# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

在移动计算时代,将高效的自然语言处理模型部署到资源受限的边缘设备上面临巨大挑战。这些场景通常要求严格的隐私合规、实时响应能力和多任务处理功能。
现有的 BERT 模型压缩技术仅能实现 15-20MB 的压缩,远不能满足移动设备 4MB 的严格内存限制。特别是在金融应用场景中,本地 AI 处理对保护用户隐私至关重要,同时还需确保约 300 毫秒的实时响应。这种差距凸显了对极致压缩框架的迫切需求。
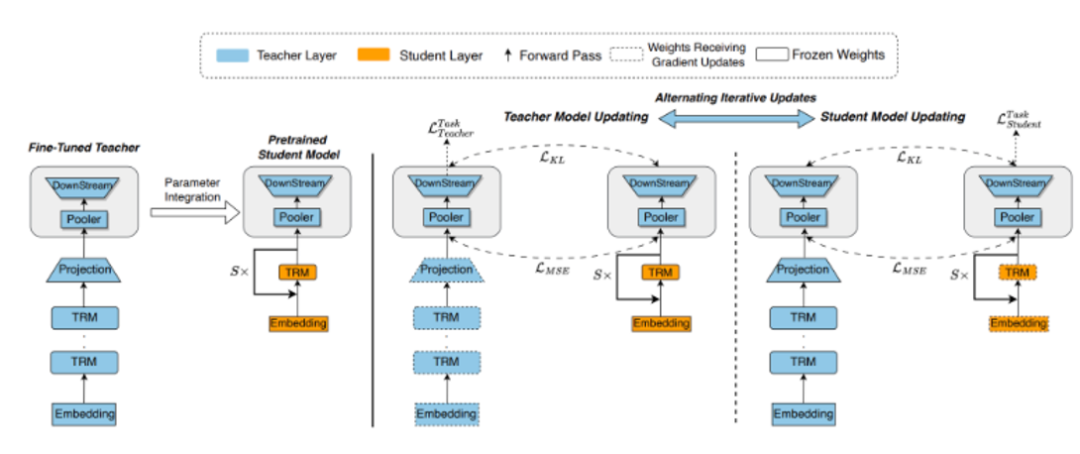
EI-BERT 框架通过三个关键步骤实现极致压缩:硬令牌剪枝智能筛选重要词汇,大幅减少存储需求;交叉蒸馏确保高效知识传递,突破传统方法局限;模块化量化采用 INT8 量化进一步优化存储。

其中,交叉蒸馏方法创新性地让教师模型 "站在学生模型的角度",通过参数集成和师生互动的动态适应机制,实现精准的知识转移。该方法有效解决了教师 - 学生模型间的容量差异和知识适应性问题。最终实现了 99.5% 的压缩率,创造了 1.91MB 的 BERT 模型新纪录。
词表剪枝
在传统模型中,词汇嵌入占据了大量参数空间(ALBERT-tiny2 达 44.7%,TinyBERT2 达 36.6%),严重制约了移动端部署。针对这一瓶颈,EI-BERT 框架基于注意力机制的硬令牌剪枝策略,通过精确建模量化每个 token 的重要性。
交叉蒸馏
传统知识蒸馏面临容量鸿沟和适应性缺失两大挑战。模型极致压缩导致的巨大架构差异使知识传递困难,静态教学方式也难以适应学生模型的特殊需求。EI-BERT 框架提出参数集成策略,将教师模型经过精调的下游任务层直接融入学生模型。这一 "拿来主义" 基于深刻洞察:教师模型末端层包含丰富的任务特定判别信息,直接集成可大幅降低学习难度。
在交叉蒸馏中,通过动态互动机制打破传统单向知识传递的局限。
模块化量化
完成蒸馏后,EI-BERT 框架采用创新的模块化量化方案将模型压缩至 INT8 精度。不同于传统逐矩阵量化,该方法从模块整体优化,最小化层间累积误差。通过精心设计的量化函数和可学习的步长参数,确保 8 位整数充分覆盖参数动态范围,在极大压缩存储空间的同时将精度损失降至最低。
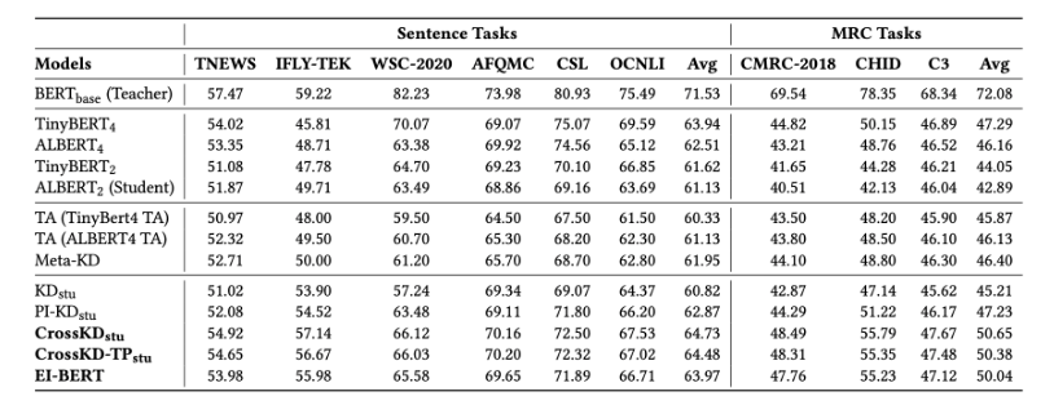
EI-BERT 在句子任务上平均得分 63.97,超越了所有基线模型;在机器阅读理解任务上得分 50.04,整体性能位居前列。
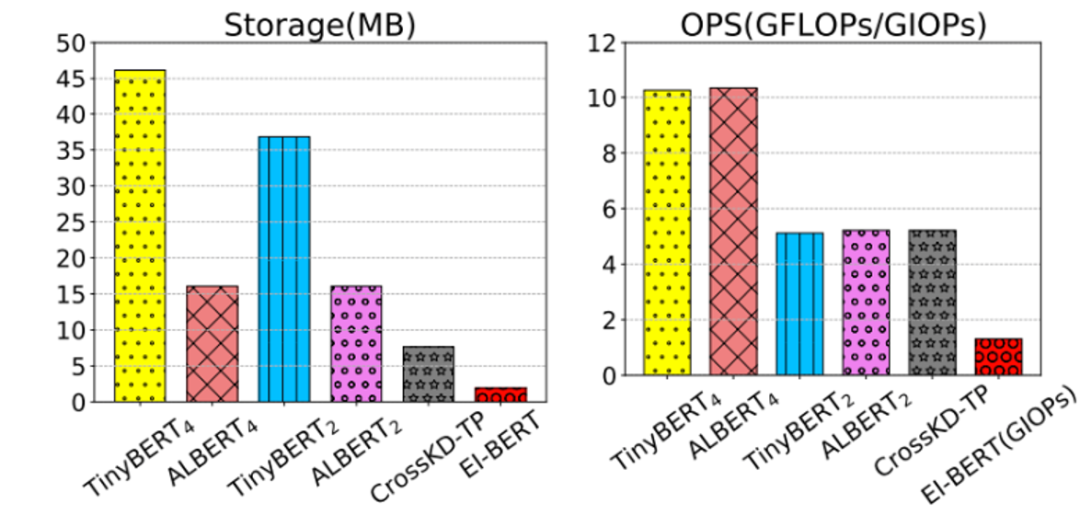
EI-BERT 以仅 1.91MB 的存储空间和 1.3 GIOPs 的计算量,实现了比 TinyBERT4 小 23 倍、比 ALBERT4 小 8 倍的极致压缩,同时计算效率提升 8 倍。
该技术已在支付宝生态系统中大规模部署,服务超 10 亿用户,展现出卓越的实际效果。在边缘推荐系统中,自 2024 年 1 月起每日服务 840 万活跃设备,处理 2100 万实时请求,PV-Click 提升 4.23%,PV-CTR 提升 3.3%;智能助手实现 65% 的延迟降低,响应时间从 1 秒降至 214 毫秒,同时保持 98.2% 的准确率;小程序场景实现完全本地化处理,网络负载减少 85%,云计算成本降低 40%,隐私敏感应用的用户留存率提升 12.3%。这些成果充分验证了该框架在真实工业场景中的巨大价值。
这项研究成功解决了在资源受限的移动设备上部署 NLU 模型的难题,在保证性能的同时实现了极致压缩,具有重要的学术价值和产业影响力。
未来,计划在两个方向继续推进研究:一是探索如何将生成式语言模型的核心能力 (如多步推理、上下文学习等) 通过压缩知识蒸馏迁移到极度受限的边缘设备上;二是研究参数高效的适应性方法,通过模块化接口设计实现快速的领域迁移。
文章来自于微信公众号“机器之心”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
