# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
过去几年,AI 的巨大突破赋予了机器语言的力量。而下一个前沿,是给予它们关于世界的记忆。当大模型只能分析短暂的视频内容时,一个根本性的鸿沟依然存在:AI 能够处理信息,却无法真正地“记住” 信息。如今的瓶颈已不再是“看见”,而是如何保留、索引并回忆构成我们现实世界的视觉数据流。这背后,是当下大多数 AI 的“记忆”仍停留在为文本服务的“上下文工程” ,这是一种变通,而非真正的解决方案。
Memories.ai 正在构建一条不同的路径。他们致力于打造一个基础性的视觉记忆层,目标是成为所有 AI 的“海马体” 。创始人 Shawn 认为,真正类人的记忆本质上是视觉的,而非文本的。他们推出的 LVMM(大型视觉记忆模型)并非单一的端到端模型,而是一个受人脑启发的复杂系统,通过工程化的方式实现对无限量视频数据的压缩、索引和查询。
本篇文章是我们和 Memories.ai 创始人 Shawn 的访谈,探讨他们如何构建 AGI 拼图中这块至关重要的部分:
• 为什么说当下 AI 的记忆大多只是“上下文工程” ?视觉记忆与文本记忆在数据特性上有何根本区别?
• LVMM 的类脑系统架构,是如何被设计来克服视频数据独有的挑战:海量数据和低信噪比的?
• 作为“B2B 基础设施”提供商,Memories.ai 如何在赋能其他 AI 公司的同时,也为安防、媒体和营销等传统行业打造直接的解决方案?
• 为什么说构建和管理 PB 级(petabyte-scale)基础设施的能力,才是打造全球视觉记忆的真正护城河 ?
• 视觉记忆如何成为解锁下一代真正个性化的 AI 助手和人形机器人的钥匙?
我们认为,从语言处理到视觉记忆,Memories.ai 不仅仅是在创造一个理解视频的工具,更是在为一个 AI 构建核心组件,AI 将像我们一样去体验、记忆并从真实世界中学习。多模态 AI 的时代将被建立在记忆的基石之上。

海外独角兽:先请 Shawn 做一下自我介绍,也简单介绍一下 Memories.ai。
Shawn:我是 Shawn,Memories.ai 的创始人。我们希望给 AI 打造一个基础性的视觉记忆层,简单来说就是让 AI 能够“看见并记住”。过去的 AI 只能像 ChatGPT 一样理解文字;虽然 Gemini 可以理解视频,但只能处理很短的视频内容。但人类可以轻松记住一小时的视频,就像我能记住自己 28 年的人生经历一样。因此,我们强调 AI 不仅要“看见”,更要“记住”。我们希望赋予 AI 这样的能力,并构建底层基础设施,使未来所有 AI 的视觉记忆都能托管在 Memories.ai 上。
Memories.ai
海外独角兽:很多创业公司和大厂都在做与视频生成相关的事情,但在视频理解上,之前更多是 Google、OpenAI 这样的公司在做。背后的原因是什么?作为创业公司,你们为什么选择视频理解和记忆这个方向?
Shawn:Text-to-video 很简单直接,用户输入文字生成视频,视频能快速观看和消费,消费性强,增长快,容易获得关注。
但 video-to-text 不一样。首先 video-to-text 内容往往是大量文字,用户没看过视频,很难形成传播。其次,text-to-video 面向 C 端用户,而 video-to-text 多为 B2B 或 B2B2C,这意味着大多数应用公司无法做基础研究,却依赖基础研究开发功能。在最终整合时需要等应用层(application layer)逐步完善这些功能,再交给用户,用户反馈后再反向传递给模型或 infra。
而 text-to-video 的链路短,反馈更快。这两者的本质属性是完全不同的。
海外独角兽:我们和很多 AI researchers 交流过,大家普遍认为 memory 是实现 AGI 的关键要素,也是许多 AI agent 产品落地的基础条件之一。但目前 AI 在记忆方面其实比人类表现更强,主要技术挑战是什么?
Shawn:很多人把 memory 等同于文字记忆(textual memory),而我们做的是视觉记忆(visual memory),两者非常不同。大家关注的 AI agent memory 本质上是上下文工程(context engineering),并不是真正意义上的记忆。换言之,它是优化如何组合 context,给类似 ChatGPT 的模型更好输入,从而获得更好输出,本质还是输入输出优化。
而我们做的视觉记忆则是让 AI 真正理解并记住世界,就像人类一样。人类记忆不是上下文工程,而是信息进入大脑,被索引处理,最后存储到海马体,海马体还会抽象和遗忘。感兴趣的读者可搜索 Human-inspired Perspectives: A Survey on Al Long-term Memory。
感兴趣的读者可搜索“memory AI survey”,我们写的论文是第一篇。人类长期记忆分为程序性记忆(procedural memory)、情景记忆(episodic memory)和语义记忆(semantic memory)。情景记忆关于回溯,程序性记忆是“车有四个轮子”这类常识性操作。虽然有人试图用 text memory 模拟这三类记忆,但我认为那仍属于 context engineering 和 prompt engineering,不是真正人类记忆系统,也就是视觉进入大脑,存入海马体,后续可检索的记忆。
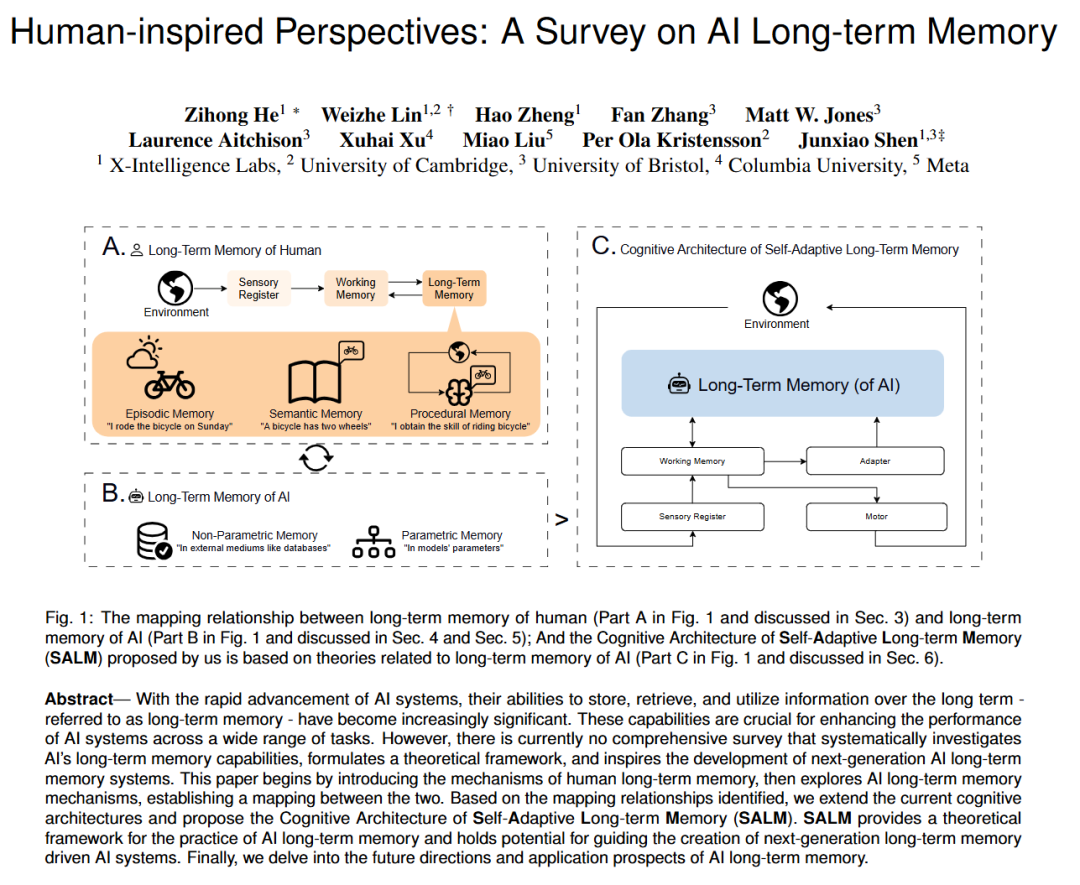
论文部分内容
上述论文系统地讲述了人类长时记忆的机制,随后探讨了 AI 长时记忆机制,并建立了二者之间的映射关系。基于此,作者提出了“Self-Adaptive Long-term Memory”(SALM)认知架构,作为引导下一代具备长期记忆驱动能力的 AI 系统的理论框架。文章最后还讨论了这一方向的未来研究方向与应用前景。
所以真正的记忆系统应该基于视觉。大模型最终可实现几乎无限的上下文本处理能力,只要 context engineering 做好,大模型的表现就越好,提升空间就不大。
现在大模型上下文长度可达百万 tokens,但仍存在问题,比如注意力机制导致的上下文腐败(context corruption),所以上下文工程依然核心。一旦这些技术解决,文本层面的提升将趋于饱和,这是第一点。第二,大语言模型对语言上下文处理较好,但视频的上下文则更难解决。视频一秒就有 30 帧,数据量极大,信噪比低,噪声多。形象来说,人能“一目十行”,但不能“一目十分钟电影”,只能快进,不能跳看,否则连续性断裂。
人能“一目十行”因知道中间会出现哪些字,有概率预期,这与大语言模型逐 token 生成类似,它也是一个 token 接着一个 token 的生成过程。但看电影时帧与帧间跳跃太强,难以理解,你只能快进。视频既承载大量信息,又包含很多噪声。所以想要理解视频的上下文,仅靠模型本身是很难做到的。人类理解视频也依赖“进度条”等外部工具,比如回看电影细节需拖动进度条。AI 也是如此。
海外独角兽:你提到 text memory 更像 memory engineering,偏向工程化,那你这么看视觉记忆的技术路径?如果不是工程,它会是什么样的解决方案?
Shawn:文字不是原始数据(raw data),它是被人类发明出来的。人类最初不会文字,但视频永远是 raw data。从视频到文字再到抽象的过程包含很多内容。我们研究的,就是如何完成这个抽象过程。从某种程度上说,这也是工程,但不同于文字的工程。
文字 memory 处理的数据量很小,比如所有微信聊天记录导出约 1 至 2GB,而我们每天看到的视频,如果转成 MP4 格式,肯定超过 5GB。文字数据噪声低,视频数据噪声高。我们要做的是将视频中的大量数据抽象出来,实现更好的理解、检索和问答,这涉及非常困难且庞大的基础设施工程。
海外独角兽:但这也引出了一个问题:是否有经历或观察让你们坚信视觉依然非常重要?尽管噪声多,但它可能成为下一代 AI 的核心模块或转折点?
Shawn:当然,这正是我们正在做的。我们认为今年是 agents 发展的年份,但明年或后年一定会是 multimodal agents 的时代。举例来说,现在所有 agent 公司其实都可以在产品中加入多模态输入和输出。
以 Lovable 为例,现在我们还是通过文字提示(prompt)它,但人类的工作方式不是这样。我与设计师或前端沟通时,通常开线上会议、分享屏幕,指出网站的某部分好并标注,再指出另一区域也标注,整个过程是多模态输入。所以我们称之为 multimodal prompting,最终输出也同样是多模态的。
Multimodal prompting 非常重要,它甚至可能改变很多交互范式。我们预计明年会有更多与模型提示相关的内容,比如 multimodal 输入。Multimodal AI 非常关键,因为它能解决许多人机交互中的摩擦和带宽问题。
海外独角兽:Memories 推出的 LVMM( Large Visual Memory Model)非常有冲击力,像一个设计精妙的模型系统。官网技术报告提到这是由多个模型组成的系统,且受到人类记忆系统启发。这个系统的设计理念是什么?哪些部分类似人类?哪些还达不到人类水平?
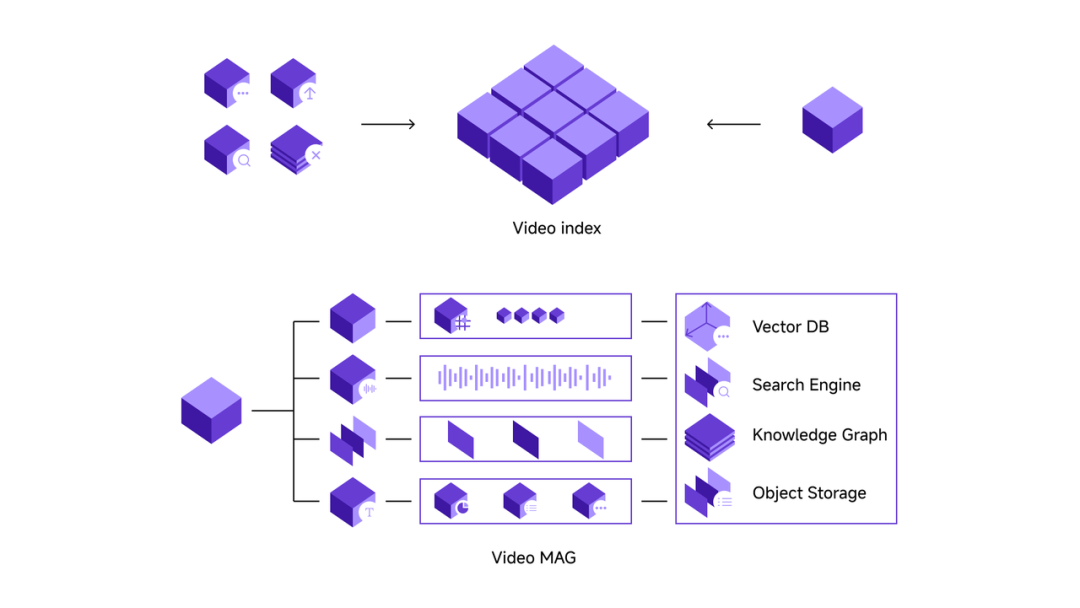
LVMM
Shawn:我们一开始就认为未来 AI 必须具备视觉记忆能力,因此花了两年研究人脑运作。了解到人脑有语义记忆(semantic memory)、程序性记忆(procedural memory)、长期记忆(long-term memory)、和情景记忆(episode memory)等多种记忆类型。在长期记忆部分,我们细致拆解每个组成部分作为独立模型,再将它们串联,就像人脑的联动机制。
目前还做不到的地方,一是人类擅长的“记忆重构与抽象”。人类记忆有极强连续性,会不断重构和抽象。比如学新知识如“车有四个轮子”或“汉堡是两个饼加一个肉”,是在生活中不断接触和学习形成的,不是隔夜突然学会的。我们称为持续学习(continued learning),更进一步是连续/终身学习(continuous/lifelong learning),而非离散学习(discrete learning)。这是第一个挑战。
第二是人类抽象能力强。面对杂乱信息能总结规律,抽象成自己的知识体系,称为聚合(aggregation)。我们已在系统中加入聚合模块,系统包含压缩、索引、聚合和调查。但整体上,我们的聚合能力仍与人类有差距。我们的学习过程仍是离散的,不是连续学习。另外,在回归(regression)方面,目前表现也达不到人类配置(configuration)时的细节水平。
海外独角兽:也就是说,我们现在有一个机制可以大致模拟人类记忆的形式,但还无法真正实现终身学习。这也是很多人追求的下一次范式转变,难度较大。另外,系统目前还不能像人类一样非常准确地检索信息。我在官网 Blog 里看到,有一个模型专门用来判断哪些信息重要,这算是系统中非常关键的环节吗?
Shawn:我们系统里的每个模块都很重要。你提到的“决定哪部分信息更重要”,在系统中称为 retrieval 和 reranking。这个过程与人脑机制非常类似。比如你问我一个问题,我会在脑中检索相关片段,判断哪些重要,最后挑选重要内容告诉你。人脑也有类似机制。
海外独角兽:既然每个环节都重要,哪些模型特别关键?它们分别起什么作用?
Shawn:大家可以想象人的工作流程。先接收原始数据,比如视频,先变成电信号,这过程叫解压层(decompression layer),即视频进来后进行分词(tokenization)。不过分词前,视频开发通常按比特率(bitrate)计算,视频有时动态,有时静态,这是第一步。
然后我们结合低级视觉(low-level vision)和高级视觉(high-level vision)对视频做压缩,接着做索引。我们将视频进行分词,用自己的分词器(tokenizer)。再往上是聚合模块,基于这些 tokens 进行聚合,采用特定规范做基于范式的聚合。最后是服务层,我们把所有 tokens 放进一个巨大数据库,供 agents 在此数据库上搜索和问答。
海外独角兽:你们的突破主要在哪些方面?
Shawn:这有点像从 GPT-1 到 GPT-3.5 的演进。概念上其实很简单,但关键是我们真正把它做出来了,做成了,做到了规模化运行。从演示(demo)到真正可用,再到规模化运行,这三者差别非常大。
海外独角兽:Memory 是一个庞大的数据集,包含很多噪声。比如我们现在开始与客户合作,积累 memory。从长远来看,无论以客户还是模型为单位,video memory 都会持续增长。未来我们如何应对这种增长?比如模型需要记住几个月甚至一整年的视频内容时,怎么处理?
Shawn:这不是端到端模型,它的数据是存在数据库里的。是否能处理增长,关键看我们的基础设施能力。我们的基建能力比较强,能处理大规模数据。现在数据库已达亿级规模,我们要支撑亿级数据库的问答,做到快速且精准,这非常难。
海外独角兽:这是不是因为你们团队来自 Meta Reality Labs,有大厂经验,知道如何搭建可承载大规模数据的基础设施?
Shawn:是的。
海外独角兽:发布的基准测试里也提到 Gemini 能处理的视频是有上限的,但你们的系统是没有上限的。
Shawn:是的,我们采用不同技术路径。Gemini 在多模态特别是视频理解领域表现领先,但我们的系统从一开始设计就是无上下文限制,所以在上下文处理和某些任务准确性上有优势。
海外独角兽:大模型体系中有个叫 RAG 的概念,类似大模型的外挂记忆。我们做的视觉记忆系统和 RAG 有何区别?或者它们有相似之处?
Shawn:其实差别很大。RAG 更多是上下文工程,本质是重新组合并打包所有 context,再给大模型处理。我们则是把所有数据 tokenize,由 VRM(Visual Retrieval Model)直接处理。工作路径完全不同。
海外独角兽:也就是说,这个系统对 VRM 和基础设施的要求,会比 RAG 高很多吗?
Shawn:是的。RAG 类似写文本笔记再加 prompt 交给大模型生成结果,而 VRM 包含视觉编码,需要决定如何“灌入”数据,两者差别很大。
海外独角兽:以前大家觉得只有 Google、Meta、字节这样的大公司才能搭建这种基础设施,但作为创业公司,我们能处理这么大规模的数据,这本身就很厉害。
Shawn:对,我们在基础设施上做得不错。团队成员都来自大厂,以前都在 Meta 的 Ads Team 工作过,有处理过亿级数据库的经验。
海外独角兽:提高模型记忆能力后,智能层面是不是也会提升多模态理解能力?
Shawn:理解、认知、行动这三个环节与记忆是平行的。记忆力一般的人可能知道这是一辆白车,记忆力好的人也能理解它。这说明理解和记忆是两个相对独立的能力。
当然,对某事理解越深,未来抽象能力越强,记忆力也会更好。比如神童擅长记忆扑克牌,是因为他们能把牌抽象成“心灵宫殿”结构,抽象能力强,长期记忆好。从某种程度上,这两个能力互相关联。短期内不一定同步,但长期来看,良好的理解有助于长期记忆。
海外独角兽:这个问题也和你之前提到的有关。我们在海量数据中检索真正相关信息。这个训练过程是否意味着需要为很多视频做字幕,积累高质量理解数据,从而提升模型理解能力?
Shawn:我们最大的两个模块是基础设施能力和数据。我们已经形成数据飞轮,进入各行业应用期。所有数据都扫了一遍并存数据库,这些数据本身非常有价值。
海外独角兽:前面提到的数据积累主要是视频数据,后续会加入语音、文本数据,包括安防场景中的传感器数据。这样,memory 不仅能“看见”,还能复刻某人经历的场景。
Shawn:都会有,不过我们先解决最难的部分。虽然当前场景是安防,但是我们已与多家公司合作,包括北美大公司。第二类是媒体,主要与短剧公司合作,涉及媒体资产管理、再生产和内容再利用。
第三类是 video marketing。国内有很多出海电商,我们已经索引了大量 TikTok 视频,搭建了属于我们的视频搜索和问答引擎。能查询最近流行产品视频及原因。普通人能抓住通用趋势,但长尾趋势难捕捉,而我们能做到,这是一个重要变革者。数据索引越多,AI 对内容理解越深。
应用场景
海外独角兽:你认为这项技术最有前景的应用场景有哪些?
Shawn:在安防领域,我们的技术用于 real-time straight detection,它可以基于之前的趋势和变化不断学习,提升 detection 的准确度。安防分为 B2C 和 B2B ,B2B 的安防价值更高,例如商场人流量统计、餐厅翻台率、顾客进店未被招呼比例、停车场车流和付费情况等,应用场景涵盖零售、楼宇、警察局、停车场、街道等。
媒体方面,我们与新媒体合作,帮短剧做拉片。一个短剧时间也很长,我们可精确到毫秒级人物信息,生成剧本或脚本,效果接近专业编剧。接着进行视频的自动生成,通过 AI 自动完成抽卡、理解、裁剪拼接,结合视频库自动再利用、剪辑、投流,形成完整方案。在短剧方面我们做整套解决方案。
另一面是视频营销。视频营销最大两个方面是“内容”和“内容生产者”。对于网红内容,关键是如何做出火视频、创意点如何、前三秒吸引点怎么设计。很多时候这些都靠人工观察或培养“网感”。比如推广不同产品要养不同账号,操作复杂。我们则索引所有最火 TikTok 视频,免去养号,直接查询。我们做的是视频搜索加问答引擎,本质是创意引擎,提供大量创意。
第二是找网红达人。比如可以直接问最近讨论唇膏的博主有哪些,生成名单。以前 TikTok 搜索“唇膏”会得到上百个视频,需逐个观看并记录。现在只需要直接问就能马上得到结果。这类似 Perplexity,Perplexity 能做的,在 Google 搜索也能,只不过 Perplexity 会帮你重新抽象、整理一遍。
我们接下来重点讲 AI 硬件。AI 硬件包括 Sam Altman 投资的项目,必然是带摄像头的、多模态的。多模态 AI 拥有视觉记忆的好处是可以让 AI 助手更个性化。我们目前也在和一些 AI 硬件公司合作,未来还会与头部 AI 硬件公司合作宣传,大家可以期待。
海外独角兽:之前看了你们 Demo 里的 agent,有一个是视频创作者,一个是视频营销者,本质上还是对已有视觉数据的再编排。去年和今年也有类似公司,如 Opus Clip 和 Creatify,他们吸收视觉数据后重新编排,帮用户剪辑或生成视频素材。相比他们,我们的服务能做到哪些进一步提升?
Shawn:我们和 AI 视频工具完全不形成竞争,我们是服务 AI 视频工具的,可以让他们的产品变得更好。我们的定位是 B2B Infra,可以把我们理解成云厂商,就像 Perplexity 调用的是 search API 一样。我今天还在和 Opus Clip 以及 Creatify 的创始人聊天,我们的目标是帮助他们提升产品。我们做的 video marketer 和 video editing agent 只是用来展示我们的能力,因为如果不做出来,别人也不知道我们能做到什么。
海外独角兽:能理解成你们做的是他们 agent 里的记忆模块吗?他们重点帮用户更快剪辑视频,你们帮判断什么创意好,比如最近最火的 hook,这层理解来自你们?
Shawn:这个我不能替他们说,但他们对用户理解很深,这部分我们不擅长。每个场景都是深度复杂细分领域,很多细节必须专门公司解决。我们提供兼容工具,甚至能和客户共创,解决部分疑难,但解决所有是不可能的。我们的定位很清晰,就是做 B2B Infra,赋能多模态 AI 公司,让他们产品更好。
海外独角兽:对于已经有 AI agent 的公司,你们是作为赋能他们的 Infra。如果是安防、短剧这类行业,本身没有 AI agent 或 model 公司,比如零售企业等传统行业,你们是不是直接服务这些客户?
Shawn:是的,我们直接做解决方案。
海外独角兽:你们做安防和终端设备场景。苹果 Siri 也想做类似事,但没说做视觉,可能只给建议或录声音。他们担心隐私风险。你们做视觉记忆,是否考虑隐私和伦理风险?
Shawn:伦理分析很难争论,信息或数据产生前就有伦理审查。隐私关键在于是否受监管。我们通过了 SOC 2 Type 1 和 Type 2,也在 GDPR 监管范围内。能被监管才是最重要的。
SOC 2 是一个审计框架,Type 1 评估在某一特定时间点的控制措施是否合理设计,而 Type 2 评估在一段时间内(通常为 3 至 12 个月)安全控制措施的有效性,确保安全措施不仅存在,而且能持续起作用。
GDPR 是欧盟的法律,规定企业必须告知用户数据会如何收集和使用,并确保用户可以控制自己的数据(比如查看、更正、删除)。无论公司在哪里,只要处理欧盟公民的数据,就必须遵守。
海外独角兽:我们前面讨论了安防、营销、消费,以及帮助 Opus Clip、Creatify 等AI视频工具做记忆层。你们目前认为未来这个技术最大的用例会是什么?还是说还在广泛试验阶段,没有明确答案?
Shawn:未来最大用例是 AI assistant 和类人机器人视觉记忆。AI assistant 能看到用户所见,拥有相同记忆,实现高度个性化。用户在底层,agent 在最上层,中间是 AI assistant,就像浏览器自动填账号信息,这就是 AI 系统。另一个重要方向是人机情感连接,机器人要像人一样,视觉记忆非常重要。
海外独角兽:目前有哪些瓶颈没解决?是硬件带宽、成本还是其他?
Shawn:要解决的问题还有很多,不同行业有不同问题。技术问题总能解决,关键是要明确真正的问题是什么。最难的是定义清楚要解决的具体问题。
海外独角兽:那如果未来发展到一定阶段,你们会一直做赋能所有行业的 Infra 层,还是会也想尝试做直接面向终端用户的大型应用?
Shawn:现在 Google、Microsoft、Nvidia 都在做生态,我们能不能走到那一步以后再看,但最终所有的公司一定会做生态。
海外独角兽:那可能现在只是创业初期,等时机成熟,就可以下场做 assistant 或者每个人的个性化服务。
Shawn:下场也不是像大厂那样。我们可能做一些应用,目的是让更多人理解这项技术能做什么,吸引创业者加入,甚至开源部分成果。这样大家觉得有趣,会一起共创,基于我们的基础设施做得更好,也会用我们开源内容优化。
海外独角兽:你和你的团队背景都很强,比如来自 Meta Reality Labs,促使你们从大厂出来创业的动力和契机是什么?
Shawn:当你觉得某技术一定会出现,但大公司推进太慢,你就想自己做得更快。Elon Musk 说得对,技术是人推动的。我们希望把这技术往前推进。
海外独角兽:从研发和设计 LVMM 的角度,你们是否希望支撑 agent 持续学习并理解世界的变化?
Shawn:肯定会,continuous/lifelong learning 非常重要。
海外独角兽:但目前这还是一个研究问题,短时间内没有特别好的解决方案。
Shawn:市场觉得这很酷也必须解决,但具体问题和方案在不断迭代:先有问题,方案不够好,再有新问题和新方案,交叉向上发展。我们现在主要场景包括:第一,CPA(周界防范报警)和各类安防场景,包括出海安防;第二,短剧和新媒体;第三,做 multimodal agents 及 AI verbs。这些领域的伙伴欢迎找我们共创共赢。
安防类比如卖安防摄像头的海康威视就是很典型的例子。
短剧的话除了大厂、大平台,内容工作室也会是我们的潜在合作伙伴,我们的涵盖范围包括编剧、制作到投流的全链路解决方案。
而且我们已经建立了一个庞大的视频索引库,覆盖了超过一百万个 TikTok 视频,可以为客户提供包括抖音、Meta、Instagram 和 YouTube 等平台的视频内容索引服务。通过对这些视频数据的深度分析和逆向工程,我们会帮助客户洞察爆款视频的关键因素,从而优化内容策略,实现营销和用户增长。
文章来自于微信公众号“海外独角兽”,作者是“Haina,Penny”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
