# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
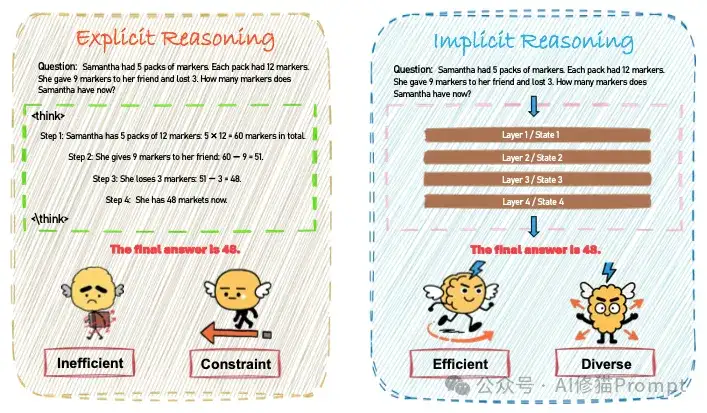
您对“思维链”(Chain-of-Thought)肯定不陌生,从最早的GPT-o1到后来震惊世界的Deepseek-R1,它通过让模型输出详细的思考步骤,确实解决了许多复杂的推理问题。但您肯定也为它那冗长的输出、高昂的API费用和感人的延迟头疼过,这些在产品落地时都是实实在在的阻碍。那么,有没有一种可能,让模型在自己的“脑子”里完成这些复杂的思考,然后干净利落地给出我们想要的答案呢?

这就是AI领域目前最新的研究方向隐性推理(Implicit Reasoning),很可能是继显式推理之后下一代模型的主流技术范式,来自港科大的研究者们为这一新兴领域提供了一个全面而系统的蓝图,建议仔细认真看一下。它就像人类的“默想”,在脑海里完成一系列复杂的计算和推演,最后只输出一个结果,而不是把每一步都自言自语地念叨出来。研究者们之所以投入巨大精力探索它,是因为它直指当前大模型应用的核心痛点:在保持强大推理能力的同时,实现更高的效率和更低的成本,这对于任何一个追求性能和用户体验的AI产品来说,都太重要了。https://arxiv.org/abs/2509.02350

为了让您更直观地理解,研究者们首先对LLM推理进行了定义,然后做了一个非常形象的对比。

模型根据输入的问题 x,在内部生成一个包含 M 个中间步骤的“推理轨迹”(internal trace),记为 z1:M。模型根据原始问题 x 和刚刚生成的推理轨迹 z1:M,共同推导出最终的答案,这个公式告诉我们任何推理都离不开一个中间的“思考过程” z1:M。显性推理和隐性推理的根本区别,就在于这个 z1:M 是否以文本形式被我们看到。
显性推理(如思维链 CoT)就是上述通用框架的一个特例,它的“推理轨迹”是我们能读懂的文字步骤y1:T:这里用 y 来特指文本形式的推理步骤(例如,“步骤1:5 x 12 = 60...”)。它就是通用框架里z1:M 的一个具体化身。模型首先生成一段看得见的、自言自语式的思考草稿 y1:T,然后在这份草稿的指导下,得出最终答案 a。

这是我们熟悉的方式,比如思维链(CoT),模型在回答复杂问题时,会先生成一系列中间步骤的自然语言解释,然后给出最终答案。
相应的,隐性推理是通用框架的另一个特例,它的“推理轨迹”是模型内部的隐藏状态,我们是看不到的。h1:L这里用 h 来特指隐藏的内部状态序列(例如,神经网络的激活值、潜令牌等)。它也是通用框架里z1:M 的具体化身,但对用户是不可见的。模型首先在内部生成一个我们看不见的、在潜空间中的思考过程 h1:L,然后直接利用这个内部思考过程,生成最终答案a。

这是一种更高效的推理方式。模型在接收到问题后,直接在内部的隐藏状态或“潜空间”(latent space)中进行多步计算和推理,最终只输出答案,而不会生成任何中间文本。这好比人在心里默想,最后直接给出结论。
听起来很神奇,但模型是如何做到在内部“思考”的呢?研究者们通过梳理现有工作,总结出了三条主流的技术路径,每一种都为我们打开了一扇观察模型“心智”的窗户。这部分是整篇论文的精华,研究者们还提供了一个会持续更新的GitHub仓库,感兴趣您可以关注下https://github.com/digailab/awesome-llm-implicit-reasoning
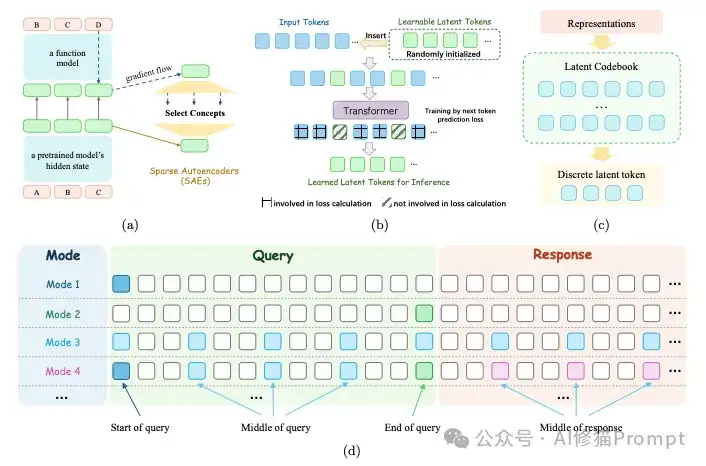
第一种玩法,研究者称之为“潜在优化”(Latent Optimization),这可能是最符合我们对“思考”直觉的一种方式。它的核心思想是,既然思考发生在神经网络内部,那我们干脆就直接在模型的潜在空间(latent space),也就是那些高维向量构成的“神经信号”海洋里进行操作和优化,直接调整和优化模型内部的表示(representations),来提升推理能力,整个过程不产生任何中间文本输出。这种方法根据操作的粒度,又可以细分为三个层次:

第二种思路就更直接了,叫“信号引导控制”(Signal-Guided Control),您可以把它想象成在和模型对话时,给它一些特殊的“指令”或“暗号”。这些指令不构成任何实质内容,但能告诉模型在某个节点上应该如何分配它的计算资源,比如是快速回答还是需要“多想一会儿”。最典型的例子就是引入一个[THINK]或[PAUSE]这样的特殊令牌,模型在处理到它时,就会在内部进行更多的计算迭代,但表面上却什么都没输出,从而在不增加输出长度的情况下提升了回答质量。
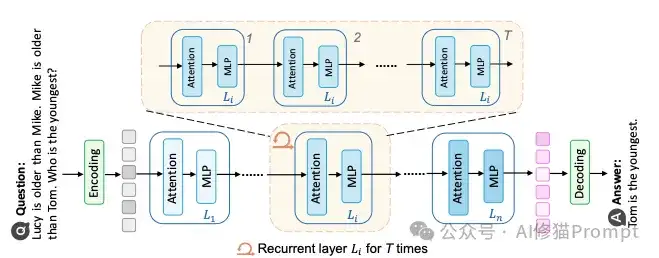
最后一种,也是最硬核的一种,是从模型架构本身下手,叫做“层级循环执行”(Layer-Recurrent Execution)。如果说前两种是“软件”层面的优化,那这一种就是“硬件”升级,它通过在Transformer架构中引入循环机制,让模型的某些层或模块的参数被重复使用,从而迭代地深化计算过程,模拟多步推理。这相当于在不显著增加模型参数量的情况下,动态地增加了模型的计算深度。
不过,您可能会问,这一切听起来很棒,但我们怎么确定模型是真的在进行有逻辑的内部推理,而不是靠着强大的记忆力或某些统计捷径在“猜”答案呢?这个问题非常关键,研究者们总结了三个方面的证据来支撑隐性推理的存在
既然隐式推理的过程我们看不见,那要怎么评估它“想”得好不好呢?这确实是个挑战,传统的评估方法显然不够用了。研究者们提出,我们需要一个更立体的评估体系,它至少应该包含这四个维度:

这永远是底线,不管过程如何,最终答案得对,常用的有准确率(Accuracy)、Pass@k等。

这是隐式推理的核心价值所在,必须关注解码延迟、输出长度、GPU使用率等指标。ACU 是一个衡量效率的复合指标。一个模型可能准确率很高,但如果它巨大无比且输出冗长,那么它的ACU值就会很低。相反,一个轻量级、输出简洁的模型,即便准确率稍低,也可能有很高的ACU值。这个指标对于在资源受限设备上部署模型非常有价值。

通过困惑度(Perplexity)等指标,评估模型本身的基础是否扎实,毕竟强大的推理离不开对语言的深刻理解。PPL: 衡量模型在预测下一个词时的“不确定性”。PPL值越低,说明模型对语言的把握越准,预测能力越强。

通过前面提到的“探针准确率”等方法,间接衡量其内部计算过程的逻辑性和有效性。
h(i): 模型在处理第 `i` 个样本时,其内部某个特定层的隐藏状态(可以看作是模型的“神经活动快照”)。
- z(i): 我们想要探测的中间推理结果(比如,在一个多步数学题中第一步的计算结果)。
- fϕ: 一个简单的、额外训练的分类器,我们称之为“探针”。它的任务是学习如何从复杂的隐藏状态 h 中“解码”出我们关心的中间结果 z。
- Lprobe: 训练这个探针时使用的损失函数,目标是让探针的预测越来越准 。
- `ProbingAcc`: 探针的准确率。即这个探针能在多大程度上成功地从模型内部的神经活动中,正确地“读出”模型此刻的中间思考结果。
这套方法就像是给AI做一个“脑电图”。训练一个“解码器”(探针),尝试从模型复杂的脑电波(隐藏状态)中,读取出它此刻是否正在思考某个特定的中间步骤。如果探针的准确率很高,就提供了有力的间接证据,表明模型确实在内部进行了结构化的、有逻辑的计算,而不是在“走神”或“瞎猜”。
论文系统梳理了超过70个用于评估推理能力的数据集 ,并将它们分为五大类:
当然,隐式推理目前还处于早期探索阶段,远非完美,研究者们总结了隐式推理目前的几个核心难题:
从“思维链”的娓娓道来,到“隐式推理”的干净利落,无论是深入神经网络内部的‘潜在优化’,还是巧妙引导计算的‘信号引导’,抑或是重塑架构的‘层级循环’,我们看到研究者们正从软硬件全方位地探索AI‘默想’的可能性。尽管挑战重重,但可以预见,未来几年,隐式推理的研究将从实验室走向更广泛的应用。当下一代AI模型不仅能言善辩,更能深思熟虑、敏锐行动时,一个真正的人工智能时代或许才算真正来临。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
