# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
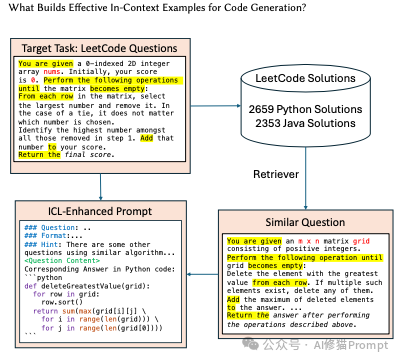
长久以来我们都知道在Prompt里塞几个好例子能让LLM表现得更好,这就像教小孩学东西前先给他做个示范。在Vibe coding爆火后,和各种代码生成模型打交道的人变得更多了,大家也一定用过上下文学习(In-Context Learning, ICL)或者检索增强生成(RAG)这类技术来提升它的表现。但您有没有遇到过这样的困惑:有时候给AI一个例子,它瞬间开窍,表现得像个天才;可换个例子,它又蠢得让人想砸键盘。这到底是为什么?来自香港科技大学的研究者们,通过一篇硬核论文,总算把这个“玄学”问题给整明白了。

这些问题可能也正是您在使用AI生成代码时偶尔想过,但没有深究的问题。研究者们没有满足于“反正它就是能行”的模糊答案,而是像侦探一样,提出了三个直击要害的问题,试图彻底搞明白AI的学习机制:
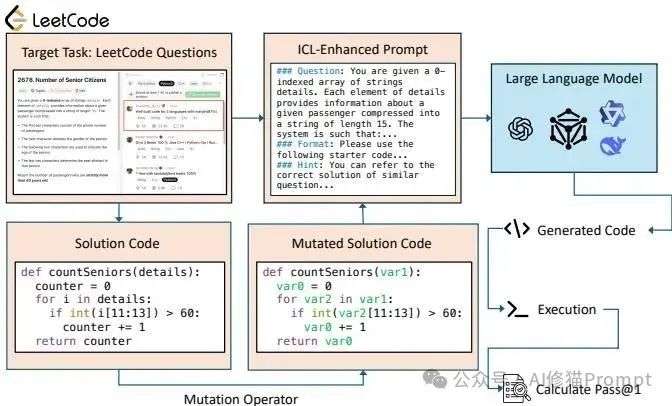
为了回答这些问题,研究者们设计了一个非常巧妙的实验,叫做“受控消融研究”(controlled ablation study)。这个很像中学物理的“控制变量法”,一次只改变一个条件,然后观察结果的变化。在这里,他们是拿一份“完美代码”作为基准,然后系统性地一次只“搞坏”它一个地方。
他们用来“搞坏”代码的工具,叫做“突变算子”(mutation operators),具体手法五花八门,但都很有针对性:
他们就是用这种方式,像做化学实验一样,精准地测试每一种代码特征对AI学习效果的影响,最终得出了相当有冲击力的结论。
值得一提的是,为了保证结论的普适性,研究者们还在 Python 和 Java 这两种主流编程语言上分别进行了测试,确保这些发现不是某种语言的“特例”。
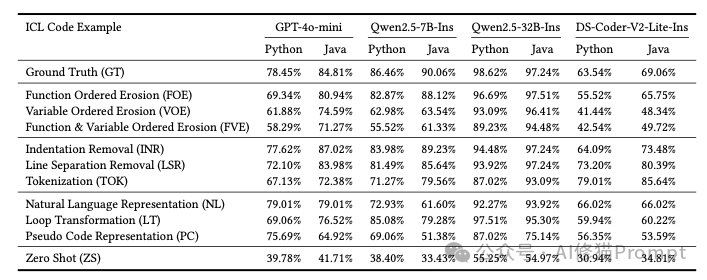
实验结果表明,在所有被“破坏”的特征里,有意义的标识符命名(尤其是变量名)简直是拥有碾压性的重要地位。当研究者把代码里那些清晰的变量名换成无意义的符号后,AI代码生成的正确率直接崩盘,性能最多时下降了足足30个百分点!相比之下,那些破坏代码格式(比如删除缩进)或者改变实现细节(比如循环方式)的操作,对AI性能的影响就小得多了。这说明,对于AI来说,代码里那些变量名、函数名所承载的语义信息,是它理解代码意图的最主要线索,远比代码长得好不好看、用的是哪种循环要重要得多。
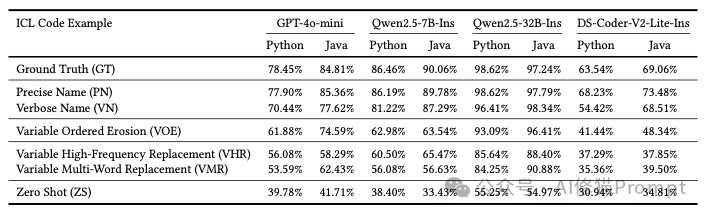
既然命名这么重要,那AI到底喜欢什么样的命名呢?研究者发现对ICL(上下文学习)性能贡献最大的代码特征是有意义且语义准确的标识符命名(Meaningful and Semantically Precise Identifier Naming),尤其是变量名。
简单来说,就是变量、函数等的名字是否能清晰地表达出它们的用途。下面我们通过一个具体的例子来感受一下“好”的命名和“坏”的命名对LLM理解代码的巨大影响。
场景设定: 假设我们需要让LLM学习如何“计算购物车中所有商品加税后的总价”。
def calculate_final_price(shopping_cart, tax_rate):
"""
Calculates the total price of items in a shopping cart, including tax.
"""
subtotal = 0
# Calculate subtotal before tax
for item in shopping_cart:
item_price = item['price']
quantity = item['quantity']
subtotal += item_price * quantity
# Calculate final price with tax
total_price = subtotal * (1 + tax_rate)
return total_price
# 示例数据
cart_data = [{'price': 10.0, 'quantity': 2}, {'price': 5.5, 'quantity': 3}]
sales_tax = 0.08
# 调用函数
final_cost = calculate_final_price(cart_data, sales_tax)
这是论文中提到的“变量有序侵蚀 (Variable Ordered Erosion, VOE)”方法的体现,也是导致性能下降最多的罪魁祸首。
def do_calculation(data_list, rate_val):
"""
Performs a calculation on a list of data.
"""
temp_val = 0
# Loop through data
for entry in data_list:
p = entry['p_val']
q = entry['q_val']
temp_val += p * q
# Final calculation
result = temp_val * (1 + rate_val)
return result
# 示例数据
d = [{'p_val': 10.0, 'q_val': 2}, {'p_val': 5.5, 'q_val': 3}]
r = 0.08
# 调用函数
final_res = do_calculation(d, r)
也就是说LLM在学习代码时,很大程度上依赖于代码中的文本语义信息,就像人类阅读一样。一个好的变量名就像一个清晰的路标,直接告诉LLM代码的意图。而一个坏的变量名就像一块模糊不清的指示牌,迫使LLM在一个充满迷雾的逻辑迷宫中艰难探索,自然就很容易迷路和犯错了。
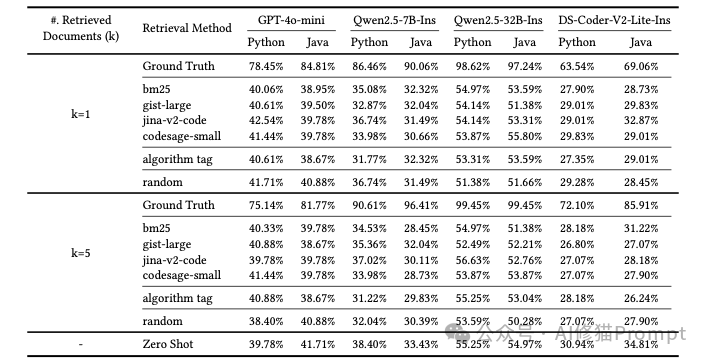
这个发现,可能对所有正在做RAG系统的工程师来说,是一个挺大的警醒。研究结果表明,如果您给AI一个问题的标准答案,它能很好地利用这些“直接信息”来解决问题,这就像一个会完美“抄作业”的学霸。但是…但是!如果您给它的是另一个“相似问题”的答案,哪怕解题思路几乎一样,希望能让它“举一反三”,结果是它不仅学不会,甚至还会被这些不完全匹配的信息严重干扰,表现得比不给任何示例(Zero-Shot)还要糟糕。
您可能会好奇,这些结论是在哪些模型上验证的呢?研究者们选取了市面上几款主流的模型进行了测试,包括 GPT-4o-mini、Qwen系列(7B和32B),以及 DeepSeek-Coder。一个特别有价值的发现是,不同的模型在面对这些“被破坏”的代码时,表现出了非常不同的“性格”:
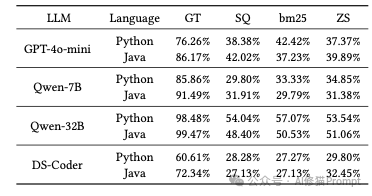
基于这些发现,当您在开发和优化自己的AI产品时,有几件事真的可以立刻做起来:
我们总想着去追寻更复杂的模型、更花哨的Prompt技巧,但也许提升AI代码能力最有效的方法,恰恰是回归到我们学习编程的第一课:写干净、可读的代码,起有意义的名字。编写人类和AI都能轻松理解的代码即拥有极高语义清晰度的代码已不再仅仅是提升团队协作效率的“软技能”,而是决定AI辅助开发工具能否发挥其最大潜力的“硬性技术要求” 。在所有代码特征中,清晰的变量和函数命名拥有绝对的优先权。总结就是,语义!语义!还是语义!
文章来自于微信公众号“AI修猫Prompt”。


【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
