# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
声音理解能力新SOTA,小米全量开源了模型。
MiDashengLM-7B,基于Xiaomi Dasheng作为音频编码器和Qwen2.5-Omni-7B Thinker作为自回归解码器,通过创新的通用音频描述训练策略,实现了对语音、环境声音和音乐的统一理解。
其性能在22个公开评测集上刷新多模态大模型最好成绩,单样本推理的首Token延迟(TTFT)仅为业界先进模型的1/4,同等显存下的数据吞吐效率是业界先进模型的20倍以上。
2024年,小米发布的Xiaomi Dasheng声音基座模型在国际上首次突破AudioSet 50+ mAP,在HEAR Benchmark环境声、语音、音乐三大领域建立领先优势并保持至今。
今年在法国南特举行的IEEE ICME 2025 Audio Encoder Capability Challenge上,冠亚军队伍全部基于Xiaomi Dasheng作为提交方案。
Xiaomi Dasheng在小米的智能家居和汽车座舱等场景有超过 30 项落地应用。
行业首发的车外唤醒防御、手机音箱检测异常声音、“打个响指”环境音关联IoT控制能力,背后都有Xiaomi Dasheng作为核心算法的赋能。
作为该模型的重要扩展,MiDashengLM-7B模型其训练数据由100%的公开数据构成,模型以宽松的Apache License 2.0发布,同时支持学术和商业应用,并欢迎来自开源社区的代码合并请求。
MiDashengLM在音频描述、声音理解、音频问答任务中具备显著优势,同时具备可用的语音识别能力。
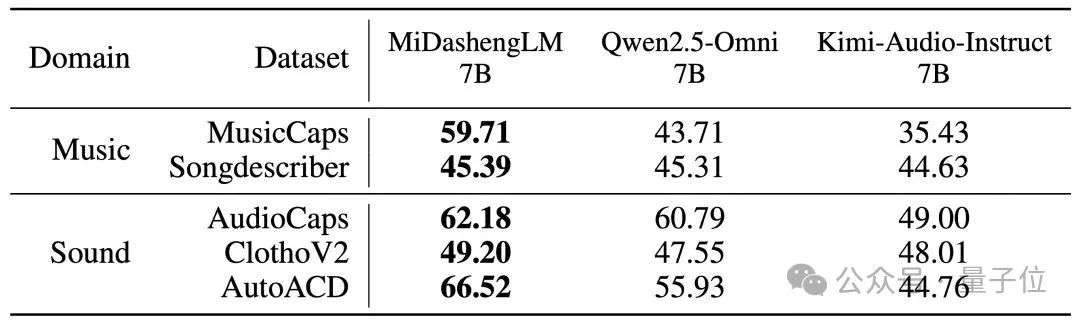
△音频描述任务性能(FENSE指标)
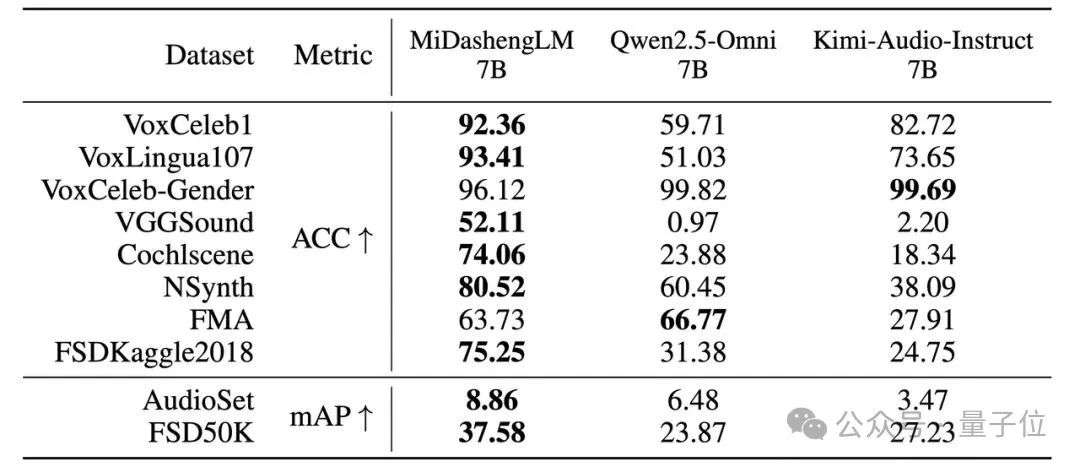
△声音理解任务性能
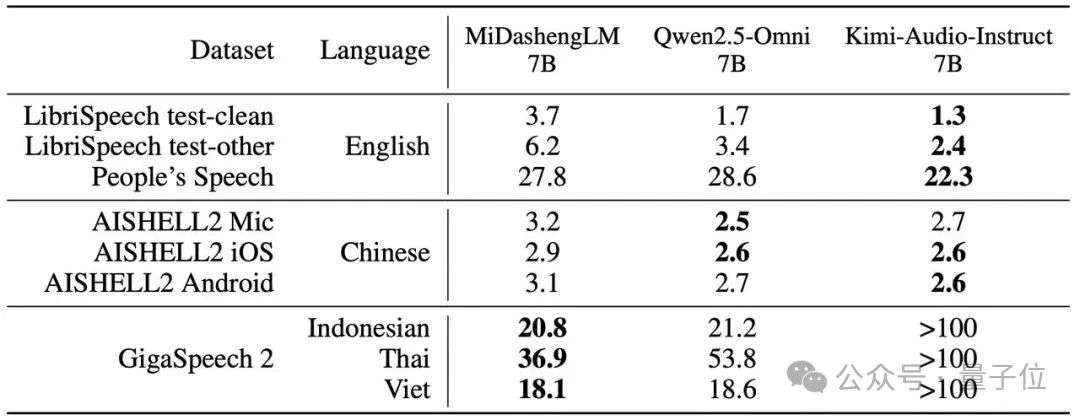
△语音识别任务性能(WER/CER指标)
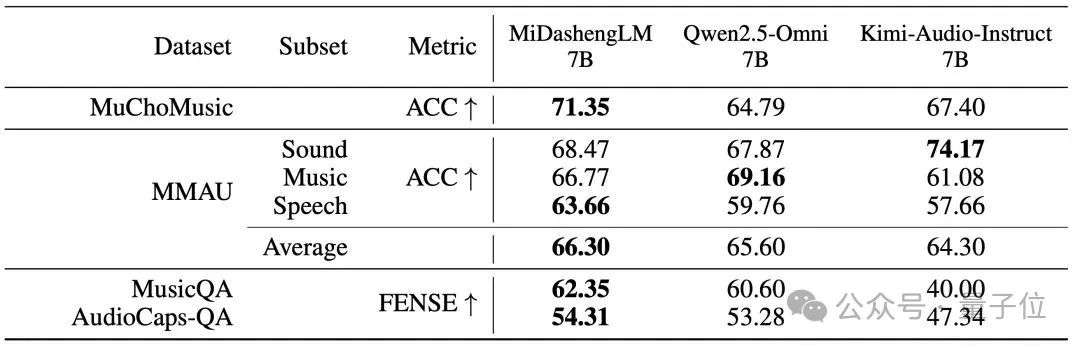
△音频问答任务性能
Xiaomi Dasheng音频编码器是MiDashengLM的强大音频理解能力的重要来源。
在用于评估编码器通用能力的X-ARES Benchmark上,Xiaomi Dasheng在多项关键任务上,尤其是非语音类理解任务上显著优于作为Qwen2.5-Omni、Kimi-Audio等模型音频编码器的Whisper。
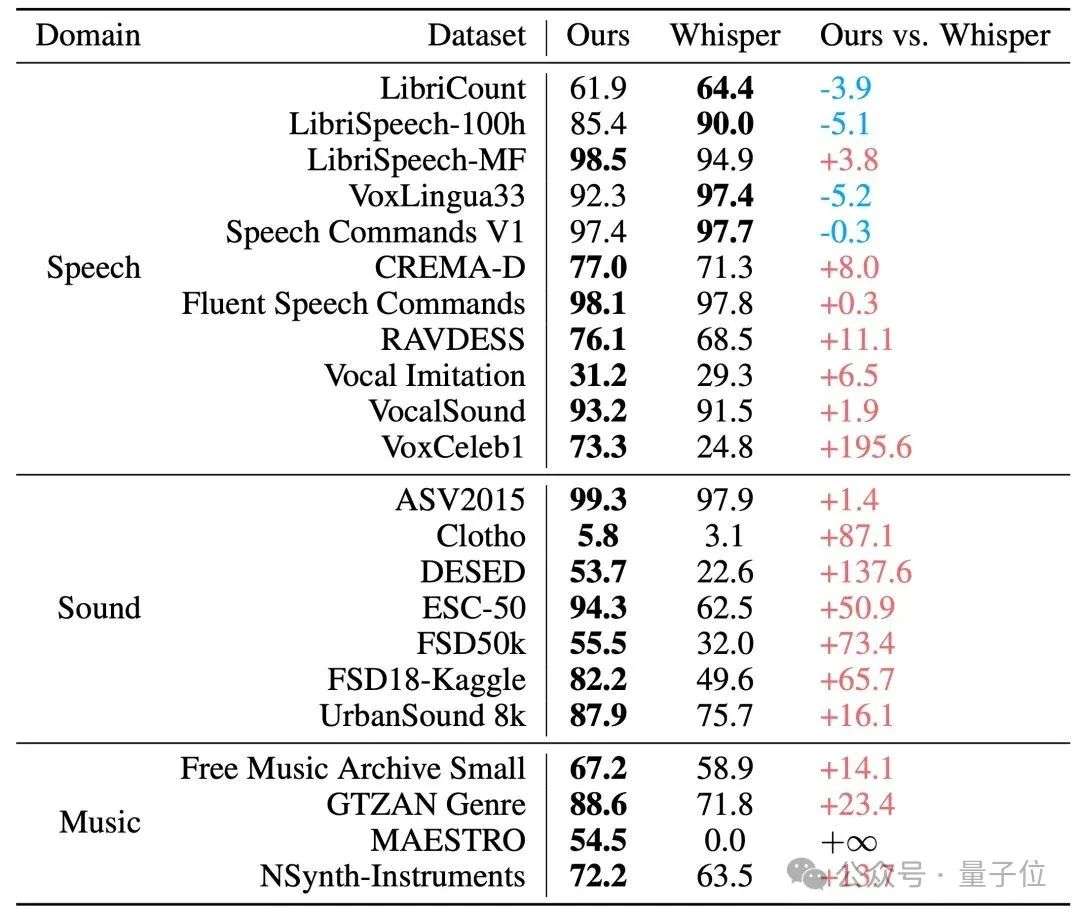
△音频编码器在 X-ARES Benchmark 上的分数对比
Xiaomi Dasheng不仅在用于声音理解任务上的声音表征上体现压倒性优势,它还可以用于音频生成任务,如语音降噪、提取和增强。
Dasheng-denoiser是小米近期已开源并将在荷兰鹿特丹召开的国际会议Interspeech 2025上展示的降噪模型,它使用Xiaomi Dasheng从带噪语音中提取音频嵌入向量,然后通过一个简单的降噪编码器网络模型对这些嵌入做降噪处理,最后利用声码器由降噪后的嵌入向量得到干净的语音。
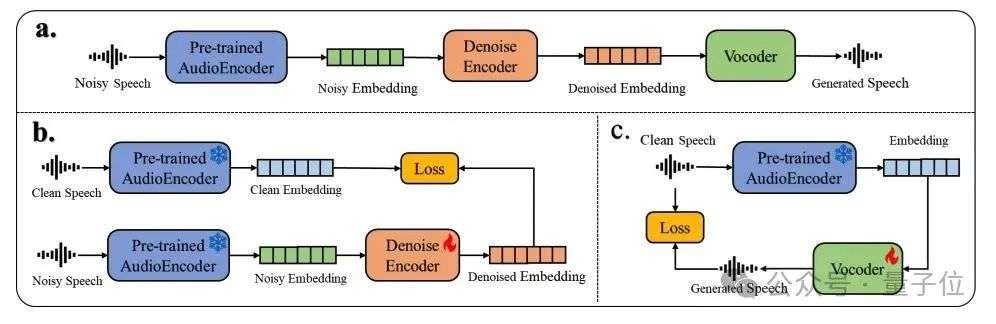
△Dasheng-denoiser 降噪模型
MiDashengLM的训练和推理效率是它的另一项重大优势。对于单个样本推理的情形,即batch size 为 1 时,MiDashengLM的首个token预测时间(TTFT)仅为Qwen2.5-Omni-7B的1/4。
而当批次处理时,MiDashengLM的优势更加明显,在80GB GPU上处理30秒音频并生成100 个 token的测试中,MiDashengLM可以把batch size设置为512,而 Qwen2.5-omni-7B 在 batch size 设置为16时即出现显存溢出(OOM)。
这种效率优势直接转化为实际部署效益,在同等硬件条件下可支持更多的并发请求量,降低计算成本。
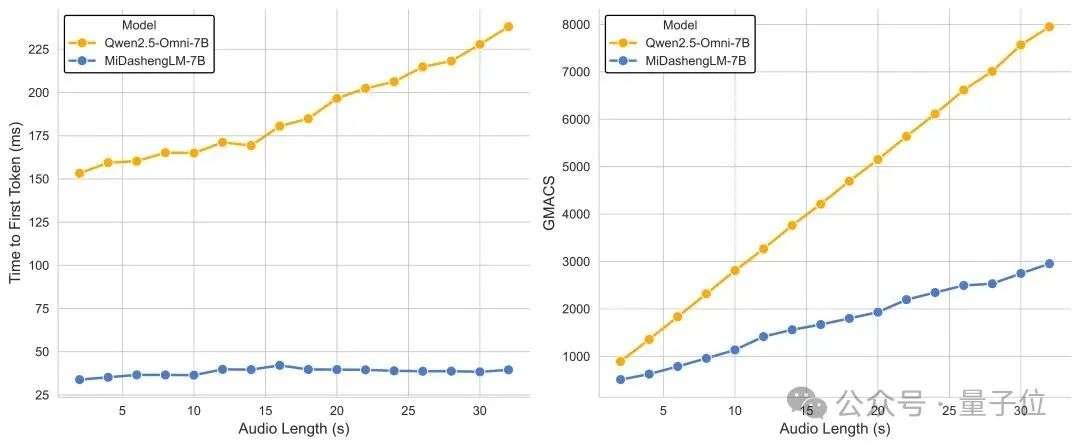
△Batch size = 1 时 TTFT 和 GMACS 指标对比
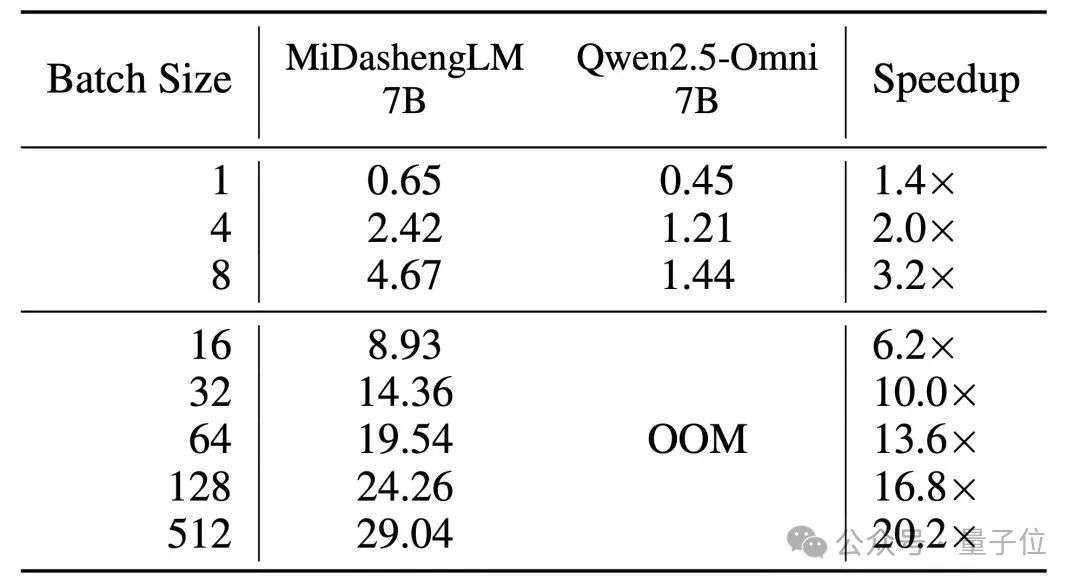
△80G 显存环境下模型每秒可处理的 30s 音频个数
MiDashengLM 的高效性也和 Xiaomi Dasheng 密不可分。基于 Xiaomi Dasheng 架构的 MidashengLM 模型,在维持音频理解核心性能指标基本持平的前提下,通过优化音频编码器设计,成功将其输出帧率从 Qwen2.5-Omni 的 25Hz 大幅降至 5Hz(降幅达80%),显著降低了计算负载并实现了推理效率的显著提升。
MiDashengLM采用创新的通用音频描述对齐范式,避免了用ASR转录数据对齐仅关注语音内容而丢弃环境声音和音乐信息,且无法捕捉说话人情感、空间混响等关键声学特征的局限,通用描述对齐策略通过非单调的全局语义映射,迫使模型学习音频场景的深层语义关联。
而且,该方法可以使用几乎所有的数据,包括噪声或非语音内容,而基于ASR转录的方法会丢弃非语音数据如环境声或音乐,导致数据利用率低下,基于ASR的对齐方法在ACAV100M-Speech数据集上会损失高达90%潜在有用数据。
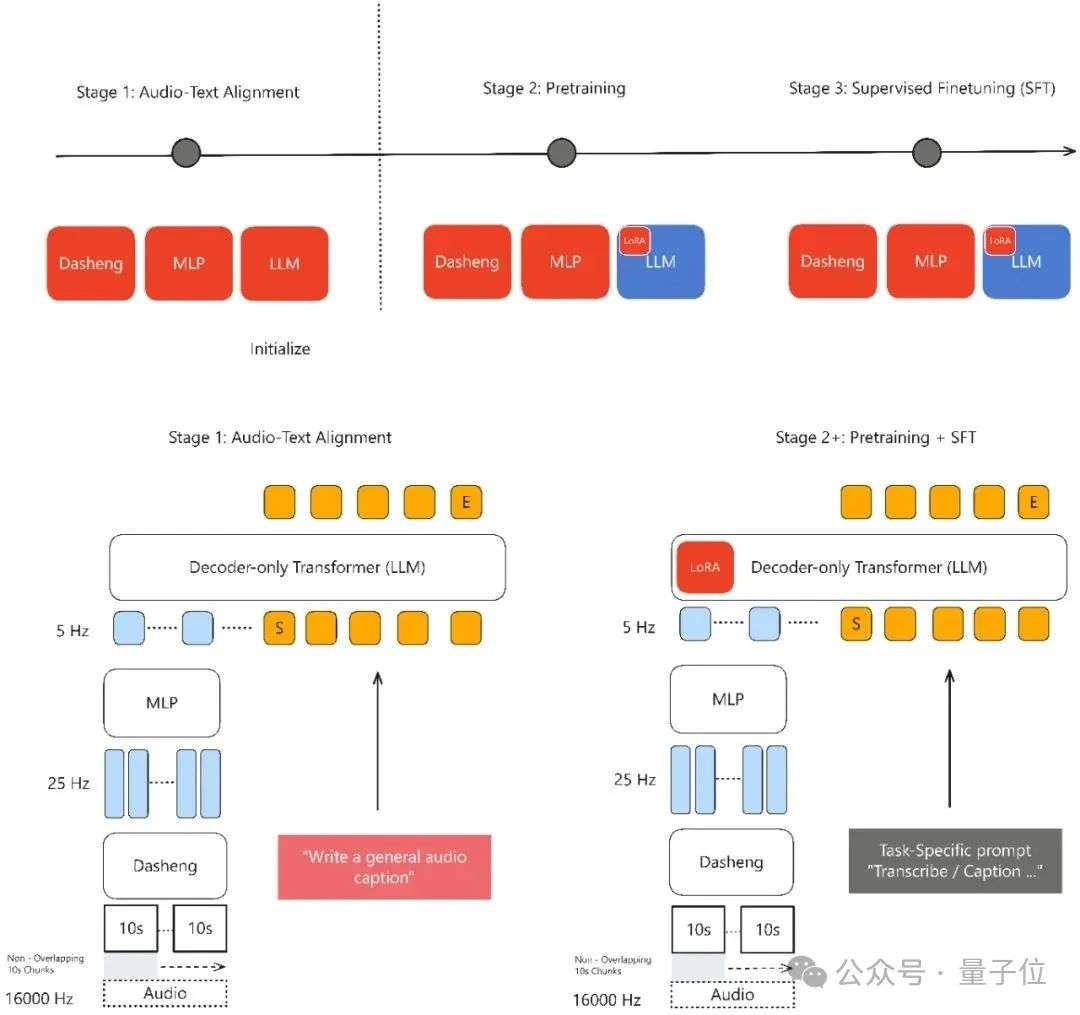
△MiDashengLM 训练框架
MiDashengLM的训练数据通过多专家分析管道生成。首先对原始音频使用各种专家模型作语音、人声、音乐和环境声学的细粒度标注,包括使用Dasheng-CED模型预测2秒粒度的声音事件,再通过DeepSeek-R1推理大模型合成统一描述。
全部训练数据的原始标签在预训练中被弃用,而只采用利用上述流程生成的新的丰富文本描述标签,以迫使模型学习更丰富全面的声音信息。
其中,来自ACAV100M的开源数据集经过上述流程重新标注后,形成了新的ACAVCaps训练集和MECAT Benchmark。MECAT Benchmark已于近期开源,ACAVCaps数据集将在ICASSP论文评审后开放下载。
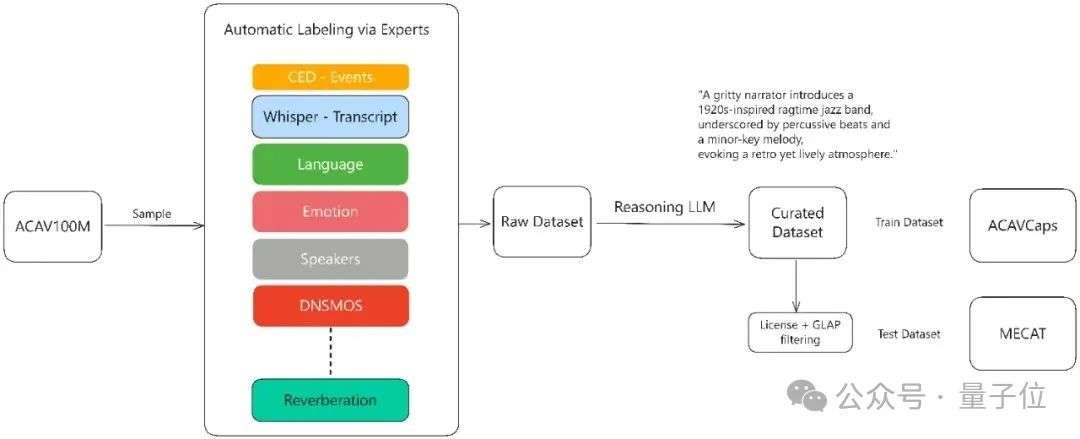
△ACAVCaps 训练数据集构建流程
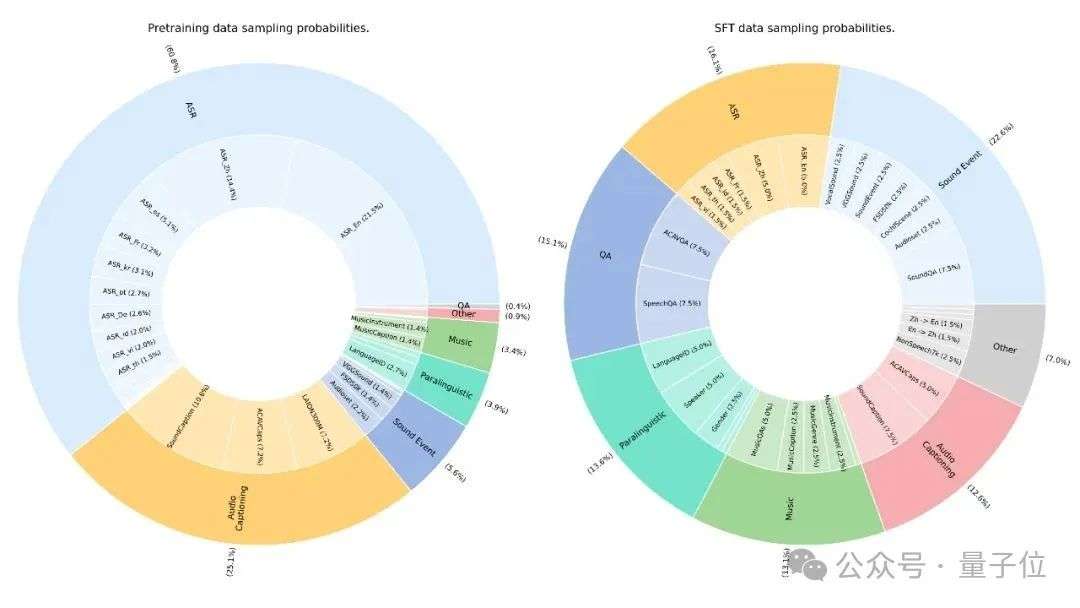
MiDashengLM训练数据100%来自公开数据集,涵盖五大类110万小时资源,包括语音识别、环境声音、音乐理解、语音副语言和问答任务等多项领域。数据分布经过精心设计,在预训练阶段90%采样来自ASR数据集但使用描述文本代替ASR转录文本,剩余10%分配给声音、音乐等专业任务,并同样使用ACAVCaps流程生成的描述文本代替原始标签。
不同于 Qwen2.5-Omni 等未公开训练数据细节的模型,MiDashengLM 完整公开了 77 个数据源的详细配比,技术报告中详细介绍了从音频编码器预训练到指令微调的全流程。
作为小米“人车家全生态”战略的关键技术,MiDashengLM 通过统一理解语音、环境声与音乐的跨领域能力,不仅能听懂用户周围发生了什么事情,还能分析发现这些事情的隐藏含义,提高用户场景理解的泛化性。
基于 MiDashengLM 的模型通过自然语言和用户交互,为用户提更人性化的沟通和反馈,比如在用户练习唱歌或练习外语时提供发音反馈并制定针对性提升方案,又比如在用户驾驶车辆时实时对用户关于环境声音的提问做出解答,其应用场景有广阔的空间。结合高效的推理部署性能,MiDashengLM 将广泛赋能智能座舱、智能家居等场景,推动多模态交互体验升级。
MiDashengLM 以 Xiaomi Dasheng 音频编码器为核心组件,是 Xiaomi Dasheng 系列模型的重要升级。在当前版本的基础上,小米已着手对该模型做计算效率的进一步升级,寻求终端设备上可离线部署,并完善基于用户自然语言提示的声音编辑等更全面的功能。
MiDashengLM 基于 Apache 2.0 开源协议发布。诚邀全球开发者、行业伙伴及学术机构将其免费集成于商业产品或用于学术研究。模型迭代将深度听取社区优化建议,GitHub 项目持续接纳社区高质量代码合并。小米期待和全球开发者一起,秉持开源共享理念,共筑透明、高效、普惠的智能时代。
GitHub 主页:https://github.com/xiaomi-research/dasheng-lm
技术报告:https://github.com/xiaomi-research/dasheng-lm/tree/main/technical_report
模型参数(Hugging Face):https://huggingface.co/mispeech/midashenglm-7b
模型参数(魔搭社区):https://modelscope.cn/models/midasheng/midashenglm-7b
网页 Demo: https://xiaomi-research.github.io/dasheng-lm
交互 Demo:https://huggingface.co/spaces/mispeech/MiDashengLM
文章来自于微信公众号“量子位”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
