# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Meta超级智能实验室的首篇论文,来了——
提出了一个名为REFRAG的高效解码框架,重新定义了RAG(检索增强生成),最高可将首字生成延迟(TTFT)加速30倍。

毕竟算是超级智能实验的“开山之作”,研究一出,就已经在网上掀起了不少的热议。
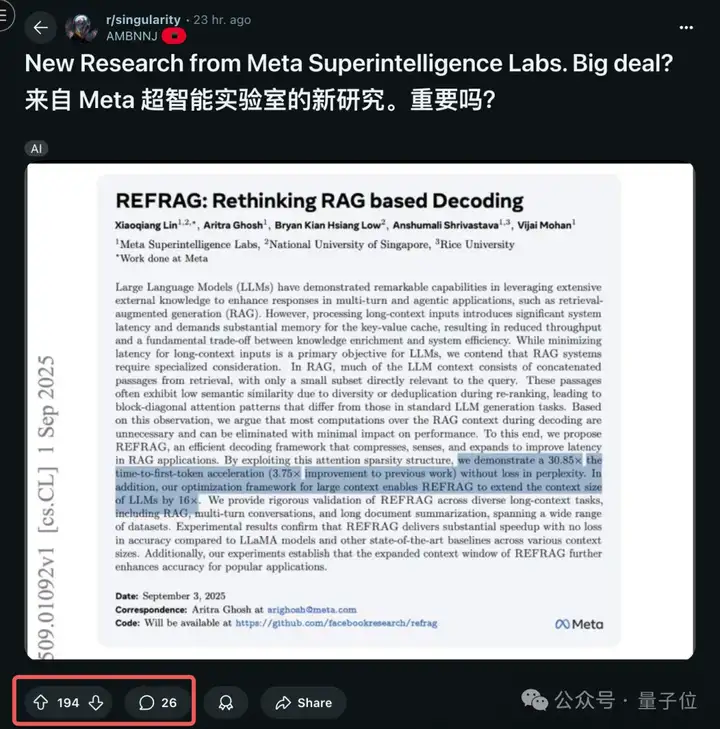
例如Reddti网友表示:
若效果真如研究所说的那样,那对RAG来说是相当不错的改进,看起来可以做到在不牺牲准确性的情况下,能显著提高速度和上下文大小。
首先,我们需要理解并回顾一下RAG的工作原理。
当一个大型语言模型(LLM)被要求回答需要精确背景知识的问题时,如果仅依赖它内部参数化的知识,可能会出现事实性错误或信息滞后等情况。
而RAG就通过一个外部知识库(如企业文档、专业数据库等)进行检索,将与问题最相关的信息提取出来,作为上下文与原始问题一同提供给LLM。LLM在获得这些精确的参考资料后,就能生成内容更可靠、更具时效性的答案。
然而,这个模式在工程方面也带来了不小的挑战,即推理效率与信息量的权衡。
当AI检索到的参考资料非常多(也就是我们通常说的“长上下文”)时,LLM的处理负担会大幅增加。
模型处理上下文的计算复杂度通常与上下文长度的平方成正比,导致生成第一个字的延迟(Time-to-First-Token, TTFT)显著增加,这直接影响了实时交互应用的用户体验。
同时,处理长上下文也意味着更高的计算和内存开销,为系统的规模化部署带来了挑战。

基于这样的背景,Meta超级智能实验室的研究人员发现,在RAG应用中,LLM处理检索到的多个文档时,其计算过程存在大量冗余。
通过实验,他们观察到模型内部的注意力机制在处理这些文档时,呈现出一种“块对角”(block-diagonal)的稀疏模式。
这意味着,模型的注意力主要集中在单个文档内部,以及各文档与用户问题之间的关联上。而不同文档片段之间的交叉注意力得分通常很低,表明它们之间的关联性较弱。
然而,标准的Transformer架构并不会区分这些关联性的强弱,而是对上下文中的所有词元(token)进行全局的注意力计算,这导致了大量计算资源被消耗在分析那些关联性很弱的文档片段上。
基于这一观察,研究团队提出:RAG解码过程中的大部分注意力计算对于最终结果的贡献有限,可以在不显著影响性能的前提下被优化或移除。
REFRAG,就此应运而生。
REFRAG这个框架,主要通过“压缩(Compress)、感知(Sense)、扩展(Expand)”的流程,优化了LLM处理外部知识的方式。
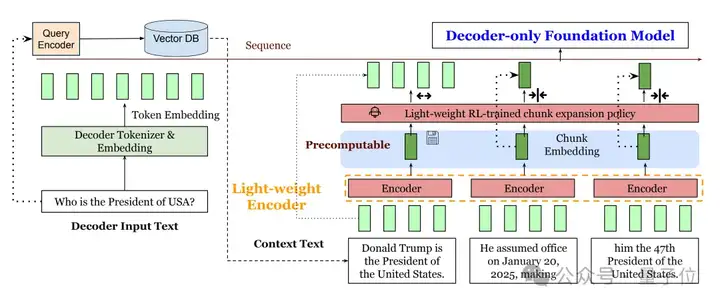
REFRAG首先改变了上下文的呈现方式,它没有将所有检索到的原始文本直接输入给主LLM,而是引入了一个轻量级的编码器模型。
这个编码器将长篇的参考资料切分为多个“块”(chunks),并为每个“块”生成一个紧凑的向量表示——“块嵌入”(chunk embedding)。这个“块嵌入”可以视为原始文本块的浓缩摘要。
这一步骤带来了两个直接的好处,首先就是缩短输入序列长度,因为LLM需要处理的输入从数千个词元缩减为数百个“块嵌入”,显著降低了后续的计算量。
其次是由于这些“块嵌入”可以被预先计算并存储,当知识库中的同一文档被再次检索时,系统可以直接调用缓存的嵌入,避免了重复的编码计算。
考虑到并非所有信息都适合压缩,某些包含关键细节的文本片段需要被保留。
为此,REFRAG训练了一个基于强化学习(RL)的策略网络。
这个网络的功能是分析所有的“块嵌入”和用户问题,判断哪些文本块包含最核心的信息,需要以原始文本的形式呈现给LLM。
经过前两步的处理,最终输入到主LLM的是一个混合序列,它包含了大部分上下文的“块嵌入”(压缩表示)和少量被判断为关键的“原始文本块”。
LLM基于这份经过优化的输入材料来生成答案,大部分背景信息通过压缩表示快速获取,而核心细节则通过原始文本进行精确理解。通过这种方式,REFRAG在保留关键信息的同时,最大限度地降低了计算负载。
根据论文数据,REFRAG框架在多个维度上取得了较为不错的成果。
例如在推理速度方面,以首字生成延迟(TTFT)为例,REFRAG实现了最高30.85倍的加速。与之前的先进方法相比,也取得了3.75倍的提升。
这意味着在需要快速响应的场景下,系统的延迟可以得到有效控制。
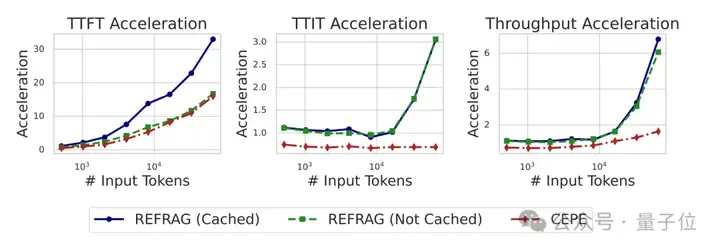
其次,实验还表明,在获得显著加速的同时,REFRAG在困惑度(Perplexity)以及多种下游任务(如问答、摘要)的准确率上,与使用完整上下文的基线模型相比没有性能损失。
此外,由于压缩技术使得模型能在同等计算预算下处理更多信息,上下文窗口等效扩大了16倍,这在某些任务上反而带来了性能增益。
据了解,这个方法的设计不仅适用于RAG,也适用于多轮对话、长文档摘要等其他需要处理长上下文信息的任务。
总而言之,Meta超级智能实验室的这项研究,通过巧妙的算法设计,有效解决了当前大模型在处理长上下文时面临的核心效率问题。REFRAG为开发更高效、更经济、更具扩展性的AI应用提供了一个重要的解决方案。
参考链接:
[1]https://arxiv.org/abs/2509.01092
[2]https://www.reddit.com/r/singularity/comments/1nai17r/new_research_from_meta_superintelligence_labs_big/
文章来自于“量子位”,作者“金磊”。


【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
