方式,高效检索非结构化数据,如文本、图片和视频。
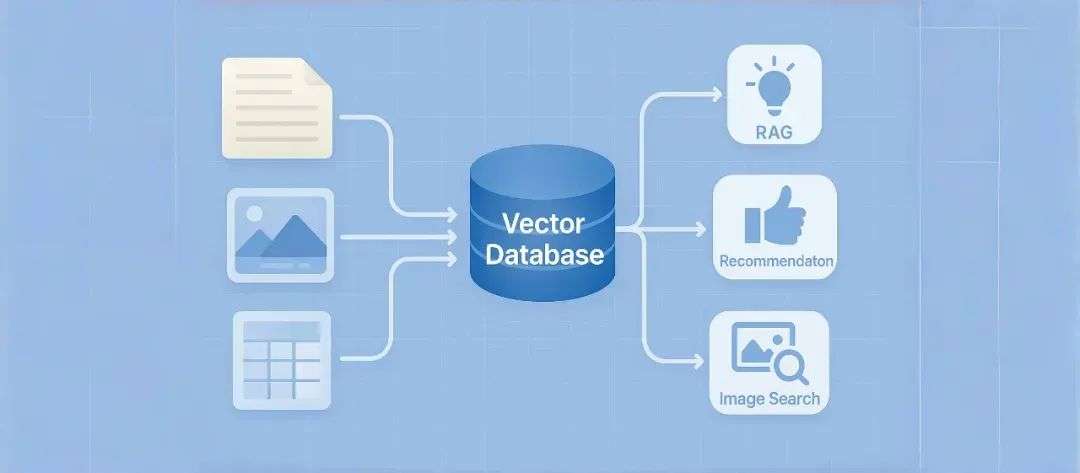
👦🏻 Koji
所以向量数据库早于生成式 AI,也不仅适用于生成式 AI。你八年前创业时,是基于怎样的判断?
👨🏻 星爵
特征向量其实不是一个新概念,虽然在最近这一波深度学习驱动的 AI 革命中变得炙手可热,把我们推到了风口浪尖。早在七八年前,向量数据库就在图像识别、自然语言处理等 AI 场景中广泛使用。作为神经网络的基本“语言”,embedding 是网络内部、网络之间、以及与外部系统交流时的核心数据结构。因此从 2018 年起,我们已经服务了很多上一代的 AI 公司。那时大家主要是做卷积神经网络 (CNN)和 循环神经网络 (RNN)。

👦🏻 Koji
过去三年,从生成式 AI 的兴起到现在,向量数据库这个领域发生了哪些变化?
👨🏻 星爵
变化很大,主要有三个方面。
首先是数据量大幅增长。五六年前,几千万、上亿条数据就算很大了,现在已经扩展到百亿甚至千亿级别。
其次,应用场景不断拓展。除了大模型知识库的检索,向量数据库也被用于模型训练阶段的数据清洗,比如自动驾驶中的多模态数据处理、电商中的推荐系统、风控与欺诈检测,甚至还用于生物医药领域分析蛋白质结构和基因序列。越来越多算法开始将各类数据转化为特征向量,用向量方式推进新药研发与筛选。随着数据量和使用场景的爆发,
第三个明显趋势是,用户越来越关注如何降低向量数据库的使用成本。
👦🏻 Koji
接下来你们的重点是什么?是提升规模、降低成本,还是有别的目标?
👨🏻 星爵
我们希望帮用户处理更大规模的数据。
过去向量数据库主要用于实时查询,对延迟和准确性要求极高。但现在,越来越多的场景需要对海量数据进行离线分析。
因此我们正在从传统的向量数据库,拓展为结合 vector lake 的混合架构。也就是在支持在线查询的同时,构建一个能够处理非结构化数据的“数据湖”,专门面向离线任务。
当数据量达到几百亿、甚至上千亿级别时,实时逐条查询不仅成本高,技术挑战也大。这种情况下,更适合通过离线方式定期处理全量数据,任务周期可以是按天、按周,甚至按月。

👦🏻 Koji
你刚才提到数据规模变得越来越大,我也很好奇,目前你们见到最大规模的数据应用是在哪家公司、做什么产品?为什么需要这么大的数据量?
👨🏻 星爵
我们有一个客户是全球最大的 IT 公司之一,他们的目标是用向量数据库对整个互联网进行语义检索。也就是说,要把互联网上的每一个网页都转化为向量。
👦🏻 Koji
他们这样做的目的是什么?最终是提供什么服务?
👨🏻 星爵
最终是为了做 AI 搜索。
👦🏻 Koji
像是类似 博查 AI 或早期的 Bing Search API?
👨🏻 星爵
对,现在很多大语言模型的查询,都会配合实时搜索。如果你想获得最精确的结果,最好就是能检索全网的信息。
👦🏻 Koji
所以这类客户对于数据量的需求几乎是无限的。
👨🏻 星爵
对,而且数据还在持续增长。AI 搜索和 RAG 本质上用的是类似的技术。RAG 通常是私有的知识库,而 AI 搜索是把整个互联网变成公共知识库。
RAG 的数据量虽然单库不大,但客户数量庞大也是一个挑战。比如一个企业服务 10 万个客户,每个客户有 1 万条知识,就是 10 亿条数据。
这类场景的难点不在数据总量,而在于数据管理。系统必须支持大规模多租户的隔离与安全,确保每个客户的数据互不干扰。
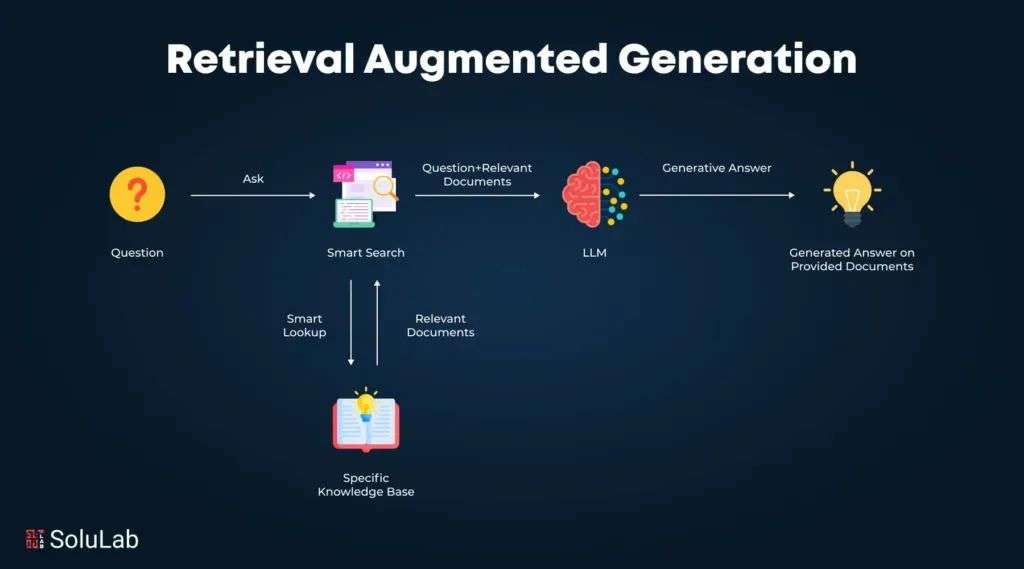
👦🏻 Koji
我看到一篇硅星人的报道,标题叫《我们没有对手》。这句话是你说的。当时是在什么样的语境下提出的?因为我认为其实这个领域的竞争还挺激烈的。
👨🏻 星爵
这句话指的是「我们曾经没有对手」。2018 年我们刚做向量数据库时,全球几乎没有同行,真的像走在一片荒漠里。如果长期没有对手,反而说明你可能走错方向了。
但过去几年,越来越多公司进入这个赛道,我们看到向量数据库成了热门方向。其实我们心里挺喜悦的。

👦🏻 Koji
我感觉向量数据库的竞争其实很激烈,比如像 Pinecone 这样的公司。你们选择了开源路线,而他们是闭源,目前估值也到了 7.5 亿美元。你怎么看这种差异?
👨🏻 星爵
我们两家公司确实竞争很激烈。他们估值是 7.5 亿美元,我们是 6 亿。最大的区别就在于开源和闭源。如果让我再选一次,我还是会坚定选择开源。开源能推动知识传播和技术交流,也能加快产品迭代。
👦🏻 Koji
所以你觉得你们相较 Pinecone 最大的竞争优势就在于开源?
👨🏻 星爵
开源肯定是我们长期的核心优势。如果只谈产品和技术,我们在性能上比 Pinecone 快 3 到 5 倍。但我并不想把这当作主要差异,因为技术优势是会逐渐趋同的。
我们现在在技术和产品上的领先并不是偶然。正因为开源,我们才能吸引全球更多开发者使用、参与,他们会不断反馈真实需求,帮助我们快速迭代产品,避免走弯路。
未来的竞争,不取决于今天的起点,而是取决于我们是否能持续保持这种开放生态,让产品在真实场景中不断进化。这是我们面对闭源公司的最大底气。
👦🏻 Koji
你刚才提到 Pinecone 和 Zilliz 咬得很紧。其实在开源赛道上你们也有一些其他的竞争者,比如 Qdrant、Faiss、Weaviate。从你的角度看,他们有对你们造成冲击吗?
👨🏻 星爵
Faiss 是一个非常重要的向量检索算法集,我们 Zilliz 是除了 Facebook 之外最大的外部贡献者。我们在 Milvus 项目中也大量使用了 Faiss 作为底层算法基础,所以它更像是我们生态的一部分,而不是直接竞品。
相比其他的开源项目,Milvus 的优点是 TCO 更优。Milvus 的性能强、可扩展性高,意味着用户部署时对硬件的要求更低,用更少的资源就能支持大规模场景。
其次是更低的开发成本。过去七八年,我们与全球主流的 AI 框架和大语言模型做了深入集成,支持丰富的数据类型和查询方式。Milvus 已不只是做向量检索,还能支持标量过滤、混合查询、聚类、分类、排序等复杂任务,开发者的使用门槛也大幅降低。
最后是更低的运维成本。我们提供完整的运维工具链,包括可视化界面、权限系统整合、与企业内部 access control 的打通等,帮助用户降低了维护成本。
👦🏻 Koji
我理解还有两个潜在竞争方向。一是 MongoDB、Postgres 等传统数据库也在加向量检索功能;二是像 LangChain、LlamaIndex 这样的框架,可能会把向量数据库整合进自己的体系。你会担心独立数据库公司未来被吞并吗?
👨🏻 星爵
先说第一种情况,传统数据库加向量模块,在数据量小、场景简单时是能用的。但随着规模扩大、场景变复杂,用户还是会迁移到专用的向量数据库上来。这就好比“增程式电车”,和真正的电车是两种思路,它终究只是过渡方案,没法和原生架构相比。
第二,像 LangChain、LlamaIndex 属于开发框架,而数据库属于底层基础设施。他们从第一天起就和我们不是同一类产品,所以根本谈不上竞争或替代。
我认为 AI 时代的开发框架只会越来越多样化,但数据库依然是核心基础层,不会被上层框架“包住”或“吞并”。就像 Web 时代的架构,应用层、中间层和数据库层是清晰分工的。我们和 LangChain、LlamaIndex 实际上是战略合作伙伴,在生态上也会配合。
👦🏻 Koji
在刚才提到的所有竞争者中,有没有哪个是你最担心的?
👨🏻 星爵
我更在意我们自己。真正担心的不是对手做了什么,而是我们能不能以更快的速度持续创新。
👦🏻 Koji
我想到 Databricks 的联合创始人 Reynold Xin 曾说,如果可以重来一次,他会选择闭源。那如果让你重新来过,你还会选择开源吗?
👨🏻 星爵
我还是会选开源。
没有开源,就没有今天的 Databricks。他们靠开源社区建立起早期影响力,拿到了融资和第一批用户。放到今天来看,我反而觉得 Databricks 和 Snowflake 的竞争中,正是因为有庞大的开发者基础,Databricks 的生态潜力可能会更大。
👦🏻 Koji
那你觉得开源对 Databricks 和 Zilliz 来说,是一种捷径,还是一个不得不做的选择?
👨🏻 星爵
它绝对不是捷径。开源反而需要更多耐心。但它能成为你的护城河,帮助你赢得开发者的心智。你要让他们低成本地把你的工具接入到工作流里,愿意学习你的产品,持续用下去。开源产品可以直接在 GitHub 上下载、查看实现细节。这种开放性天然更容易获得用户好感。
👦🏻 Koji
但像 Reynold Xin 就觉得开源让他们经历了“二次创业”:先做开源,再去找闭源的 PMF,好像要连跨两座山。你怎么看这种说法?
👨🏻 星爵
Reynold 所说的“跨两座山”,其实也是 Databricks 今天成功的重要壁垒。虽然这条路很难,但他们走通了,竞争对手要复制也同样不容易。
传统的 open core 模式,是开源一个核心,商业化版本在此基础上加企业服务。优点是研发一次就够了,但问题是很难说服用户付费:开源都能用,为什么还要买商业版?
Databricks 采用了 dual core 模式:一个开源核心,一个闭源核心。两者在接口和用户体验上几乎一致,可以无缝迁移,但底层实现完全重写——开源用 Java,闭源用 C++,商业引擎是独立设计的。这种方式兼顾了用户易用性和商业闭环,是非常巧妙的架构设计。
👦🏻 Koji
所以 Databricks 是完全两套人马写两套系统?
👨🏻 星爵
对。他们必须保证商业化的核心在功能、性能、设计上都优于开源版本。这样才能说服用户为闭源产品买单——体验一样,迁移成本几乎为零,但性能更好、效果更强,自然愿意付费。
但这条路也很难。本质上是同时做两个产品:一个面向开源社区,一个闭源产品面向商业客户。商业版不仅要兼容开源版,还要持续领先。
而且这种领先是动态的。因为开源产品也在不断迭代,你要保证闭源版本始终领先 12~18 个月。这对工程能力、产品设计、组织执行力都是非常大的挑战。
👦🏻 Koji
那你们现在也走的是 dual core 路线吗?
👨🏻 星爵
是的。我们在 2018、2019 年就做出这个决策了。这条路不容易,对工程和产品团队的执行力要求非常高,要有很强的迭代速度。

👦🏻 Koji
你怎么看 DeepSeek 的开源,对他们带来了哪些价值?
👨🏻 星爵
DeepSeek 和我们这种数据库公司不太一样。他们作为后发者,更关注的是怎么快速占领用户心智。开源帮他们完成了用户获取和注意力抢占的目标。对开发者来说,一旦安装了 DeepSeek,大概率就不会再装其他模型了。“开源”这其实是个“占位”的策略。
👦🏻 Koji
现在看来,大家选择开源的初衷已经不仅仅是为了吸引开发者共同参与,把产品越做越好。你觉得开源是不是正在失去它原本的那种纯粹理想?变成了一种竞争手段、一种品牌策略,甚至是一种获取好感和关注度的方式?
👨🏻 星爵
我觉得开源协作的方式本身也在发生变化。
吸引外部开发者参与当然是好事,但如果人太多,反而会带来项目管理和方向引导上的困难。所以现在很多成熟的开源项目,背后其实都有一家公司在引领社区、引领项目。
开源真正的价值,不一定是让每个人都参与贡献,而是把技术做到透明化。
很多工程师选择开源,不是为了贡献代码,而是通过查看源码,可以理解架构、了解设计细节,从中获得成长。
另外,在海外市场,选择开源往往不是为了不付钱,而是为了避免技术锁定。如果用了闭源产品,未来就只能走一条路,你无法判断它未来的发展方向。而开源至少提供一个退路,一旦不再合作,可以组建自己的团队,基于社区版本继续维护和升级。
👦🏻 Koji
那在你们的开源项目中,有多少关键代码是来自外部的开发者?
👨🏻 星爵
我们目前社区里有 300 多位开发者,其中只有 20% 来自我们公司,但他们贡献了 80% 到 90% 的代码。
外部开发者更多参与的是 bug 修复、工具增强、生态整合等工作。这和我们的预期一致。数据库系统复杂,要成为核心贡献者通常需要很长时间的积累。
👦🏻 Koji
你怎么定义这段创业的成功?你已经投入七、八年了,未来可能还会持续很多时间。你对它的期待是什么?
👨🏻 星爵
我希望成为全球第一个探索非结构化数据处理和向量数据库的人。
到我退休的那一天,我希望我们不仅是行业的先驱者,更是集大成者,也是一个真正的成功者。

👦🏻 Koji
你会担心吗?成为了行业的先驱,却没能坚持到最后,把果实摘下的人是别人。
👨🏻 星爵
这种恐惧是有的。走在无人区,本身就要面对巨大的不确定性和技术更新的压力,而在 AI 时代,这种压力又被放大和加速了。
创新者可能要尝试 1000 种方法,最终只有一种能成功;但追随者只需要复刻那一个结果。
唯有持续创新和快速迭代的能力,是真正的长期优势。
👦🏻 Koji
那你们公司这些年来,是怎么在管理、文化或其他层面上保持这种创新力的?
👨🏻 星爵
我认为创新是不能靠管理的。
如果想成为一家创新型公司,关键是要找到那些愿意创新、乐于快速迭代的人。
👦🏻 Koji
你已经创业八年了,有没有什么特别想对当初那个刚起步的自己说的话?
👨🏻 星爵
也许我会劝自己别创业。创业比想象中难太多,根本停不下来。你解决了一个问题,第二天就有新的挑战,每一个阶段都会遇到不同层面的难题。
如果你选择这条路,最好把它当成一种 lifestyle,一辈子愿意做的事。否则,你可能会崩溃。
👦🏻 Koji
你最接近崩溃的时刻是什么时候?
👨🏻 星爵
最坏的时候是一天崩溃好几次,状态好一点也差不多每一两个星期就来一次。
👦🏻 Koji
但你现在公司估值已经有 6 亿美金了,在很多人看来已经非常成功了。可你却还是会频繁崩溃,你能不能讲一个最近让你感到崩溃的瞬间?
👨🏻 星爵
过去这两年,是我创业以来最困难的阶段。
在那之前,我们主要专注于产品和开源,团队都是工程师出身,还在自己的“舒适区”里。但两年前公司开始推进商业化,还给自己定了很高的增长目标,压力非常大。
到了 2024 年,市场也开始动荡,一些 GenAI 公司倒闭,这并不是我们的问题,但仍然受到了波及。
👦🏻 Koji
你们有一些客户突然就消失了?
👨🏻 星爵
对,我们曾有个客户是美国顶尖的 AI 公司,后来突然陷入困境,项目中断,对我们打击很大。
客户流失后,我们还要快速找到新客户,不仅要填上缺口,还要维持整体增长趋势。
更难的是,团队也是第一次做商业化,很多组织架构、流程还没搭好,就已经要跑起来。就像是一边飞着飞机,一边换引擎,还要继续组装机身,那种状态非常煎熬。

👦🏻 Koji
作为工程师背景的创始人,你现在也开始频繁面对客户、推动销售了。有什么心得或方法可以分享吗?
👨🏻 星爵
首先还是要找到合适的人。在招人这件事上,再多的投入都不为过。
其次,商业化没什么可怕的。如果让我重新来一次,可能还是会经历同样痛苦的阶段,只不过错误的细节会不一样。关键是出错后能尽快恢复状态,既要调整自己的心态,也要稳住团队的节奏,最重要的是别让士气掉下来。
👦🏻 Koji
在遭遇打击时,你是怎么维持团队士气的?
👨🏻 星爵
最终还是要靠打胜仗来提气。
出错不可避免,但不能反复犯同一个错。关键是要从失败里尽快总结经验,快速走出来。
除此之外,战略判断也很重要;避免犯方向性的错误。
同时也要接受自己不完美。如果你不能和自己的缺点和解,很多时候真正击垮你的不是别人,而是你自己。
很多竞争,最后比的不是谁做得更多,而是谁在压力下少犯了几个错。
👦🏻 Koji
那有没有什么是你八年前坚信不疑的,但现在已经完全不信了?
👨🏻 星爵
在创业前,我是个百分百的理想主义者。但八年下来,这层彩色的外衣已经褪去,现在更多留下的是一件灰色的内衣。
👦🏻 Koji
有没有一件事,会让你明显感受到自己从理想主义走向现实主义的变化?
👨🏻 星爵
在团队管理上,以前我觉得最理想的状态是绝对的透明、无话不说。那时候我把管理等同于官僚。但现在我认为,管理其实是组织成长中不可缺少的一部分。
技术上也是。作为工程师,理想主义让人沉迷于创新和极致。但在商业世界,“足够好”就行了。
领先一点点就能赢。像英特尔、英伟达,靠稳扎稳打的“挤牙膏”式进步,也能取得巨大成功 ——因为他们把握了技术与商业之间的节奏感。
我始终相信,技术世界需要理想主义。虽然理想主义已被现实打磨得所剩无几,但正是当年的极致追求,才奠定了我们产品和技术的优势。
即使现在我们正在变得更商业化,我还是希望,在现实主义逐渐占据决策的同时,我们的内心深处,能留下一块彩色的、有情怀的天空。

👦🏻 Koji
在整个 AI Infra 的赛道中,从大模型到数据库,如果你要投资,会看好哪些公司?
👨🏻 星爵
在整个 AI 赛道中,我最看好的其实是云平台,尤其像亚马逊这样的巨头。因为 AI 已经进入“能源和基建”的阶段,最终比拼的是谁有能力建设和运营大规模的数据中心,而这正是公有云的强项。我认为公有云的重要性还会持续上升。
大模型作为底座当然不可忽视,尤其是几家头部公司。
另外也有些不错的 AI 应用公司。我自己用得最多的几个工具是 ChatGPT、 DeepSeek、Cursor。
👦🏻 Koji
今天非常感谢星爵,和我们一起录了一期非常硬核的播客。也祝 Zilliz 继续高速成长。期待星爵下次再来做客十字路口。
👨🏻 星爵
谢谢。
文章来自于微信公众号“十字路口Crossing”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
