# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大部分现有的文档检索基准(如MTEB)只考虑了纯文本。而一旦文档的关键信息蕴含在图表、截图、扫描件和手写标记中,这些基准就无能为力。为了更好的开发下一代向量模型和重排器,我们首先需要一个能评测模型在视觉复杂文档能力的基准集。
为了填补这一空白,JinaVDR(Visual Document Retrieval,视觉文档检索)应运而生。
🔗: https://github.com/jina-ai/jina-vdr/
🤗: https://huggingface.co/collections/jinaai/jinavdr-visual-document-retrieval-684831c022c53b21c313b449
JinaVDR 的核心,是一个专为处理视觉复杂文档任务设计的评测数据集。我们收集了大量布局复杂的真实文档,它们来自多种语言,很多内部混合了图表、表格、文字和图像,文件类型也覆盖了从数字化的网页、屏幕截图、PDF 再到物理的扫描件。然后,为这些文档一一匹配了有针对性的文本查询。通过这套“查询-文档”对,就能量化地评估一个模型在处理复杂视觉信息时的检索性能。
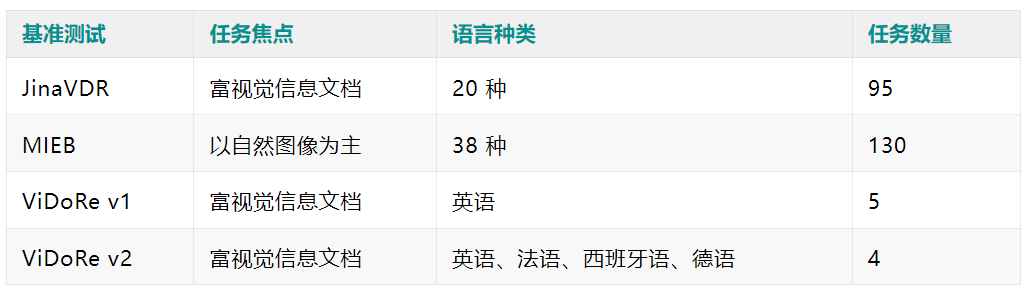
JinaVDR 统计信息,展示了查询/文档的语言、领域和文档格式
构建 JinaVDR 的目标非常明确:尽可能地模拟真实世界的检索任务。 为此,我们重点解决了三个问题:
项目里一个关键设计是:在许多数据集中,特意混合了不同的语言和格式。这样做可以创造出更贴近现实的测试条件,真正考验模型在实际部署时处理复杂情况的能力。
为了确保 JinaVDR 的数据足够多样、任务足够真实,我们综合运用了四种方法来构建这个基准。最终的评估框架覆盖了 20 种语言、95 项具体任务,其中的文档形式涵盖了图表、地图、扫描件、Markdown 文件和复杂表格。
在评测方式上,设计了两种查询方式:视觉问答(如,“1855年,巴利亚多利德法院驳回了多少起民事诉讼?”)和 关键词查询(如,“LED 市场在不同地区的增长情况”)。将两者结合,可以更准确地评估模型处理真实文档的能力。
具体的构建方法如下:
通过设计基于规则的查询模板,将 MPMQA 这类 OCR 数据集转化为检索任务。同时,也调整了部分问答数据集的格式,使其能适配于检索场景。

JinaVDR 的 MPMQA 文档和查询示例
对于一些现有的 PDF 数据集(如 StanfordSlides、TextbookQA 等),我们投入了大量人力进行手动标注,逐一创建了高质量的“查询-文档”配对。这样做虽然成本高,但能保证评测的精准性。

JinaVDR 的 StanfordSlides 文档和查询示例
为了扩大数据规模和多样性,利用 Qwen2-VL-7B-Instruct 模型,为来自 Europeana 等平台的现有文档,批量生成上下文相关的查询。此外,还将纯文本的表格数据渲染成图片,再通过模板生成查询,AirBnBRetrieval 任务就是用这种方法构建的。

JinaVDR 的 Europeana 文档和查询示例,包括英文查询翻译以供参考
有些数据集,比如 OWIDRetrieval,天然就包含了文章与图表的配对。我们直接利用这种结构,从文章中抽取片段做查询,把对应的图表作为检索目标。

JinaVDR 的 OWIDRetrieval 文档和查询示例
综合运用上述方法,最终确保了 JinaVDR 在文档类型、语言和检索场景上都达到了理想的覆盖广度。
在开发 JinaVDR 之前,我们调研了市面上的主流基准,发现它们在评测视觉复杂文档时都存在一些问题。
像 MTEB(大规模文本向量基准)这类框架,在评测纯文本检索任务时表现出色,涵盖了跨领域、跨语言的数据集。但如果文档的关键信息存在于视觉布局或图表中,MTEB 就无法胜任了。
像 ViDoRe 系列是专门为视觉文档设计的基准,整合了 5 个纯英文数据集,内容上混合了学术资料与合成数据。但 ViDoRe v1 主要面向适合 OCR 的英文单页文档,领域也局限在科学论文和医疗保健等方面。它的查询方式也比较初级,采用的是抽取式查询,即搜索词通常能直接在目标文档里找到。
ViDoRe v1 基准数据集中的样本
当 ColPali 这类模型在 v1 上分数已经到 90% nDCG@5后,说明这个基准的评测“天花板”已经出现。后续的 ViDoRe v2 虽然做了一些改进,支持了更长、可跨文档的查询和无明确上下文的“盲”查询,也将语言扩展到了法语、德语和西班牙语。但在语言多样性和领域覆盖上,仍然很有限。

ViDoRe v2 基准数据集的样本
MIEB (大规模图像向量基准)专注于视觉向量模型,涵盖了 130 多项任务,其中一些已经超出了检索的范畴。但它的评测对象,主要是缺乏文本内容的纯图像,而不是信息丰富的视觉文档。 它能很好地测试模型的视觉理解能力,但无法评估模型结合视觉布局和文本内容进行检索的综合能力。

MIEB 基准测试的样本
正是看到了这些现有基准的局限,我们才着手构建 JinaVDR。希望在这些工作的基础上更进一步,将评测范围扩展到那些包含复杂布局(如图表、表格、文本与图像混合)的多语言视觉文档,同时引入更贴近真实世界的查询与问答。
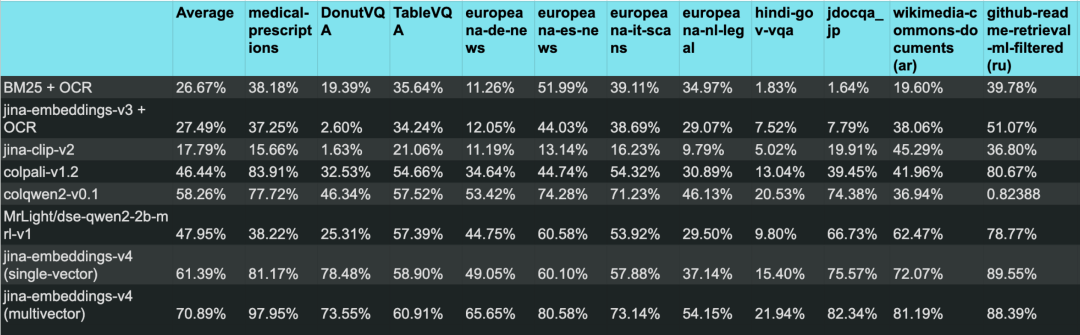
我们用 JinaVDR 跑了一系列主流的向量模型,得到一个很明确的结论:许多前沿模型,在处理这些多样化的视觉任务时,表现都并不理想。
作为参照,也测试了传统的 OCR + BM25 方法作为 baseline。不出所料,表现更差,尤其是在处理非英语和结构化文档时。这说明 JinaVDR 提出的这些任务,确实有相当的难度,传统方法难以应对。
但 jina-embeddings-v4 是个明显的例外。它的多模态方法,相比依赖 OCR 的传统流程或其他早期模型,能更有效地处理这种复杂的、多语言的文档检索。
您可以使用我们的开源代码 https://github.com/jina-ai/jina-vdr/ 自行运行基准测试。
它的性能优势,主要来自其多向量(multivector)功能。
传统的单向量(single-vector)方法,必须把整页的所有信息——包括文字、图表、布局——都强行压缩进一个向量里。这个过程不可避免地会丢失大量细节。
而多向量方法则不同,它可以为文档中的不同部分(例如,一个文本块、一张表格)生成各自独立的向量。这样就能完整地保留文档的精细信息,检索时自然也就能做到更精确的匹配。
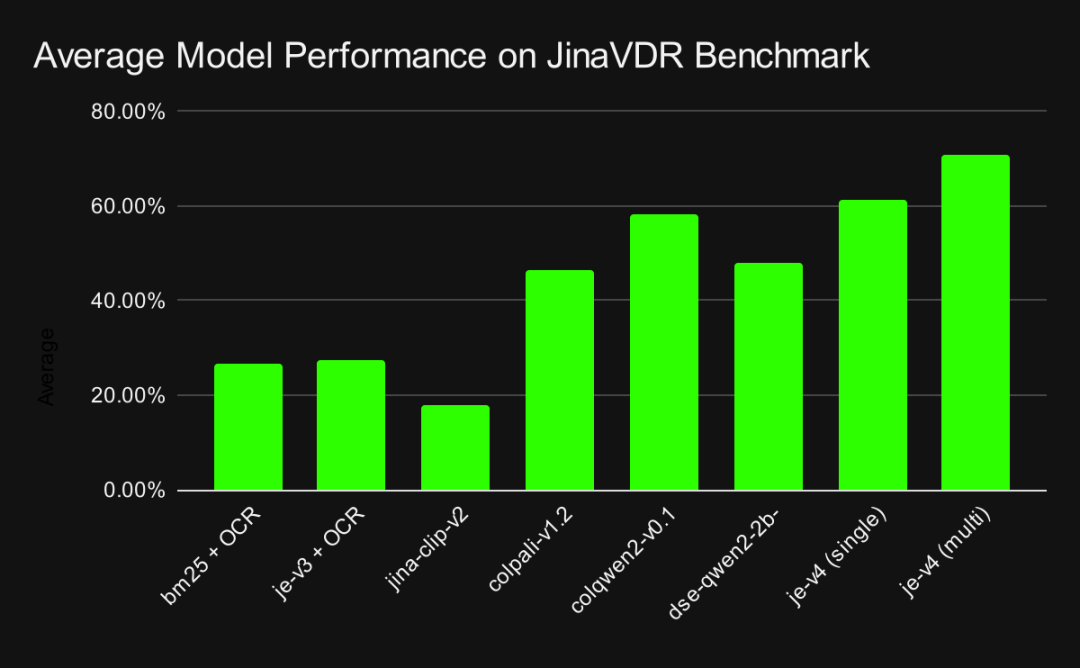
模型在 JinaVDR 基准测试中的性能,在所有任务中取平均值%
MTEB 是社区公认的评测基准框架。为了方便大家使用,我们把 JinaVDR 直接集成到了 MTEB 框架里。这样,大家就可以用熟悉的脚本和工具,在我们的基准上快速测试自己的模型。
🔗:https://github.com/embeddings-benchmark/mteb/pull/2942
这个集成过程需要把数据转换为 BEIR 格式,这也带来一个权衡:MTEB 版本的数据不包含预先提取的 OCR 结果。
这意味着,像 BM25 这类依赖纯文本的传统方法,无法在 MTEB 框架内直接运行。但这未必是件坏事。它把评测的重点强制拉回到了我们最初的目标上:评估模型对视觉文档本身的理解能力,而不是让测试退回到依赖纯文本的检索路径。
要构建一个来源广泛又全面的基准,同时还要保证它能实际运行、评估有效,就必须对数据进行一系列审慎的预处理。我们想在这里坦诚地说明这些限制:
处理高分辨率的视觉文档,计算开销非常大。如果保留原始数据集的全部规模,对大多数用户来说运行一次评测会非常困难。
因此,我们对每个数据集都进行了子采样,将其规模控制在最多 1,000 个样本。这是一个在评测可用性和任务覆盖广度之间做出的明确取舍。
真实世界的数据是杂乱的,比如扫描文档的图像质量差,这虽然能反映真实场景,却也给控制合成数据的质量带来了麻烦。我们花了很多精力去做清理和过滤,具体地:
JinaVDR 的出发点很简单:行业里对模型的评测能力,已经跟不上模型本身的发展速度了。尤其是在视觉文档检索这个方向,传统的纯文本基准,已经无法有效评估一个现代模型处理复杂布局、图表和多语言混合文档的能力。
JinaVDR 正是为解决这个问题迈出的第一步。通过提供一个覆盖多种语言、领域和复杂布局的评测集,希望能为社区提供一个更贴近真实应用场景的“靶场”,让模型的优劣能被更准确地衡量。
未来的评测基准,必须直面真实世界的复杂性,而不是停留在实验室的理想化环境里。从法律研究到医疗诊断,这些领域的应用不会给我们一个干净的数据集,它们只会给我们一堆混乱、多语言、视觉复杂的文档。评测工具也必须跟上这个现实。
JinaVDR 只是一个开始。我们最终的目标,是推动和帮助社区一起,构建出能够真正理解并处理这些复杂文档的检索系统。
文章来自于微信公众号“Jina AI”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
