# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI 开发复杂软件的时代即将到来?
近年来,以 Google 的 AlphaEvolve 为代表的研究已经证明,AI 智能体可以通过迭代来优化算法,甚至在某些小型、独立的编程任务上超越人类。然而,这些工作大多局限于几百行代码的「算法内核」或单个文件。
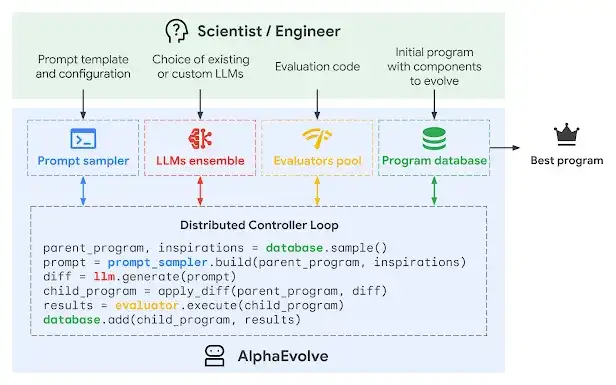
但现实世界的软件,比如一个顶级的 SAT 求解器,是一个庞大而复杂的系统工程,包含数百个文件、精密的编译系统和无数相互关联的模块。手动打造一个冠军级求解器不仅需要极高的领域知识,而且投入产出比越来越低。
为此,NVIDIA Research 的研究人员提出了 SATLUTION,首个将 LLM 代码进化能力从「算法内核」扩展到「完整代码库」规模的框架。SATLUTION 能够处理包含数百个文件、数万行 C/C++ 代码的复杂项目,并在被誉为「计算理论基石」的布尔可满足性(SAT)问题上,取得了超越人类世界冠军的性能。

SATLUTION 框架通过协调 LLM 智能体,在严格的正确性验证和分布式运行时反馈的指导下,直接对 SAT 求解器的代码库进行迭代优化。值得一提的是,在这一过程中,它还会同步地「自我进化」其进化策略与规则。
基于 2024 年 SAT 竞赛的代码库与基准,SATLUTION 进化出的求解器不仅在 2025 年的 SAT 竞赛中击败了人类设计的冠军,而且在 2024 年的基准测试集上,其性能也同时超越了 2024 年和 2025 年两届的冠军。
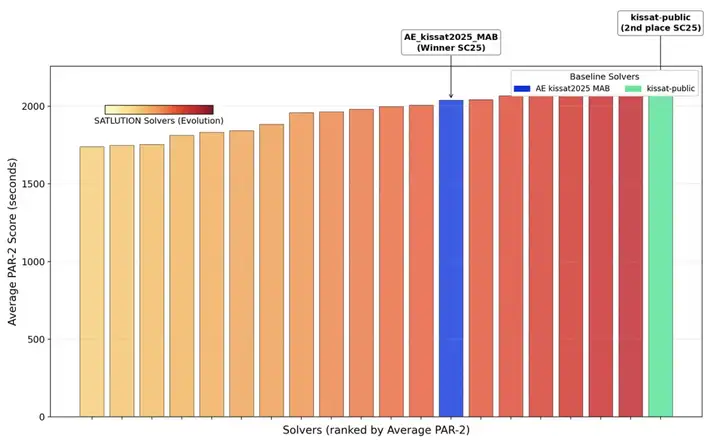
SATLUTION 在 2025 年 SAT 竞赛基准测试中的惊人表现。图中柱状图的高度代表 PAR-2 分数(一种衡量求解器性能的指标,越低越好)。左侧颜色渐变的柱体是 SATLUTION 进化出的求解器家族,它们的分数显著低于人类设计的 2025 年竞赛冠军(蓝色)和亚军(绿色)。
SATLUTION 围绕 LLM 智能体、一套动态规则系统以及一个严格的验证与反馈循环构建。
该系统由两个协同工作的 LLM 智能体驱动,基于 Cursor 环境和 Claude 系列模型实现。
规划智能体:负责高层次的战略制定。在进化周期的初始阶段,它会分析作为起点的求解器代码库及其性能,提出有潜力的修改方向。在后续周期中,它会综合考量累积的代码变更、性能指标和历史失败记录,为下一次迭代制定新的进化计划。
编码智能体:负责执行具体的开发任务。它根据规划智能体的蓝图,直接对 C/C++ 求解器代码库进行编辑和实现。其职责还包括管理辅助任务,例如更新 Makefile 等构建系统配置、修复编译错误以及调试功能性或执行时错误。
规则系统是确保进化过程高效和稳定的关键。它为智能体的探索提供了必要的引导,有效减少了在无效或错误方向上的尝试。
在进化开始前,研究人员为系统设定了一套静态规则,编码了基础的领域知识和硬性约束。这包括:基本的 SAT 启发式算法原则、严格的正确性要求(如必须为无解实例生成 DRAT 证明)、统一的代码库目录结构规范以及详细的评估协议。
实验表明,在缺少这套初始规则的情况下,智能体的表现会显著下降,容易产生偏离目标的修改。
该框架的一个核心特点是规则库本身能够动态演进。在每个进化周期结束后,一个分析器会对过程中的编译错误、验证失败和新出现的失效模式进行复盘,并自动提出规则补丁。
例如,系统可以根据一次失败的经验,自动向规则库中添加一个新的「禁止代码模式」,从而防止智能体在未来重复同样的错误。这使得规则系统与求解器代码共同进化,不断提升框架的整体效率和鲁棒性。
为保障代码质量和求解的正确性,每个新生成的求解器版本都必须通过一个严格的流程。
第一阶段是编译和基本功能测试。 系统会尝试编译新代码,成功后在一个包含 115 个简单 CNF 实例的测试集上运行,以捕捉编译错误、段错误等基础问题。
第二阶段是完整的正确性验证。 通过第一阶段的求解器会在一个更大的、结果已知的基准测试集上运行。对于其输出的每一个结果,系统都会进行核查:如果报告「可满足」(SAT),则验证所给出的赋值是否正确;如果报告「不可满足」(UNSAT),则使用外部检查工具验证其生成的 DRAT 证明的有效性。
只有完全通过这两个阶段验证的求解器,才会被认为是「正确」的,并进入下一步的性能评估。
通过验证的求解器会被部署到一个由 800 个 CPU 节点组成的集群上,在完整的 SAT Competition 2024 基准测试集(包含 400 个实例)上进行并行评估。这种大规模并行使得整个评估过程可以在大约一小时内完成,从而为智能体提供近乎实时的性能反馈。
反馈指标非常详尽,包括已解决的 SAT/UNSAT 实例数量、不同时间段内解决的实例分布、内存使用情况,以及作为核心驱动指标的 PAR-2 分数(一种对未解决实例进行高额时间惩罚的平均运行时指标)。
SATLUTION 在 70 个进化周期的实验中,展现了清晰且稳健的性能提升轨迹。
根据论文中对 2024 年基准测试集的性能追踪图表(图 8)显示,在最初的 5-10 个迭代周期中,系统取得了快速进展,这主要是因为它整合了多个初始种子求解器的互补优势。
随后,性能提升的速度有所放缓,但仍在持续进行,表明智能体开始处理更细微和复杂的优化问题。
大约在第 50 次迭代时,SATLUTION 进化出的求解器在 2024 年的基准上已经开始优于 2025 年的人类设计冠军。
到第 70 次迭代结束时,其性能已稳定地超越了所有用于比较的基准求解器。整个过程表现出高度的稳定性,由于验证保障措施的存在,没有发生过严重的性能衰退。
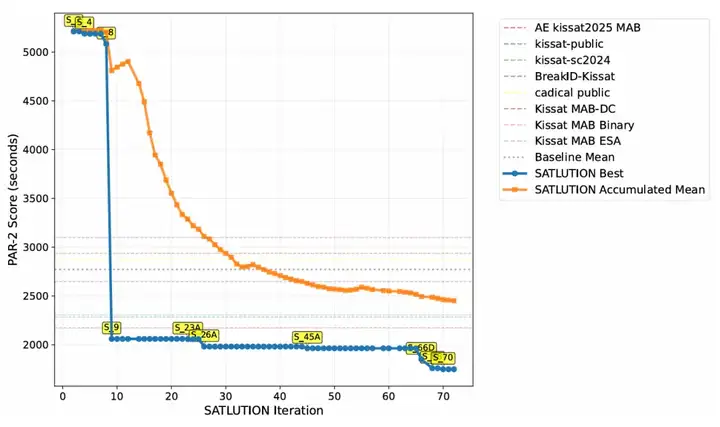
SATLUTION 自进化性能曲线。
整个 SATLUTION 自我进化实验过程的总计成本低于 20000 美元。相比之下,由人类专家开发一个具有竞争力的 SAT 求解器通常需要数月乃至数年的持续工程投入,而 SATLUTION 在数周内便取得了超越顶尖人类水平的成果。
更多细节请参见原论文。
文章来自于“机器之心”,作者“机器之心编辑部”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
