# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

在复杂的城市场景中,HERMES 不仅能准确预测未来三秒的车辆与环境动态(如红圈中标注的货车),还能对当前场景进行深度理解和问答(如准确识别出 “星巴克” 并描述路况)。

近年来,自动驾驶技术取得了令人瞩目的进展。要让智能汽车安全高效地行驶在复杂的真实道路上,车辆必须具备两大核心能力:对当前环境的深刻理解(例如识别交通参与者、理解交通规则、推理场景语义)以及对未来场景的准确预测(如预测行人、车辆的运动,提前规避风险)。
目前,学术界和工业界的主流方案往往将 “理解” 和 “生成” 分开处理:
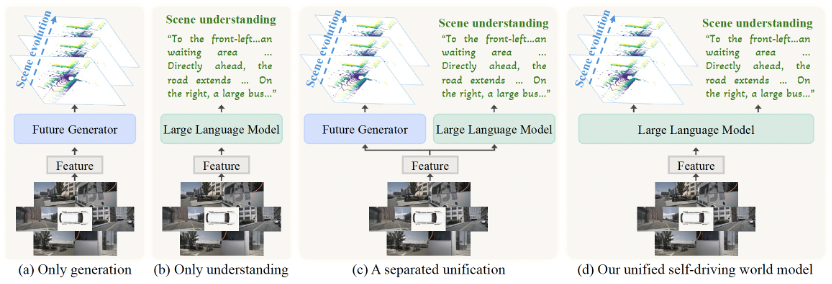
然而,现实中的自动驾驶决策,恰恰需要这两种能力的深度融合。例如,车辆不仅要能描述 “前方有行人正在通过斑马线”,还要能预测 “3 秒后这位行人将到达路中央,需提前减速”。
构建这样一个统一的模型面临着诸多挑战:
首先,如何将多达六路的高分辨率环视图像高效地输入给有 token 长度限制的 LLM,并保持空间信息不失真?
其次,如何在一个模型内,让 “理解” 和 “生成” 这两个看似独立的任务能够相互促进,而非相互干扰?如何将强大的世界知识与前瞻性的场景预测无缝集成到一个统一的框架中,成为亟需突破的难点。
面对上述挑战,HERMES 提出了一个统一框架,其核心设计思想是通过一个共享的 LLM,同时驱动理解与生成两大任务。
HERMES 的核心设计
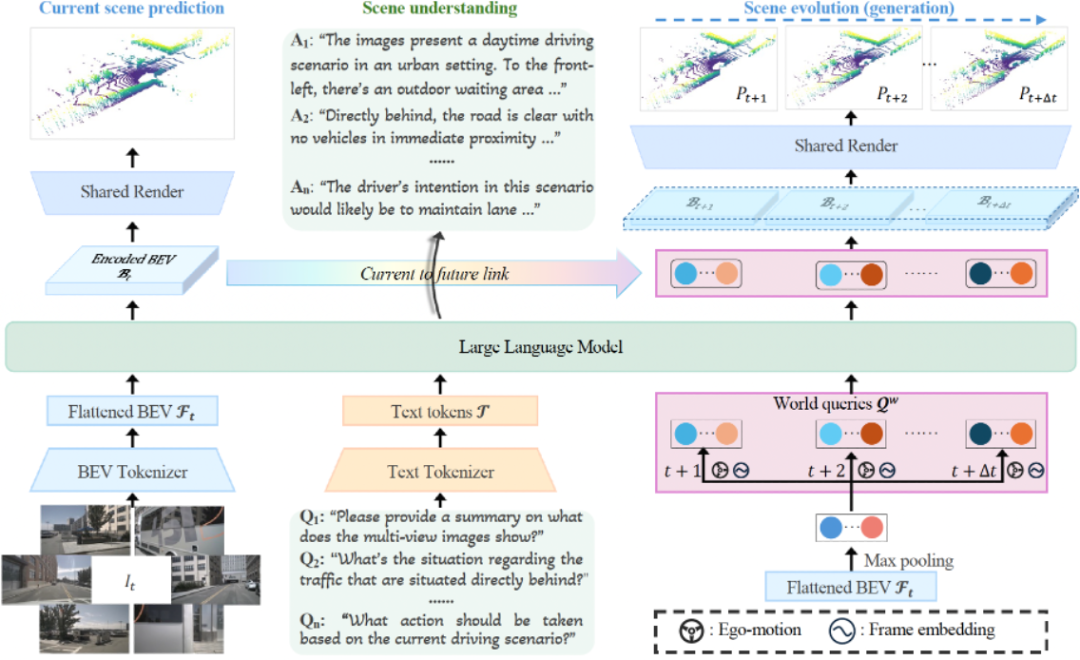
鸟瞰图(BEV)特征统一空间
HERMES 采用 Bird’s-Eye View(BEV,鸟瞰图)作为统一的场景表达。它首先通过一个 BEV Tokenizer 将六路环视图像高效地编码并投影到一个紧凑的俯视视角表征中。这种做法不仅有效解决了 LLM 输入长度的限制,更重要的是保留了多视图图像之间的精确空间几何关系和丰富的语义细节。无论后续任务是理解还是生成,模型都能在同一套高质量的 BEV 特征空间中自由切换,为后续的统一处理奠定了坚实基础。
世界查询与 “当前 - 未来” 连接
为了打破理解与生成之间的壁垒,HERMES 引入了世界查询(World Queries)机制。这是一组从 BEV 特征中通过自适应采样(如最大池化)提取出的、代表场景核心信息的可学习 Token。其工作流程如下:
1. 知识注入:将 BEV 特征通过自适应采样(如最大池化)转化为一组表达世界知识的查询向量,再把世界查询与 BEV 特征、用户文本指令一同被送入 LLM。在 LLM 处理语言理解任务(如回答问题)的过程中,世界查询通过因果注意力机制(causal attention)吸收和编码了关于当前场景的丰富世界知识和上下文信息。
2. 知识传递:经过 LLM 处理后,这些富含知识的世界查询被一个 “当前 - 未来” 连接模块(Current to Future Link)所使用。该模块通过交叉注意力将世界查询中蕴含的 “理解” 成果,有效地注入到对未来场景的预测中,引导模型生成未来多帧的 BEV 特征。
3. 统一输出:最终,一个共享的渲染器(Shared Render)将当前和未来的 BEV 特征解码为 3D 点云序列,同时完成对当前场景的理解和对未来场景的生成。
联合训练与优化
HERMES 的训练过程同样体现了其统一性。模型通过两个目标进行联合优化:
1. 语言建模损失:采用标准的 Next Token Prediction 损失函数,优化模型在场景理解、问答和描述任务上的能力。
2. 点云生成损失:采用 L1 损失函数,监督模型生成的当前及未来点云与真实点云之间的差异,优化生成精度。
通过这种端到端的联合训练,HERMES 得以在两个任务之间找到最佳平衡点,实现性能的协同提升。
多任务对比实验
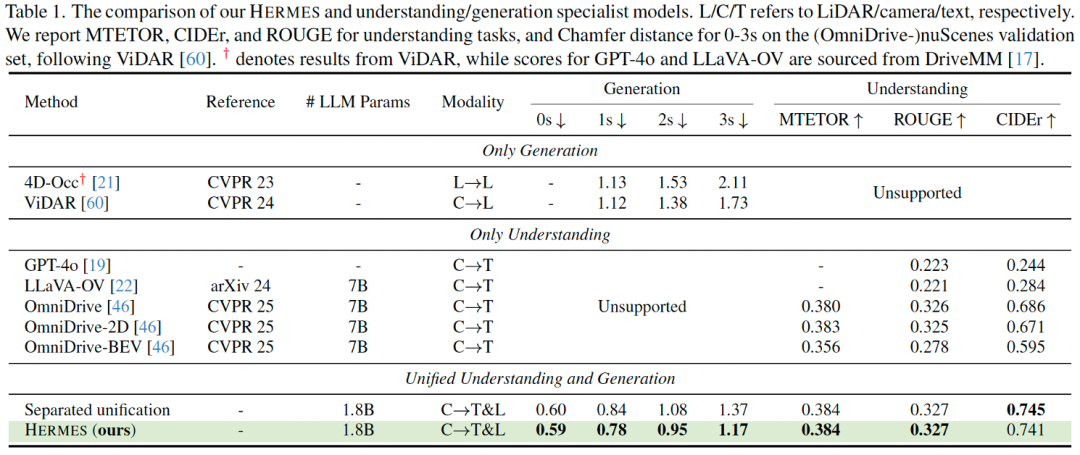
HERMES 在 nuScenes、OmniDrive-nuScenes 数据集上,评测了场景理解和未来生成两大任务。
可视化
HERMES 不仅能够生成时序连贯且几何精确的未来点云,还能对驾驶场景的细节进行精准描述。无论是预测动态物体的移动,还是识别路边的商家,HERMES 都展现出强大的综合能力。更多可视化结果请访问项目主页。

HERMES 为自动驾驶世界模型提供了一个简洁、有效且统一的新范式。它通过利用 BEV 表征和世界查询,成功弥合了 3D 场景理解与未来生成之间的鸿沟,为开发更智能、更可靠的自动驾驶系统迈出了坚实的一步。
未来,期望在此框架下进一步探索更复杂的感知任务,向着能够全面认知物理世界的通用驾驶大模型的目标不断迈进。
文章来自于微信公众号“机器之心”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
