# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

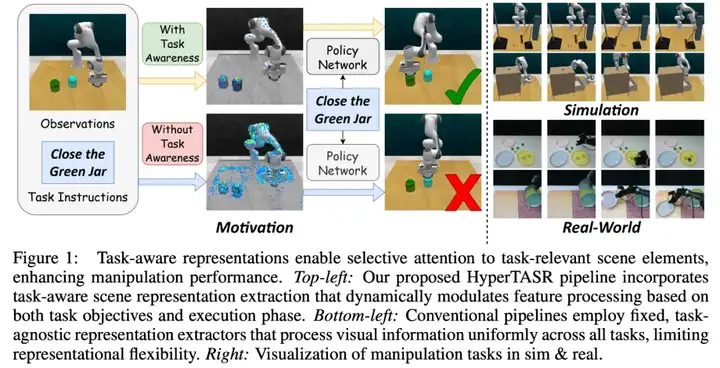
在具身智能中,策略学习通常需要依赖场景表征(scene representation)。然而,大多数现有多任务操作方法中的表征提取过程都是任务无关的(task-agnostic):
无论具身智能体要 “关抽屉” 还是 “堆积木”,系统提取的特征的方式始终相同(利用同样的神经网络参数)。
想象一下,一个机器人在厨房里,既要能精准抓取易碎的鸡蛋,又要能搬运重型锅具。传统方法让机器人用同一套 "眼光" 观察不同的任务场景,这会使得场景表征中包含大量与任务无关的信息,给策略网络的学习带来极大的负担。这正是当前具身智能面临的核心挑战之一。
这样的表征提取方式与人类的视觉感知差异很大 —— 认知科学的研究表明,人类会根据任务目标和执行阶段动态调整注意力,把有限的感知资源集中在最相关的物体或区域上。例如:找水杯时先关注桌面大范围区域;拿杯柄时又转向局部几何细节。
那么,具身智能体是否也可以学会 “具备任务感知能力的场景表征” 呢?
1. 提出任务感知场景表示框架
我们提出了 HyperTASR,这是一个用于提取任务感知场景表征的全新框架,它使具身智能体能够通过在整个执行过程中关注与任务最相关的环境特征来模拟类似人类的自适应感知。
2. 创新的超网络表示变换机制
我们引入了一种基于超网络的表示转换,它可以根据任务规范和进展状态动态生成适应参数,同时保持与现有策略学习框架的架构兼容性。
3. 兼容多种策略学习架构
无需大幅修改现有框架,即可嵌入到 从零训练的 GNFactor 和 基于预训练的 3D Diffuser Actor,显著提升性能。
4. 仿真与真机环境验证
在 RLBench 和真机实验中均取得了显著提升,验证了 HyperTASR 在不同表征下的有效性(2D/3D 表征,从零训练 / 预训练表征),并建立了单视角 manipulation 的新 SOTA。
在这项工作中,我们提出了 HyperTASR —— 一个基于超网络的任务感知场景表征框架。它的核心思想是:具身智能体在执行不同任务、处于不同阶段时,应该动态调整感知重点,而不是一直用一套固定的特征去看世界。
换句话说,HyperTASR 让具身智能体在执行任务时,像人类一样 “看得更专注、更聪明”。
任务感知的场景表示 (Task-Aware Scene Representation)
传统的具身智能体操作任务(Manipulation)学习框架通常是这样的:

这种做法的局限在于:表征提取器始终是任务无关的。不管是 “关抽屉” 还是 “堆积木”,它提取的特征都一样。结果就是:大量无关信息被带入策略学习,既降低了策略学习的效率,也增加了不同任务上泛化的难度。
受到人类视觉的启发,我们提出在表征阶段就引入任务信息:
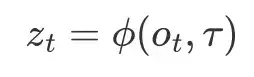
这样,场景表示能够随任务目标与执行阶段动态变化,带来三个好处:
超网络驱动的任务条件化表示 (Hypernetwork-Driven Task-Conditional Representation)
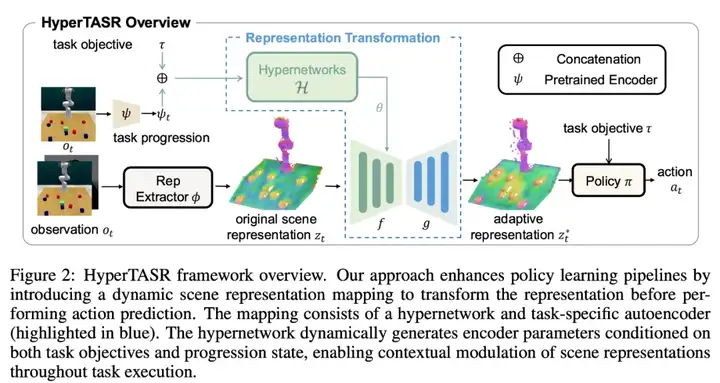
HyperTASR 的详细结构如 Figure 2 所示。为了实现任务感知,我们在表征提取器后加入了一个 轻量级的自编码器:
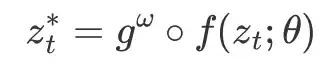

这样,场景表征不仅会随任务不同而变化,也会在任务的执行过程中不断动态迁移。
这种设计的优势:
1. 梯度分离:任务上下文与状态相关信息在梯度传播中分离,增强可解释性和学习效率
2. 动态变换:不是简单加权,而是真正改变表征函数,使得表征更加灵活
HyperTASR 的另一个优势是模块化、易集成。这种 “即插即用” 的设计让 HyperTASR 可以同时增强 从零训练和预训练 backbone 两类方法。我们分别把它嵌入到两类主流框架中进行验证:
1.GNFactor(从零训练):使用 3D volume 表征
2.3D Diffuser Actor(基于预训练):使用 2D backbone 提取特征再投影到 3D 点云
我们只使用了行为克隆损失(Behavior Cloning Loss)作为我们网络的训练损失。
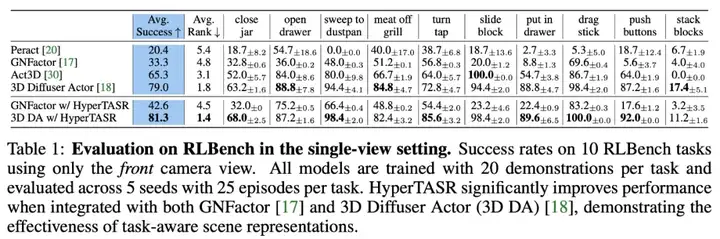
仿真实验
在仿真环境 RLBench 中的 10 个任务上进行训练,实验结果如 Table 1 所示:
在此基础上,我们进一步通过网络的梯度进行了注意力可视化:

从 Figure 3 中我们可以观察到:
另外,我们进行了消融实验,证明了 HyperTASR 设计中,引入任务进展的合理性,以及证明了使用超网络相比于直接利用 Transformer 将任务信息融合到场景表征里,能够获得更大的性能提升。
真机实验
我们采用 Aloha 进行了真机 manipulation 实验。如 Table 2 所示,在 6 个实际任务中,HyperTASR 在仅每个任务 15 条示教样本的有限条件下达到了 51.1%,展示了在真实环境操作中的强泛化能力。
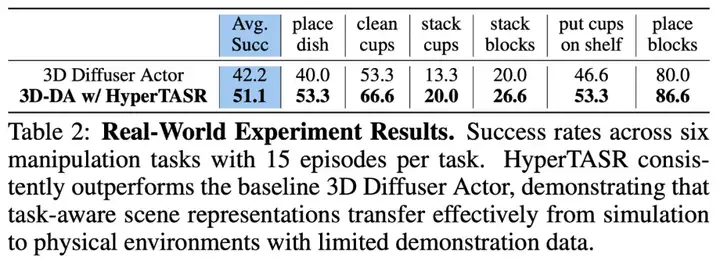
一些真机实验对比结果如下:

参考
[1] Ze, Yanjie, et al. "Gnfactor: Multi-task real robot learning with generalizable neural feature fields." Conference on robot learning. PMLR, 2023.
[2] Ke, Tsung-Wei, Nikolaos Gkanatsios, and Katerina Fragkiadaki. "3D Diffuser Actor: Policy Diffusion with 3D Scene Representations." Conference on Robot Learning. PMLR, 2025.
文章来自于“机器之心”,作者“孙力和吴杰枫”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
