# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

在大语言模型的竞争中,数学与代码推理能力已经成为最硬核的“分水岭”。从 OpenAI 最早将 RLHF 引入大模型训练,到 DeepSeek 提出 GRPO 算法,我们见证了强化学习在推理模型领域的巨大潜力。然而,想要复现这些顶尖成果,并不只是“多喂点数据、跑几轮训练”这么简单。现实是,很多中小规模的开源推理模型,在 AIME 这样的高难数学竞赛题、或 LiveCodeBench 这样的复杂代码评测中,依然与闭源 SOTA 存在明显差距。
最近,快手 Klear 语言大模型团队推出了全新的 Klear-Reasoner 模型,基于 Qwen3-8B-Base 打造,在数学与代码的多个权威基准测试中达到同规模模型的 SOTA 水平,并完整公开了训练细节与全流程 pipeline。

Klear-Reasoner 在 AIME2024、AIME2025、LiveCodeBench V5 和 V6 等基准测试中,不仅全面超越同规模的强力开源模型(包括 DeepSeek 蒸馏版 DeepSeek-R1-0528-8B),更是在 AIME2024 上取得了 90.5%、AIME2025 上取得了 83.2% 的惊人成绩,直接登顶 8B 模型榜首。
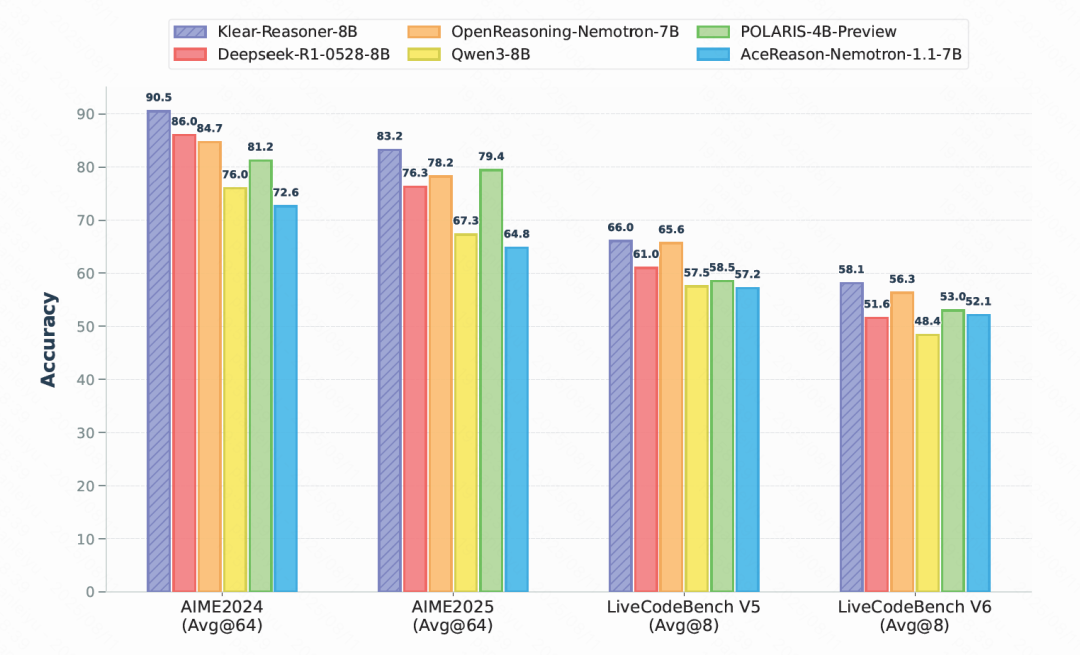
在这些成果的背后,最核心的技术创新是 Klear 团队提出的 GPPO(Gradient-Preserving Clipping Policy Optimization)算法 ——一种在保留训练稳定性的同时,大幅提升探索能力的强化学习优化方法。
在 PPO 和 GRPO 等常用的策略优化方法中,clip 是控制训练稳定性的重要手段,它通过限制策略更新幅度,避免模型一步走得太远而导致崩溃。然而,Klear 团队在实践中发现,这种做法有两个隐藏问题:
1.高熵 token 被裁剪:当高熵token(通常对应推理过程中的关键探索步骤)的重要性采样比例超过上限时,它们的梯度会被直接丢弃。这会限制模型的探索能力,使模型很快变得保守,不再尝试新的思路。
2.负样本延迟收敛:当次优轨迹的重要性采样比例低于下限时,梯度同样被丢弃掉。这样,模型需要多次重复犯同样的错误,才能积累足够信号去修正行为,显著拖慢收敛速度。
换句话说,clip 机制在保护稳定性的同时,也切断了模型获取最有价值学习信号的通道,模型变得保守,不敢尝试新路径,遇到错误也修正迟缓。
GPPO 方法:保留梯度的“温和”方案
GPPO 的核心思想很直接:不丢弃任何梯度,并且对其进行温和回传。它通过 stop gradient 操作,将 clip 操作与梯度反向传播解耦,在保持 clip 机制稳定性的同时,让被截断的 token 依然参与反向传播,其优化目标如下:
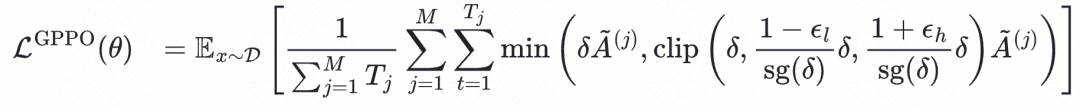
值得注意的是,数值上始终等于 1,因此前向计算保持不变。由于GPPO将梯度传播与裁剪约束解耦,所以反向计算过程与标准clip方法不同。通过分析GPPO梯度表达式,可以进一步明确其回传的梯度和标准clip方法的不同之处:
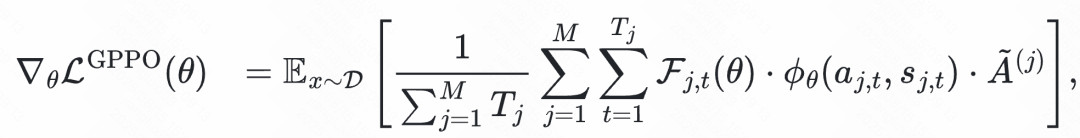
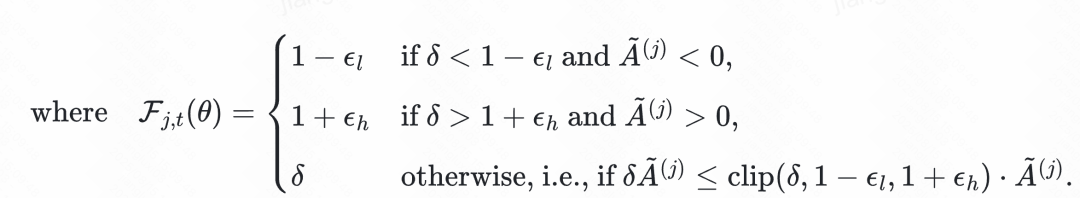
GPPO 让被 clip 的 token 依然参与反向传播。对于原本被clip的高熵token(正优势且),梯度被保留,并约束在水平,既能保留 探索能力,又避免过大更新引发不稳定;对于原本被clip的负样本token(负优势且<),梯度同样被保留,并限制在的幅度,加快错误修正。
如下图 1,在与现有方法的对比中(包括 DAPO 的 clip-higher 以及 MiniMax-M1 的 CISPO 方法),GPPO 在数学和代码任务上都表现出优势。DAPO 法调整 clip 上限,但无法解决本质问题,还是会存在高熵 token 被 clip 的情况;相比于 CISPO 方法,GPPO 继承了 PPO 悲观更新的策略,有助于其保持更清晰的优化信号,并促进更稳定的策略训练。
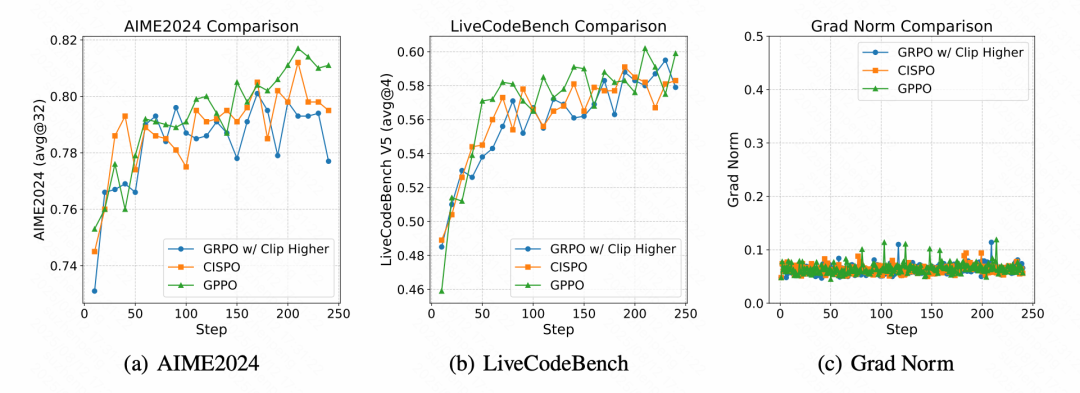
图 1: 数学强化学习训练中 GPPO、GRPO(带 Clip Higher 策略)与 CISPO 的对比
两种方法均基于早期长链思维微调检查点(序列长度32K tokens)进行训练。对于GRPO,我们采用DAPO论文推荐的Clip-Higher策略 = 0.28。
除了提出 GPPO 算法外,Klear 团队在论文中对训练流程的多个关键环节进行了深入实验与分析,揭示了长思维链推理模型成功背后的几个核心要素:
SFT 阶段:质量优先,数据可靠性比数量更重要
图片要在长思维链推理中实现强大的性能,优先考虑数据质量比简单地最大化表面的多样性更有效。实验表明,与数据量大但质量参差的数据源相比,来自少数高质量数据源的样本更具训练效率和效果优势。原因在于,高质量来源的数据往往封装了解决复杂任务所需的最有效、内部一致的推理模式,而添加低质量来源数据会不可避免地引入噪音,例如逻辑混乱、不正确的推导或低效的问题解决策略,从而在训练过程中影响模型的优化方向。如下表 1 和表 2,分别对数学和代码 TopK 优质数据源进行实验,仅来自 Top1 或者 Top2 的优质数据源取得了最好的成绩。
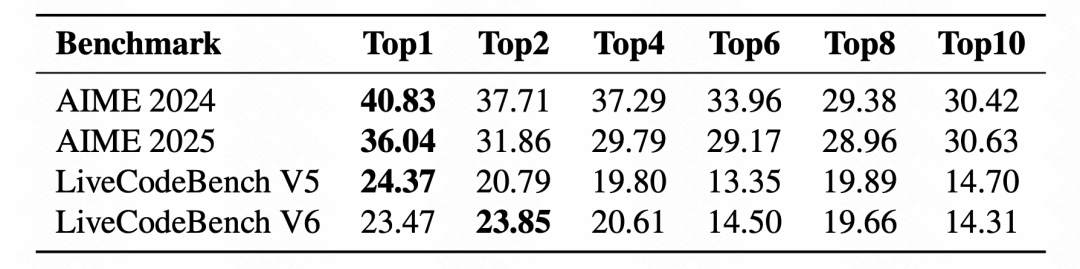
表 1: 高质量数学数据 Top-K 子集组合对监督微调(SFT)性能的影响
在每个 Top-K 配置下。加粗数值表示对应 Top-K 配置下的最佳性能表现。
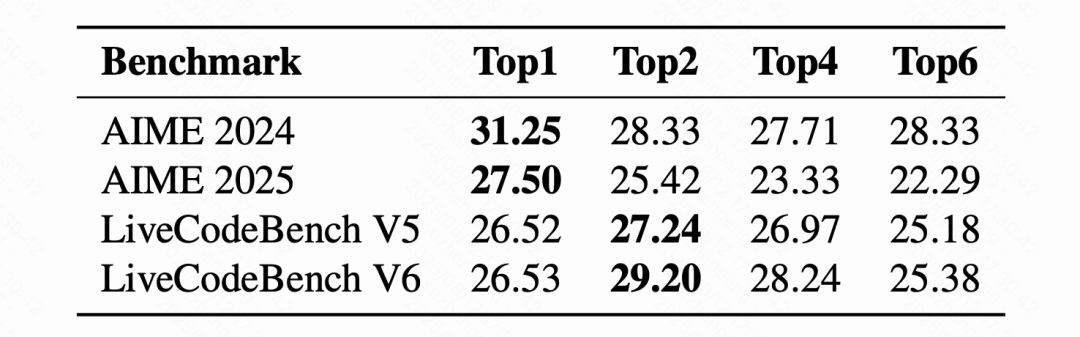
表 2: 高质量代码数据 Top-K 子集组合对监督微调(SFT)性能的影响
在每个 Top-K 配置下。加粗数值表示对应 Top-K 配置下的最佳性能表现。
SFT 阶段:高难样本容错反而能促进学习
图片对于简单任务,错误样本的引入会明显影响性能,但对于高难度任务,完全剔除推理链中有错误的样本未必是最优策略。相反,保留部分带瑕疵的推理路径,反而能够提升模型表现。这一看似反直觉的现象表明,在高不确定性、初始学习信号较弱的场景中,错误示例同样具有价值,它们为模型提供了更多在解题空间中的探索能力。如下表 3 所示,未对错误的简单样本过滤对性能损害明显,然而不对困难样本进行正确性过滤对性能却能有明显提升。
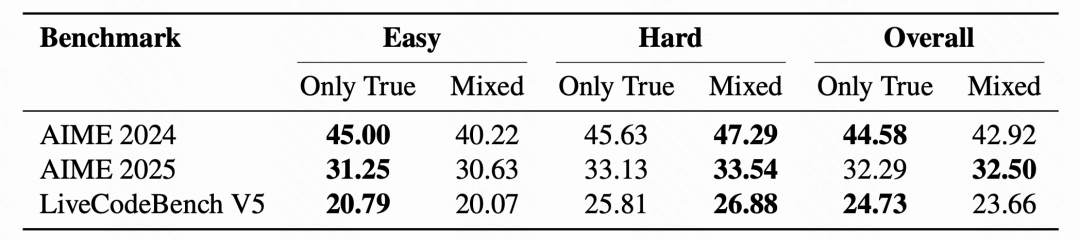
表 3: 通过三组实验分析了数据正确性对模型性能的影响。
分别在简单(Easy)、困难(Hard)和整体(Overall)任务集上对比了纯正确数据(Only True)与含错误数据的混合数据(Mixed)的表现差异。上述表格中加粗数值标识了各组内的最优性能结果。
RL 阶段:软奖励优于硬奖励
图片在代码任务的强化学习阶段,使用软奖励(根据通过测试用例的通过率)比硬奖励(完全通过得分,否则为零)更有效。如下图 2 所示,将测试用例的通过率作为奖励比直接用硬奖励取得了明显的改进。软奖励不仅缓解了奖励稀疏问题,还增加了训练信号的密度,降低了梯度估计的方差,让模型的学习过程更稳定、更高效。
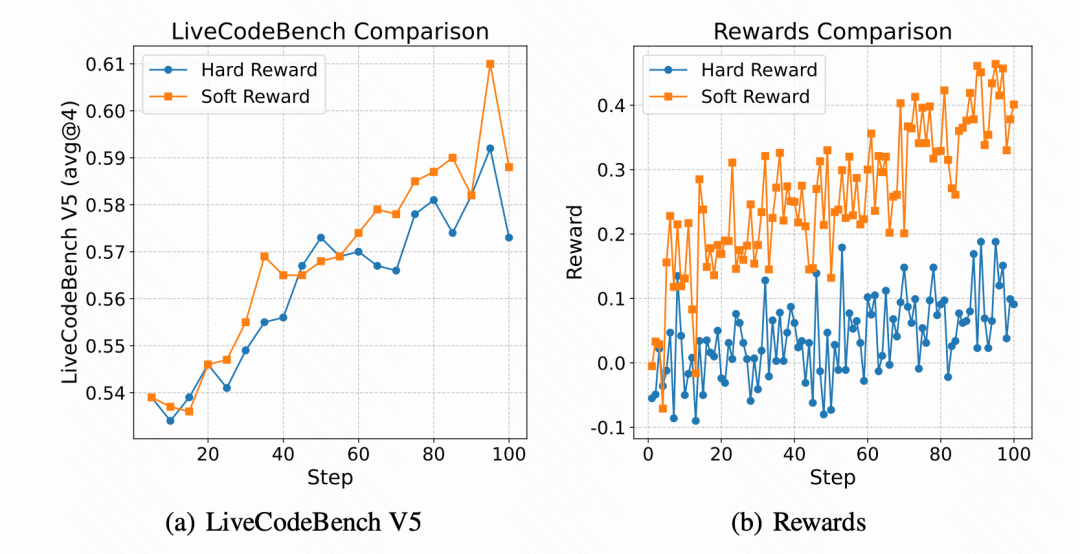
图 2: 代码强化学习中软奖励与硬奖励策略的对比
在软奖励设置中,奖励值等于测试用例通过率;而在硬奖励设置中,仅当所有测试用例均通过时给予正向奖励,否则给予负向奖励。
RL 阶段:代码数据测试用例过滤
开源的代码数据,有些数据的测试用例存在错误,即使是正确的代码也无法通过执行,这些数据会导致 RL 训练存在假阴的情况。为了过滤掉测试存在问题的数据,在代码 RL 数据准备阶段,Klear 团队调用 DeepSeek-R1-0120 为每个 prompt 生成了 16 条回复,只有 pass@16 大于 0.5 的数据会被保留。如下图 3 所示过滤能显著提升了 RL 训练的性能。
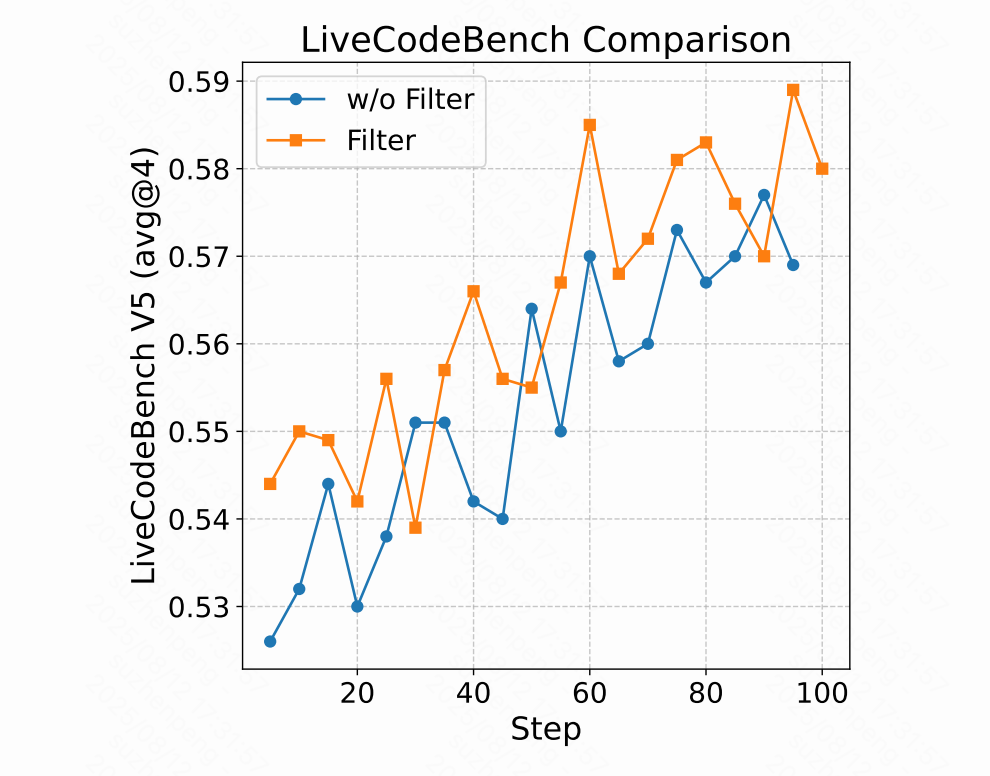
图 3: 在 LiveCodeBench V5 基准(avg@4 指标)上,使用过滤与未过滤数据的代码强化学习性能对 Filter 表示使用过滤数据的强化学习结果,而 w/o Filter 代表使用原始未过滤数据集的结果。
Klear-Reasoner 的推出,不仅是一份性能亮眼的开源权重,更为社区贡献了一条可复现、可推广的推理模型监督学习和强化学习路线。通过 GPPO,推理模型可以在稳定性与探索力之间找到新的平衡点,让它们既敢于尝试,也能迅速纠错。这对于未来的数学、代码,甚至其他 RLVR 任务,都有着重要的参考价值。
文章来自于微信公众号“AI前线”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
