# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
腾讯混元,刚刚又拿下一个国际冠军——
Hunyuan-MT-7B,以7B总参数量获得国际翻译比赛冠军。该模型支持33个语种、5种民汉语言/方言互译,是一个能力全面的轻量级翻译模型。
并且,腾讯混元还把这个模型开源了。
同时开源的还有一个翻译集成模型 Hunyuan-MT-Chimera-7B (奇美拉),是业界首个翻译集成模型,它能够根据原文和多个翻译模型给出的不同内容,再生成一个更优的翻译结果,不仅原生支持Hunyuan-MT-7B,也支持接入Deepseek等模型,对于一些有专业翻译需求的用户和场景,可以提供更加准确的回复:

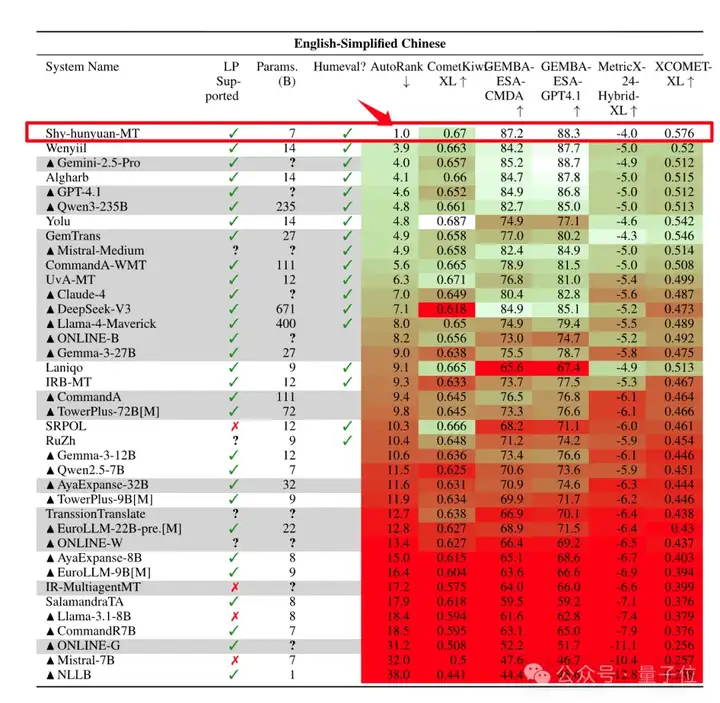
在8月底结束的国际计算语言学协会(ACL)WMT2025比赛中,腾讯混元Hunyuan-MT-7B(Shy-hunyuan-MT)拿下了全部31个语种比赛中的30个第1名,处于绝对领先地位,这31个语种除了中文、英语、日语等常见语种,也包含捷克语、马拉地语、爱沙尼亚语、冰岛语等小语种。
WMT25竞赛对参赛模型的参数规模有明确限制,要求系统满足开源要求,并且只能使用公开数据进行训练,在这样的环境下,Hunyuan-MT-7B击败了众多参数更大的模型。
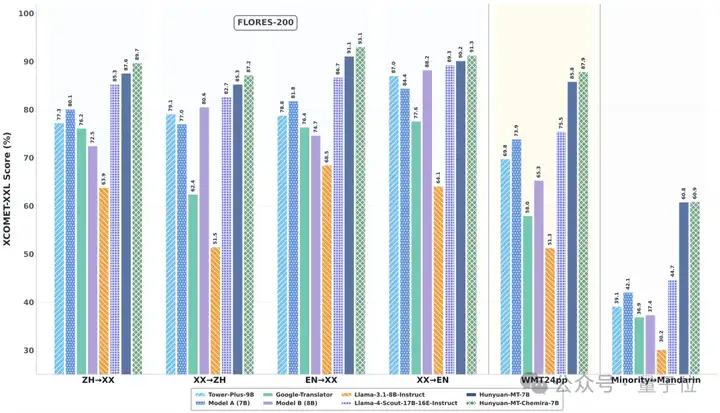
△同尺寸模型下,Hunyuan-MT-7B效果领先于业界顶尖模型
在业界常用的翻译能力测评数据集 Flores200上,腾讯混元Hunyuan-MT-7B模型也有卓越的效果表现,明显领先于同尺寸模型,与超大尺寸模型效果对比也不逊色。
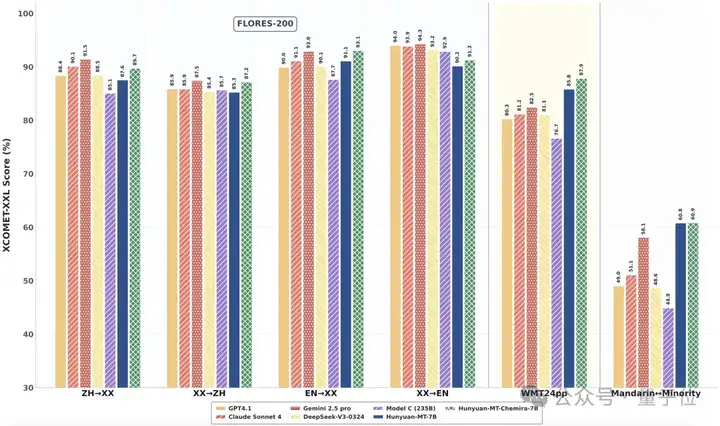
△Hunyuan-MT-7B效果与超大尺寸模型效果对比也不逊色
CASE展示:
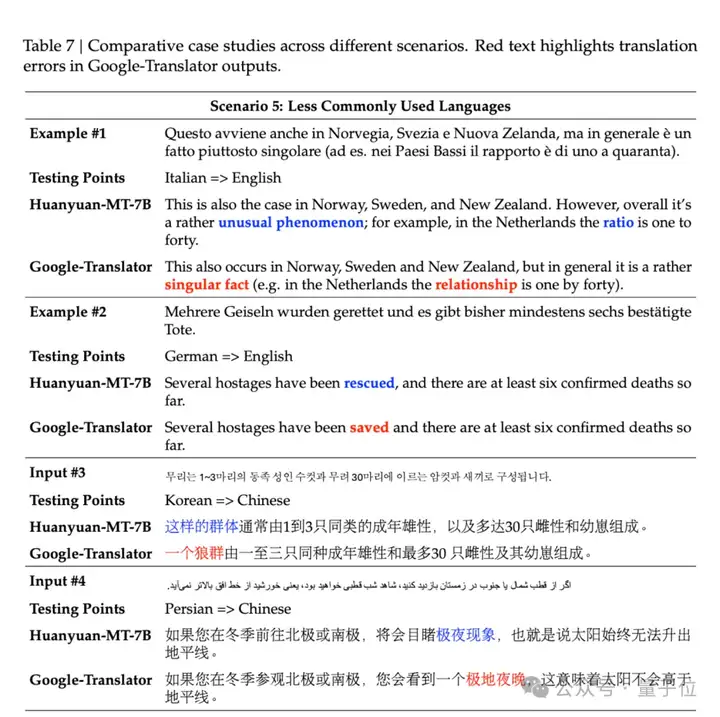
全面领先的成绩背后,针对翻译场景,腾讯混元提出了一个完整的翻译模型训练范式,覆盖从预训练、到CPT再到监督调参、翻译强化和集成强化全链条,使得模型的翻译效果达到业界最优。
具体来说,包括框架上的三大创新。
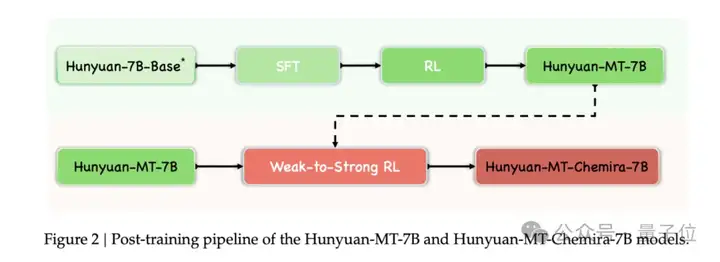
hunyuan-MT-7B的核心是一个名为Shy(Synergy-enhanced policy optimization,协同增强策略优化)的完整框架。这个框架最大的特点是采用两大组成部分协同工作的系统性设计,从根本上改变了传统单一模型的优化思路。
第一个组成部分是基础模型开发,通过三个递进阶段构建高质量翻译模型。
首先是持续预训练阶段,在OPUS Collection、ParaCrawl、UN Parallel Corpus等大规模平行语料上进行领域适应,将通用的Hunyuan-7B模型系统性地转化为翻译专用模型。
接着是监督微调阶段,通过知识蒸馏,基于WMT历史数据集进行训练,从多个顶尖开源模型中采样合成了高质量的SFT训练数据指导基础模型学习,并采用线性预热、梯度裁剪、混合精度训练等技术防止灾难性遗忘,并实施分层学习率衰减增强模型适应性。
最后是GRPO强化学习优化阶段设计是整个框架的技术亮点之一,下面会重点介绍。
第二个组成部分是集成策略,在基础模型的基础上通过多模型协同进一步提升性能。
这个部分的创新点是学习型集成(learned ensemble)优化,通过调整温度、随机种子、束搜索宽度生成5个候选翻译,然后训练专门的GRPO模型进行候选选择或组合。
两个组成部分相互配合,基础模型开发为集成策略提供了核心模型,而集成策略则通过学习型集成进一步优化最终输出。
在Shy框架中,最具技术创新性的是GRPO(Group Relative Policy Optimization,组相对策略优化)算法的采用,这是该算法在机器翻译领域的成功应用,为序列生成任务提供了全新的优化范式。
传统的PPO(Proximal Policy Optimization)算法使用全局基线进行策略优化,但这种方法在机器翻译任务中容易产生高方差,导致训练不稳定。
GRPO算法的核心创新在于采用组内相对优势而非全局基线进行策略更新。这种设计带来了显著的技术优势。
首先是梯度方差的大幅降低,使得训练过程更加稳定。
其次是样本效率的提升,通过充分利用组内信息,加速了模型收敛。
Shy框架中的GRPO算法还采用了精心设计的复合奖励函数:r = 0.2×BLEU + 0.4×XCOMET + 0.4×DeepSeek。这个函数融合了传统的BLEU指标、语义质量评估的XCOMET指标和流畅性评估的DeepSeek指标,解决了单一指标优化的局限性,确保生成的翻译在准确性、流畅性和语义质量方面都能达到较高水准。
传统的模型集成方法通常依赖启发式规则,比如简单投票或固定权重融合。Shy框架中的学习型集成则完全不同——它训练专门的模型来进行智能选择,实现了从启发式方法到学习型方法的重要跃升。
这个过程分为两个关键步骤。
首先是多样性生成,通过调节温度参数(T=0.5, 1.0, 1.5)、改变随机种子、调整束搜索宽度等策略,生成多个具有不同特点的候选翻译。这些候选覆盖了从保守到创新、从准确到流畅的不同权衡点,为后续的智能选择提供了丰富的选项。
接下来是智能选择机制,这是整个集成策略的核心。系统训练一个专门的GRPO模型来进行候选选择或组合,这个模型可以根据具体的翻译任务和语言对特点,动态地选择最优候选或者通过注意力机制生成优于所有候选的新翻译。
这种端到端的优化设计使得集成选择过程与翻译生成过程能够联合优化,不仅提升了最终的翻译质量,还实现了候选多样性与质量的最佳平衡。相比传统的启发式集成方法,学习型集成展现出了更强的适应性和更好的性能表现。
WMT25竞赛的结果为hunyuan-MT-7B的技术实力提供了最有力的证明。在31个语言方向的翻译任务中,该模型取得了绝大多数(30GE)第一名的成绩,AutoRank达到满分1.0。这个成绩的含金量在于其全面性——不仅在英德、英法等高资源语言对上表现优异,在英语-马拉地语、英语-埃及阿拉伯语等低资源语言对上同样表现稳健。
更值得关注的是,这一成绩是在严格约束条件下取得的。WMT25竞赛对参数规模有明确限制(≤20B),要求系统满足开源要求,并且只能使用公开数据进行训练。在这样的“公平竞争”环境下,hunyuan-MT-7B以7B的参数规模击败了众多更大规模的系统,充分证明了技术方案的先进性。
Hunyuan-MT-7B的特点在于仅用少量的参数,就达到甚至超过了更大规模模型的效果,这也为模型的应用带来了众多优势。
首先是计算效率,7B模型的推理速度明显快于大型模型,在相同硬件条件下能够处理更多的翻译请求,并且,基于腾讯自研的AngelSlim大模型压缩工具对Hunyuan-MT-7B进行FP8量化压缩,推理性能进一步提升30%。
其次是部署友好性,Hunyuan-MT-7B能够在更多样化的硬件环境中部署,从高端服务器到边缘设备都能良好运行,并且模型的部署成本、运行成本和维护成本都相对更低,在保证翻译质量的前提下,为企业和开发者提供了更具吸引力的解决方案。
相比传统的机器翻译,基于大模型的翻译对于对话背景、上下文内容以及综合的翻译需求有更深度的了解,进而能够提供更加准确和“信达雅”的翻译,这也为翻译模型的落地应用打下了基础。目前,腾讯混元翻译模型已经接入腾讯多个业务,包括腾讯会议、企业微信、QQ浏览器、翻译君翻译、腾讯海外客服翻译等,助力产品体验提升。
另外,hunyuan-MT-7B的一个重要特点是完全基于开源生态构建。
该项目使用Hunyuan-7B作为基础模型,训练数据来源于OPUS Collection、ParaCrawl、UN Parallel Corpus等公开数据集,以及WMT历史数据。
基于开源模型和公开数据的技术路径具有多重优势。首先是透明性,便于研究者和开发者理解和验证技术方案。其次是可扩展性,基于成熟的开源生态,其他团队可以在此基础上进行进一步的改进和优化。
这种开源基础还降低了技术门槛。相比需要大量私有数据和专有技术的闭源方案,基于开源生态的技术路径让更多的研究者和开发者能够参与到机器翻译技术的发展中来。这对于整个AI社区的技术进步具有重要意义。
hunyuan-MT-7B的技术价值不仅在于在机器翻译任务上的优异表现,更在于为其他垂直领域的专业化优化提供了可借鉴的方法论模板。
Shy框架的设计思路,即两大组成部分协同工作、基础模型开发与集成策略相结合,具有很高的参考价值。
这个方法论模板的核心思想是系统性优化。相较于简单地在通用模型基础上进行微调, Shy框架从数据、算法、架构等多个维度进行系统性的设计和优化。GRPO算法的成功应用证明了强化学习在序列生成任务中的巨大潜力,学习型集成的创新则为模型融合提供了新的思路其他垂直领域都可以参考Shy框架的设计思路,结合具体领域的特点进行适配和优化。这种方法论的推广应用,有望推动更多垂直领域实现从通用到专精的技术跃升。
体验地址:https://hunyuan.tencent.com/modelSquare/home/list
Github: https://github.com/Tencent-Hunyuan/Hunyuan-MT/
HugginFace: https://huggingface.co/collections/tencent/hunyuan-mt-68b42f76d473f82798882597
AngelSlim压缩工具:https://github.com/Tencent/AngelSlim
文章来自于“量子位”,作者“腾讯混元团队”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
