# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
让智能体组团搞深度研究,效果爆表!
华为最新发布DeepDiver-V2原生多智能体系统。
采用了“团队作战”模式:一个Planner负责任务分解,任务分发,进度审视和成果验收,多个专业Executor并行处理子任务,通过共享文件系统高效交换信息。

与仅通过推理框架实现的多智能体系统不同,DeepDiver-V2以多智能体形态进行训练,模型天然具备更强的角色扮演和协同推理能力。这套系统不仅在复杂知识问答任务上取得突破,更是能够生成数万字的高质量深度研究报告,在多个榜单中表现亮眼。
它基于华为openPangu Agent推出的DeepDiver-V2,这是一个专攻AI深度搜索和长文调研报告生成的模型。目前已开源。
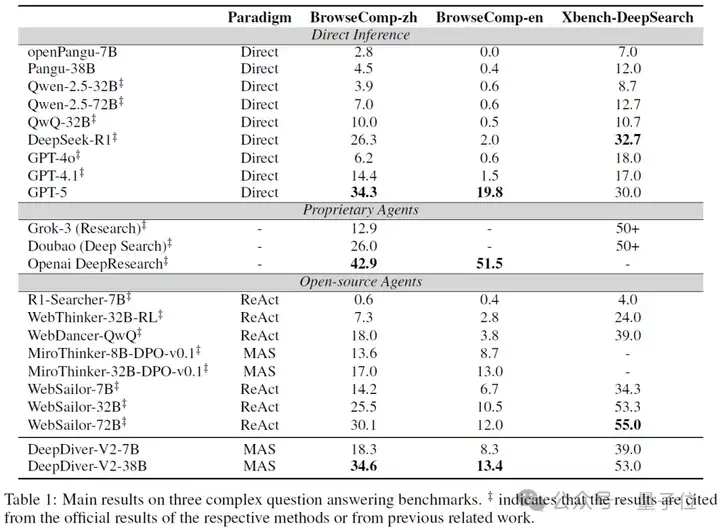
数字最有说服力。DeepDiver-V2-7B和DeepDiver-V2-38B和在多个权威基准测试中表现亮眼:
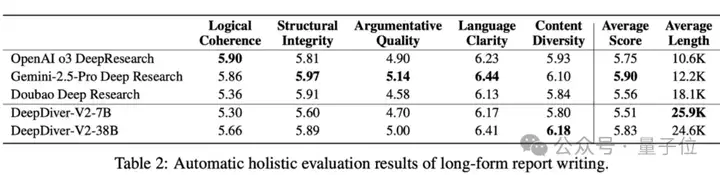
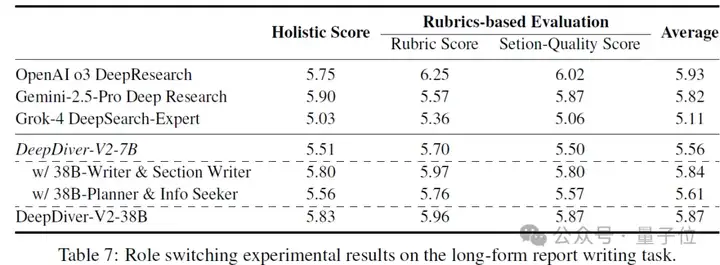
在长文报告生成方面,DeepDiver-V2提出了一个全新的面向深度调研报告生成的基准测试WebPuzzle-Writing,该基准给每个调研query设置了详细的调研范围而非开放生成,可以更加方便多个模型之间的横评。
在该测试中,DeepDiver-V2生成的报告平均长度达24.6K tokens,是OpenAI o3 DeepResearch(10.6K)的两倍多。自动评测结果也显示DeepDiverV2效果与主流agent产品相当, 在信息度上格外亮眼,Content Diversity指标优于其他模型。
团队之前的研究成果DeepDiver-V1就像一个全能选手,需要在一个超长的上下文窗口中处理所有任务,结果往往因为负担过重而表现不佳。DeepDiver-V2改变了这一模式。它采用以Planner(规划器)为中心, 协调多个Executor(执行器)的MAS(Multi-Agent System,多智能体系统)架构。
Planner接到复杂查询后,会进行自适应复杂度评估。简单问题直接处理,复杂问题则构建一个”任务树”,将大任务层层分解为可并行/串行/嵌套执行的子任务。
Planner甚至会采用”竞争赛马”机制——让多个 Executor同时处理相似任务,通过交叉验证提高结果可靠性。
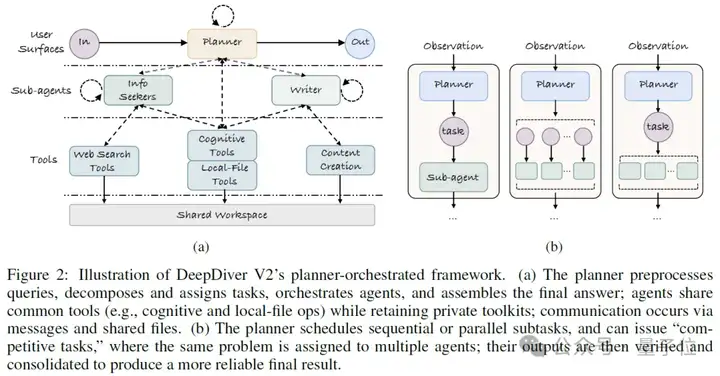
不同于DeepDiver-V1使用单个上下文窗口处理多个任务,智能体之间各自执行任务, 并通过共享文件系统交换信息:
交换的信息 = {当前任务摘要, 任务执行过程产生的中间物料的元数据}
每个智能体只需传递精炼的任务摘要和文件元数据,而非完整上下文。详细内容存储在共享文件中,其他智能体按需读取。这种设计带来三大优势:
1、可扩展通信:消息大小保持可控,不受任务复杂度影响。
2、持久化状态:历史信息得以完整保存,LLM Agents无需维护完整对话历史。
3、并行执行:独立子任务可同时处理,避免上下文冲突。
系统包含两类核心Executor:
1、Information Seeker(信息搜集助手):负责证据收集, 验证, 去噪等。Information Seeker可以网罗相关信息, 筛选特定信息源, 深度分析并提取关键事实和数据, 迭代式的完善收集到的信息以解决Planner分发的任务。
2、Writer(写作助手):负责长文本生成, writer可以构建章节大纲, 并分配资料到各个章节. Writer使用逐章节写作的方式, 并能够迭代式的完善行文, 能够保持全局的连贯性。
训练多智能体系统面临独特挑战:当最终任务失败时,如何判断是哪个智能体的责任?当最终任务成功时, 如何判断是哪个智能体做出了贡献? DeepDiver-V2提出了Planner-centric(以规划器为中心的)的分配机制。
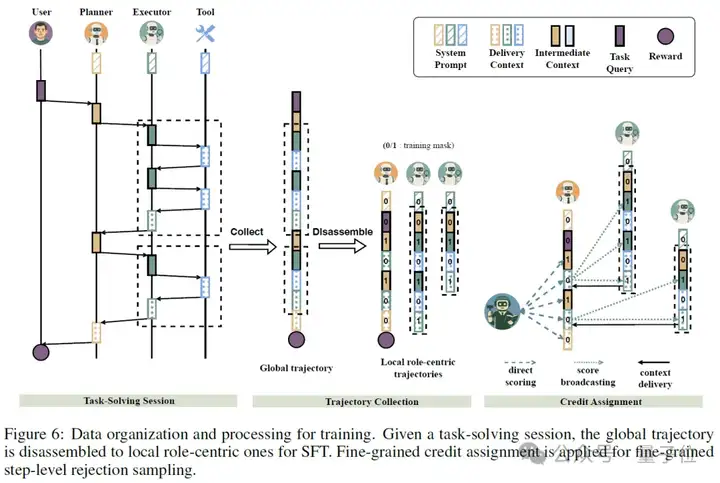
训练流程采用多阶段优化:
1、冷启动监督微调
首先让模型学会基本的多角色协作、工具调用和文件系统操作,奠定多智能体能力基础。
2、拒绝采样微调(RFT)
3、在线RFT
在离线RFT的基础上, DeepDiver使用相同的credit assignment策略,进一步进行在线RFT训练, 结合partial rollout(部分轨迹采样) 和dynamic rollout-buffered batching(动态轨迹缓存批处理)策略, DeepDiver-V2的在线训练得以高效且稳定的进行。
训练数据上, DeepDiver-V2继续沿用了DeepDiver-V1的训练数据WebPuzzle, 然而在WebPuzzle的基础上, DeepDiver-V2进一步增加了更多有挑战性, 验证性更强的数据, 同时加入了原本WebPuzzle没有的长文写作数据. 经过了这些数据的训练, DeepDiver-V2表现出了更强大的性能。
DeepDiver-V2的训练完全使用Atlas 800I A2集群进行, 依托于1000+ NPU组成的大规模计算集群。每个节点包含8个 NPU,这些NPU通过华为高速缓存一致性系统(HCCS)以全互联拓扑相连,每个NPU配备64GB内存。用于跨节点通信时,集群采用基于以太网的RDMA,通过200 Gbps链路为跨节点的NPU提供高带宽连接。团队开发了专门的强化学习框架,包括:
研究团队进行了系统性的消融实验和深度分析,揭示了多智能体协作背后的几个关键机制和意外发现。
Executor能力是性能瓶颈,Planner”够用就好”
团队通过”角色互换”实验发现了一个有趣现象:系统性能对Executor能力极其敏感,但对Planner要求相对宽松。
具体数据显示:
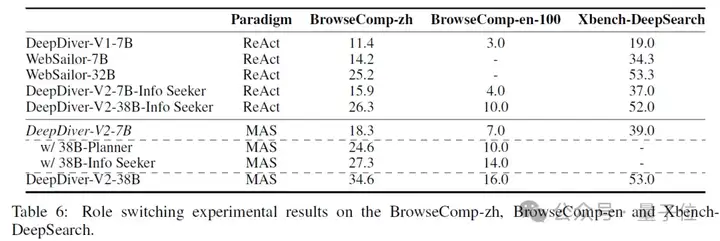
这个发现颠覆了以往的认知——一般大家会以为”大脑”(Planner)最重要,但实际上”手脚”(Executor)的能力才是关键。研究团队分析,这是因为Planner的任务相对标准化(分解问题、分配任务),而 Executor需要处理各种复杂的实际场景。一个中等能力的7B Planner已经能胜任大部分协调工作。
单体能力的意外涌现:团队训练造就全能选手
最令人惊讶的发现是:为团队协作训练的, 服务于Planner的子智能体,单独使用时竟然也是高手。
当研究团队将Information Seeker从系统中剥离出来单独测试时:
这种现象说明,多智能体训练不仅提升了协作能力,还让每个子智能体在处理扩展任务集时变得更加鲁棒。就像优秀的团队成员,既能配合默契,又能独当一面。
DeepDiver-V2相对DeepDiver-V1, 从单一模型的”独角戏”到多智能体的”交响乐”,这种转变为解决更复杂的现实问题开辟了道路。未来, DeepDiver将在企业调研、科学文献综述、专业数据分析等专业领域发挥巨大作用。
【参考文献】
[1] Shi, Wenxuan, et al. “Pangu deepdiver: Adaptive search intensity scaling via open-web reinforcement learning.” arXiv preprint arXiv:2505.24332 (2025).
[2] Li, Kuan, et al. “WebSailor: Navigating Super-human Reasoning for Web Agent.” arXiv preprint arXiv:2507.02592 (2025).
[3] Li, Xiaoxi, et al. “Webthinker: Empowering large reasoning models with deep research capability.” arXiv preprint arXiv:2504.21776 (2025).
文章来自于“量子位”,作者“允中”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
