# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
人工智能的浪潮正将我们推向一个由 RAG 和 AI Agent 定义的新时代。然而,要让这些智能体真正「智能」,而非仅仅是信息的搬运工,就必须攻克一个横亘在所有顶尖团队面前的核心难题。这个难题,就是推理密集型信息检索(Reasoning-Intensive IR)。
它不仅是当前 RAG 和 AI Agent 技术发展的关键瓶颈,更对大模型智能体和深度研究(DeepResearch)等应用场景的成败具有决定性意义。
正当全球研究者都在为此寻求突破之际,我们看到了一项来自中国的贡献:BGE-Reasoner。
BGE-Reasoner 由来自中国科学技术大学、智源研究院、北京邮电大学与香港理工大学等机构的联合团队研发,是一套用于推理密集型信息检索任务的创新的端到端解决方案。通过系统性的查询理解、向量检索与重排序,该方案可显著提升搜索引擎在推理密集型信息检索任务中的表现。
在权威评测基准 BRIGHT 上,BGE-Reasoner 取得 45.2 的测试得分,以显著优势刷新了该基准的最佳纪录。
作为 BGE 系列模型的又一重要里程碑,BGE-Reasoner 不仅实现了性能上的突破,更为解决推理密集型检索这一行业难题提供了一套行之有效的新范式。从技术洞察来看,本次成果的核心创新主要体现在以下三个方面:
1.一个可复制的框架: 提出了一个由 Rewriter、Embedder 和 Reranker 组成的三阶段模块化框架,为处理复杂查询提供了清晰、高效的工程范式。
2.数据驱动创新: 探索并证明了利用大模型合成高质量、多领域推理训练数据的可行性,巧妙地解决了该领域训练数据稀缺的核心瓶颈。
3.强化学习赋能: 成功将强化学习应用于 Reranker 训练,让模型在面对困难样本时具备了更强的推理和泛化能力。
相关模型权重、训练代码及训练数据即将面向社区开放,进一步推动该领域的研究与应用发展。
项目主页:https://github.com/FlagOpen/FlagEmbedding/tree/master/research/BGE_Reasoner
推理密集型信息检索(Reasoning-Intensive IR)是近年来兴起的一类新型信息检索任务。与传统检索不同,它不仅依赖语义匹配,还需要综合运用深层逻辑推理、多步语义链以及相关背景知识,才能在查询与目标文档之间建立起正确的语义关联。
为推动该领域研究,香港大学、普林斯顿大学和斯坦福大学联合提出了首个面向推理密集型检索的权威评测基准 BRIGHT。该基准汇集了来自 StackExchange、LeetCode、数学竞赛等领域的真实查询,并将其与需要多步推理才能识别的相关文档进行配对,用于评估检索系统在复杂推理场景下的能力。
在 BRIGHT 基准下,传统依赖关键词匹配或简单语义相似度的方法往往难以定位真正相关的目标文档,暴露出当前检索系统在复杂推理场景中的不足。因此,如何在推理密集型检索中提升系统性能,成为推动检索增强生成(RAG)在复杂推理任务中发展的关键问题。
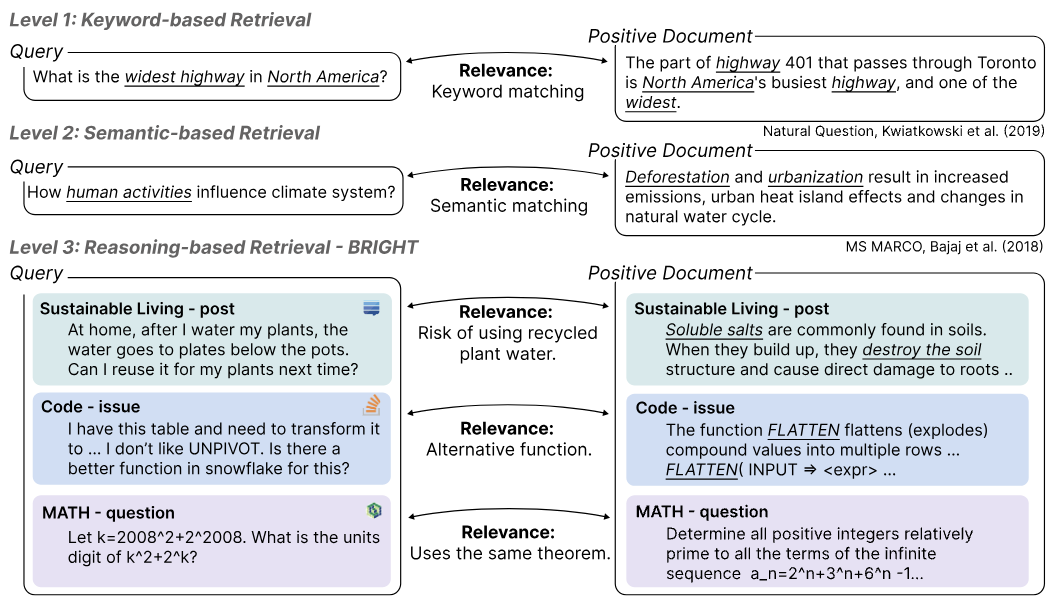
图 1. 不同于基于关键词和直接语义匹配的检索任务,BRIGHT 评测基准关注于推理密集型场景下的检索任务
在这一背景下,BGE-Reasoner 在推理密集型检索任务中展现出卓越性能。在 BRIGHT 榜单中,它超越了此前由蚂蚁、百度、字节跳动、人民大学、滑铁卢大学等机构提交的成果,并以领先第二名 3.6 分的优势刷新纪录。与此同时,其内置向量模型 BGE-Reasoner-Embed 也大幅超越了 Seed1.5-Embedding、Qwen3-Embedding、GTE 等当前最强基线模型,展现了显著的性能提升。
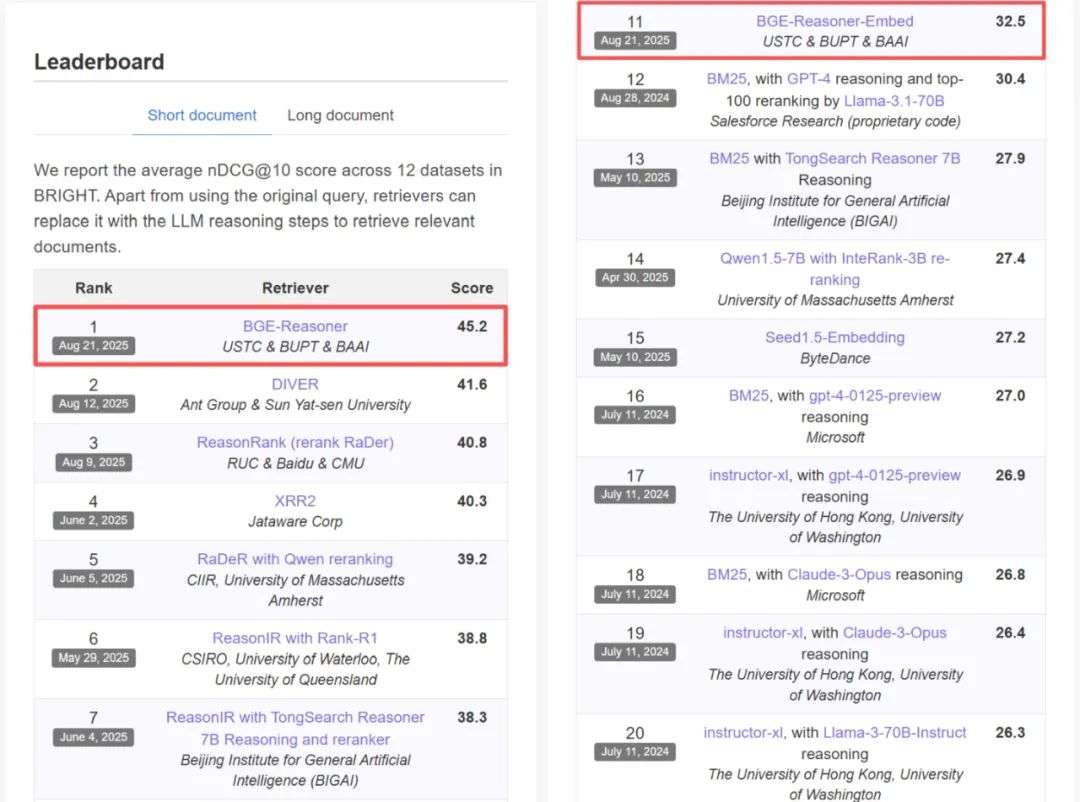
图 2. 在 BRIGHT 榜单上,BGE-Reasoner 取得 SOTA 表现于 8 月 21 日荣登第一名,BGE-Reasoner-Embed 使用原生查询即表现出色,在向量模型中取得 SOTA 结果,榜单链接:https://brightbenchmark.github.io
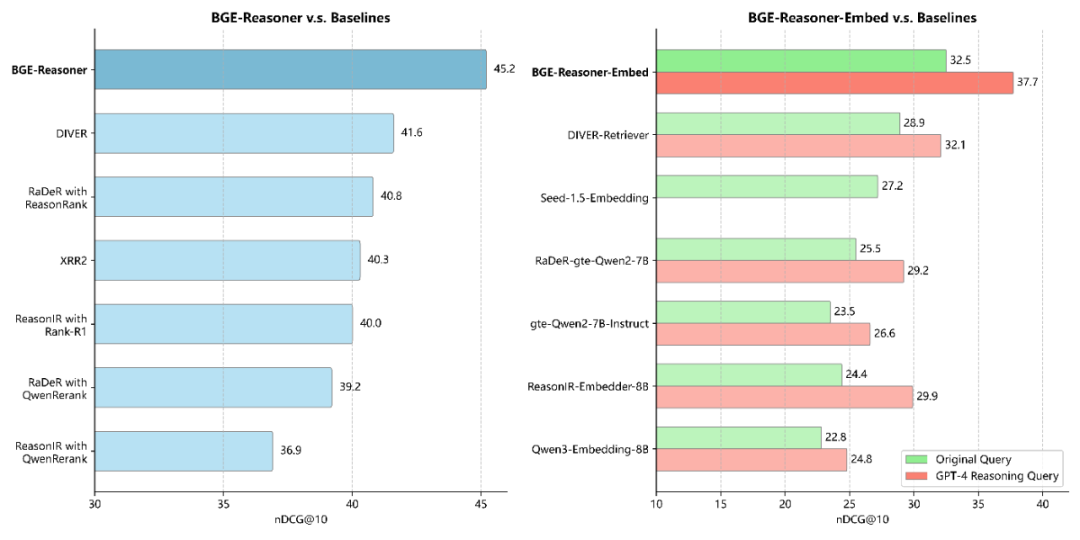
图 3. BGE-Reasoner 及 BGE-Reasoner-Embed 与基线模型在 BRIGHT 上的检索表现对比图
BGE-Reasoner 采用信息检索中的经典三模块体系:
在实际工作流程中,用户的原始查询首先经过 BGE-Reasoner-Rewriter 改写,然后由 BGE-Reasoner-Embed 与 BM25 并行检索得到候选文档,最后交由 BGE-Reasoner-Reranker 进行精排。系统通过集成多路结果,输出最终排序,完成端到端的推理式检索流程。完整框架如下图所示:
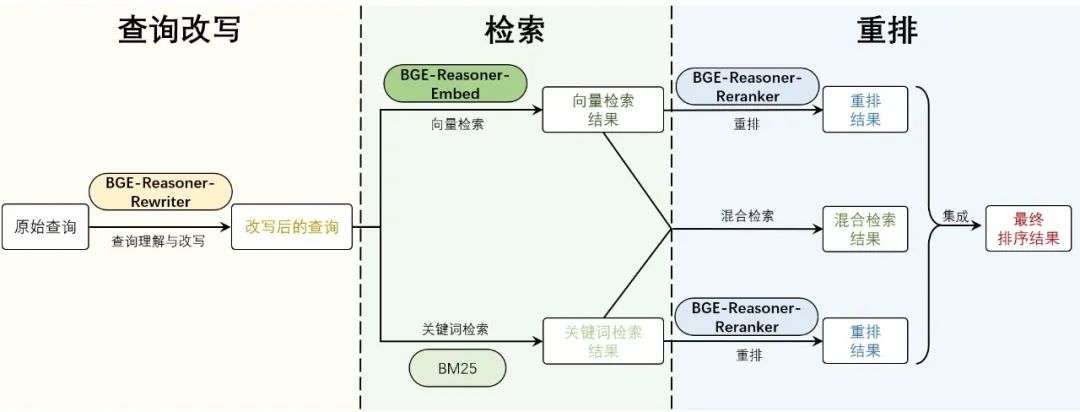
图 4. BGE-Reasoner 的端到端检索流程示意图
数据合成。不同于传统的开放式问答场景,推理密集型信息检索场景下的训练数据十分稀缺。为了解决这一问题,智源及合作机构的研究团队诉诸于基于大语言模型的数据合成策略。具体来说,基于现实场景中存在的知识密集型语料库,合成出针对特定场景的高质量推理密集型查询,然后借助于大语言模型强大的理解能力为每个查询构造出高质量的正例和负例。最终构造出一份覆盖数学、代码等多个领域的高质量推理密集型检索训练数据,为后续各个模块的训练提供支撑。
查询理解。在查询理解模块中,研究人员基于前述合成数据,借助推理能力较强的教师模型生成多条推理路径,并通过拒绝采样策略筛选高质量结果以构建训练样本。随后,利用这些训练数据对 Qwen2.5-7B-Instruct 模型进行微调,从而显著提升其在查询理解与改写方面的能力,最终得到 BGE-Reasoner-Rewriter。
向量模型。内嵌的向量模型 BGE-Reasoner-Embed 基于 Qwen3-8B 基座模型进行微调。依托高质量的合成训练数据,模型在推理密集型检索任务中的能力得到了显著增强。在 BRIGHT 基准下,无论是基于原始查询还是 GPT-4 推理查询,BGE-Reasoner-Embed 均取得了当前向量模型中的最佳检索表现,充分验证了所构建合成数据的有效性。
排序模型。内嵌的排序模型 BGE-Reasoner-Reranker 基于 Qwen3 系列基座模型进行微调。结合任务场景下的相关性定义,模型能够在查询与候选文档之间展开细粒度推理,识别关键信息片段并准确评估相关性。在训练过程中,引入强化学习以提升模型在困难样本上的推理能力;在推理阶段,模型通过测试时扩展(test-time augmentation)获取更加稳健的相关性评分,从而进一步增强排序性能。
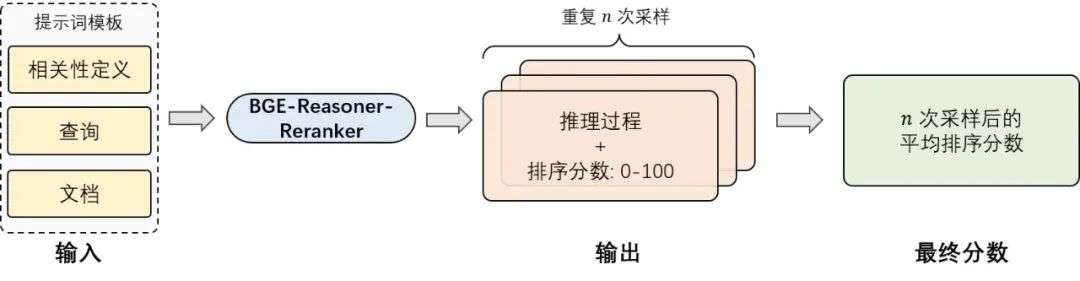
图 5. BGE-Reasoner-Reranker 的推理过程示意图
BGE-Reasoner 的卓越表现充分验证了强化学习与合成数据在推理密集型信息检索中的重要作用,为未来 Agent Search 的发展提供了关键支撑。
智源研究院将持续深耕向量模型与检索增强技术,不断提升 BGE 系列模型的能力与通用性。未来期待与更多科研机构及产业伙伴合作,共同推动检索与人工智能的发展,欢迎研究者与开发者关注并使用 BGE 系列模型,共建开放繁荣的开源生态。
文章来自于微信公众号“机器之心”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
