# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
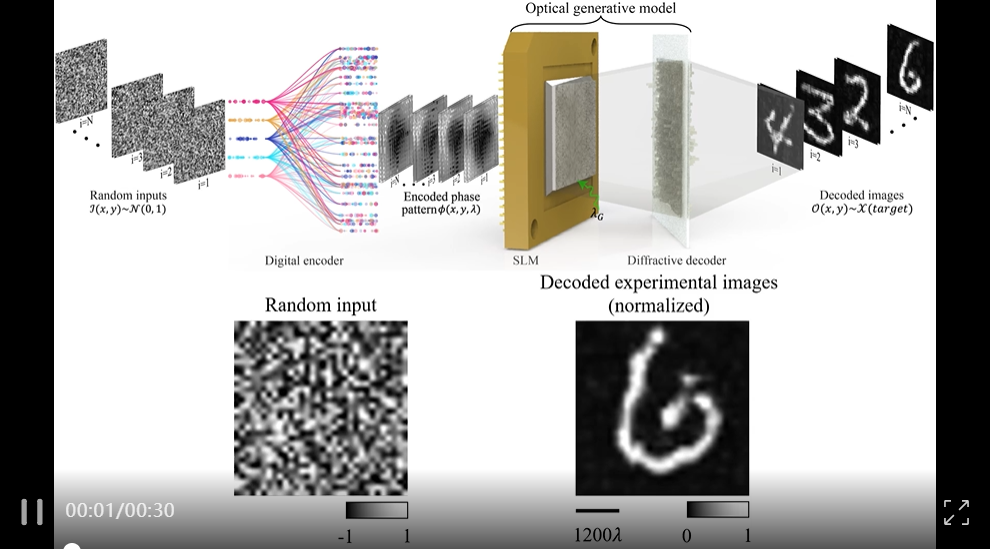
见过省电的模型,但这么省电的,还是第一次见。
在 《自然》 杂志发表的一篇论文中,加州大学洛杉矶分校 Shiqi Chen 等人描述了一种几乎不消耗电量的 AI 图像生成器的开发。

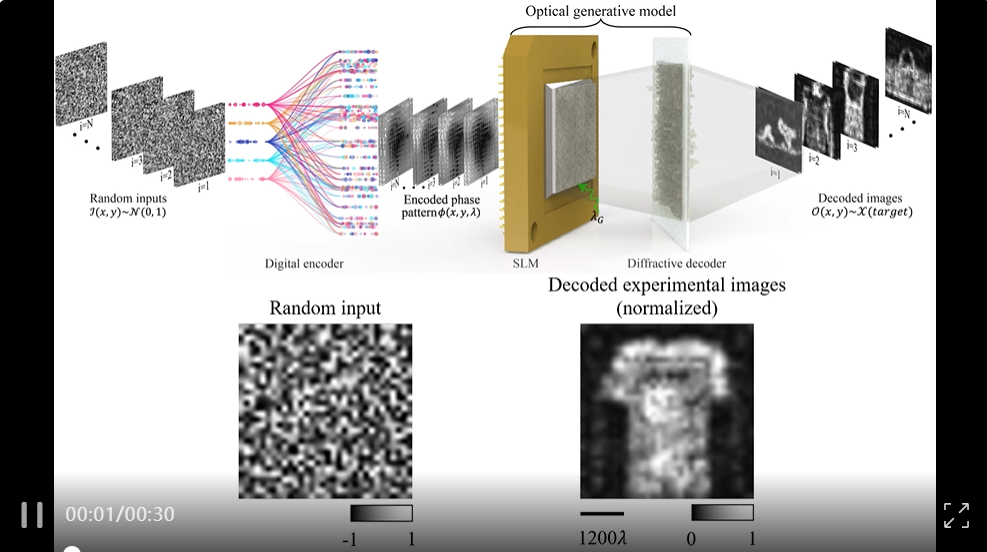
该生成器是一种受扩散模型启发的光学生成模型。其工作原理如下:首先通过数字编码器(使用公开数据集训练)生成最终构成图像的静态噪声,这一过程仅需消耗极少能量。随后,一种被称为空间光调制器(SLM)的液晶屏幕会将这种噪声模式刻印到激光束上。该激光束再通过第二台解码 SLM 装置,将光束中的噪声模式转化为最终图像。
与传统 AI 依赖数百万次计算机运算不同,该系统利用光完成所有核心工作,因此几乎不消耗电能。论文第一作者 Shiqi Chen 表示:「我们的光学生成模型几乎无需算力就能合成海量图像,为数字 AI 模型提供了可扩展且高能效的替代方案。」
研究人员采用多种 AI 训练图像对系统进行测试,包括名人肖像、蝴蝶图像以及梵高风格的全彩画作。结果显示,光学系统生成的图像效果与传统图像生成器相当,但能耗显著降低。

该技术还具有广泛的应用前景。凭借其超高速和超低能耗特性,该系统可用于生成 VR、AR 显示的图像视频,也适用于智能手机、AI 眼镜等可穿戴电子设备的小型化终端。

不过,该模型目前仍处于物理实验阶段,离实用还有一段距离。

本文提出的光学生成模型,能够根据目标数据分布合成单色或彩色图像 —— 即通过光学方法生成特定数据分布中前所未见的新图像。受扩散模型启发,该方案采用浅层数字编码器将随机二维高斯噪声模式快速转换为代表光学生成种子的二维相位结构。这种光学种子的产生是一次性的,它涉及一个作用于随机二维噪声模式的浅而快速的相位空间编码器。
根据目标分布即时生成图像或输出数据的过程,可通过随机调用这些预先计算好的光学生成种子按需实现。这一广义概念可通过不同光学硬件实现,集成光子学或基于自由空间的实现。
即时图像生成
图 1 展示了作者研发的单色图像即时生成模型的原理示意图。如图 1a 所示,遵循正态分布的随机二维输入首先通过数字编码器转换为二维相位模式,该编码器可快速提取潜在特征并将其编码至相位通道以供后续模拟处理。这些由随机噪声生成的相位编码输入作为光学生成种子,被加载到 SLM 中,为衍射光学生成模型提供信息输入。在相干光照下,携带编码相位模式的光场继续传播并通过为特定目标数据分布优化的衍射解码器进行处理。最终,生成的图像由图像传感器捕获,这些图像符合目标数据分布特征。
图 1b 展示了训练流程:作者首先基于去噪扩散概率模型(DDPM)训练教师数字生成模型以学习目标数据分布。完成训练后,冻结该 DDPM 模型并持续生成用于训练即时光学生成模型的噪声 - 图像数据对。浅层数字相位编码器与光学生成模型通过联合训练,使模型能够以简洁可重构的架构高效学习目标分布。
图 1c 呈现了盲推理过程:由数字编码器从随机噪声模式产生的编码相位模式(即光学种子)是预先计算的,光学生成模型则使用固定的静态解码器在自由空间中对这些生成相位种子进行解码。为实现从随机高斯噪声快速合成光学生成相位种子,数字编码器包含三个全连接层,其中前两层采用非线性激活函数(详见方法部分)。可重构衍射解码器通过 400 × 400 个可调相位特征(每个特征覆盖 0-2π 范围)进行优化,完成优化后针对每个目标数据分布保持静态。
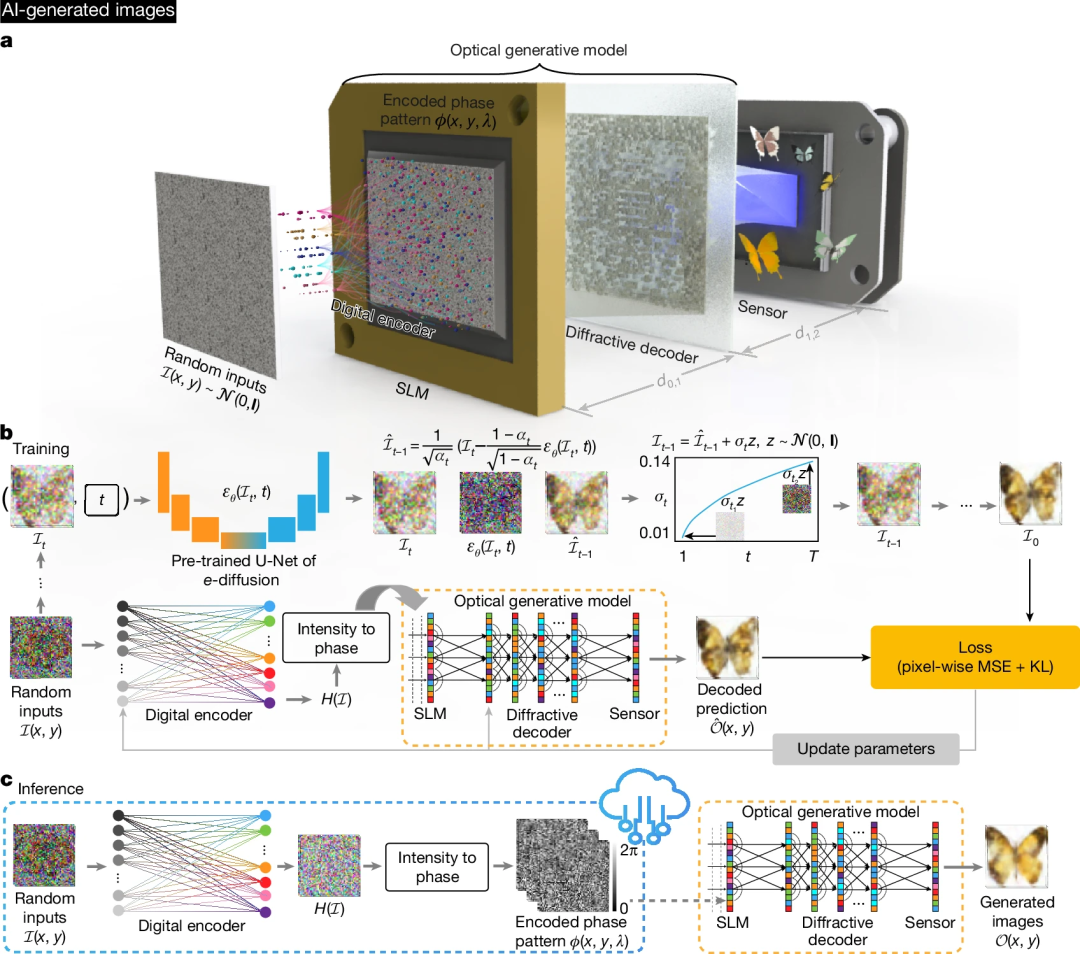
图 1
迭代式光学生成模型
作者还设计了一种迭代式光学通用模型,可从高斯噪声中递归重建目标数据分布。如图 2a 所示,该迭代光学生成模型同样工作在三个照明波长下,通过浅层数字相位编码器编码的多通道相位图案被顺序加载到同一 SLM 上。
为展示这种迭代光学模型的生成能力,作者采用 Lₒ=5 个联合优化并固定的解码层来处理目标数据分布。与前述即时光学生成模型的不同之处在于:当图像传感器平面记录初始强度图像后,测量结果会按设计方差添加高斯噪声,该噪声扰动结果将作为下一时间步的迭代光学输入。
图 2b 展示了这种迭代光学生成模型的训练过程:采样一批时间步并相应地向原始数据添加噪声,获得噪声样本。这些噪声样本经过浅层数字编码器和迭代光学生成模型处理,得到连续输出。与标准 DDPM 实现不同,该迭代光学生成模型直接预测去噪样本,其损失函数根据原始数据计算。
图 2c 概述了迭代式光学生成模型的盲推理过程:已训练的光学模型对从最终时间步到初始时间步的扰动样本递归执行去噪操作,最终生成的图像在传感器平面捕获(详见方法部分)。
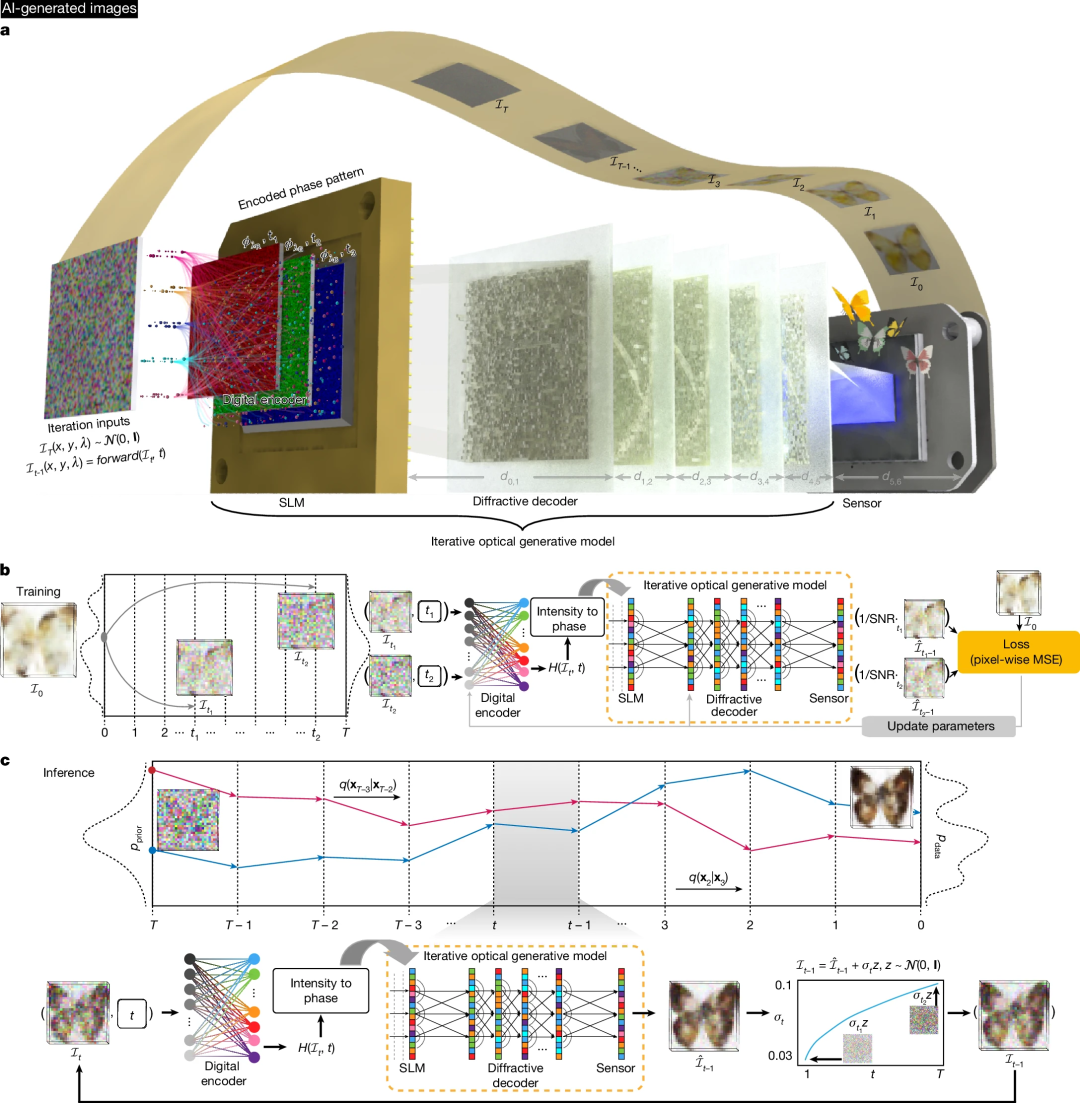
图 2
在初步实验中,研究者分别基于 MNIST 和 Fashion-MNIST 数据集训练了两个不同的模型,用于生成手写数字和时尚商品图像。
图 3c 为两个模型的结果,生成的图片在 MNIST 和 Fashion-MNIST 数据集上分别达到了 131.08 和 180.57 的 FID 实验评分。这表明生成的图片符合这两个数据集的目标分布,充分体现了所设计系统的多样性,进一步验证了快照式光学生成模型的可行性。
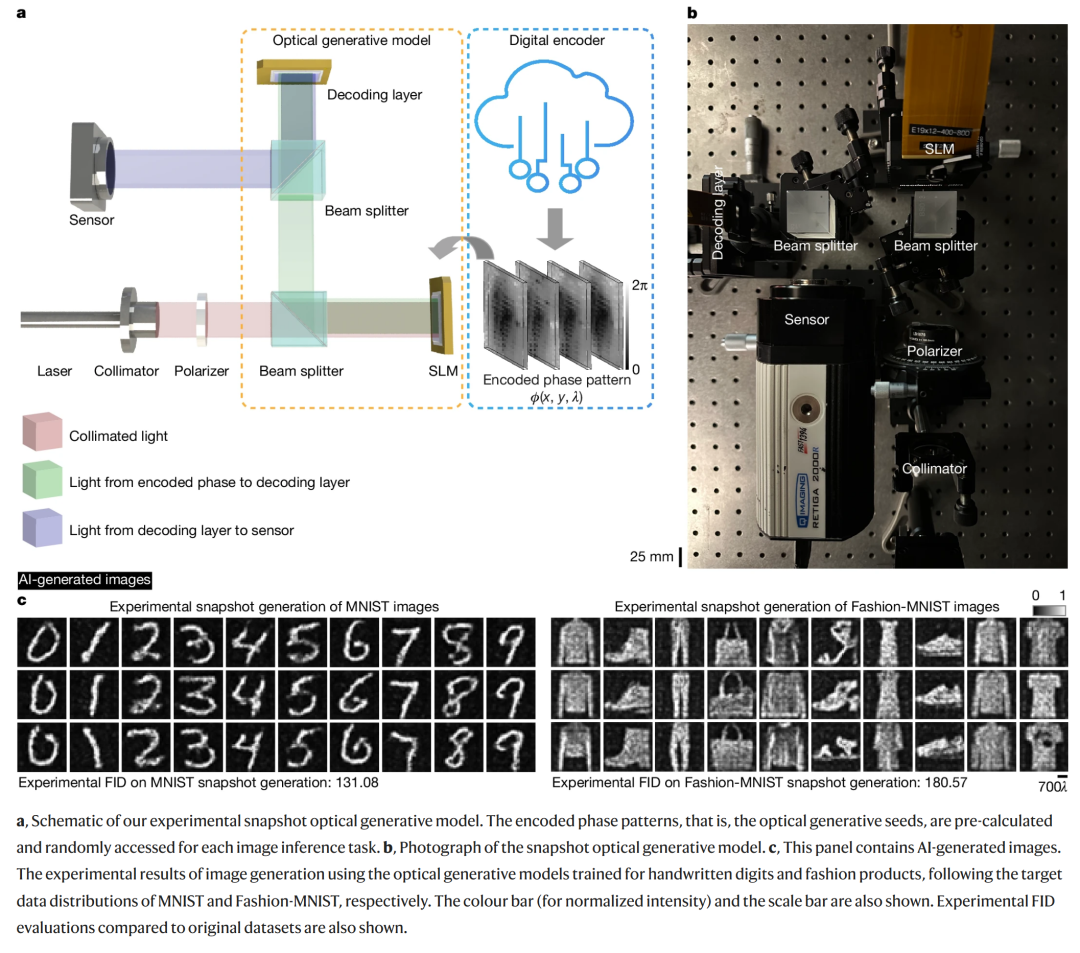
生成手写数字
生成时尚商品
研究者进一步将实验结果拓展至更高分辨率的梵高风格艺术作品生成。
图 4 与图 5 分别展示了使用 5.8 亿参数数字编码器实现的高分辨率单色及彩色(RGB)图像生成实验结果。其中梵高风格单色图像采用 520 纳米波长照明生成,而彩色图像则依次使用 {450, 520, 638} 纳米波长分别对应蓝、绿、红三通道。

在多色梵高风格艺术图像生成实验中,研究者为每个波长通道生成了相应的相位编码生成种子图案,并依次加载到空间光调制器(SLM)上。在对应波长的照明下,利用固定或静态的衍射解码器生成多彩图像,并通过数字方式进行融合。换言之,在所有波长照明下的图像生成过程中,系统共享同一个解码器状态。
图 5 展示了多色梵高风格艺术作品的生成结果,其中既包含与教师数字扩散模型输出高度吻合的案例,也包含具有差异性输出的示例(该教师模型需使用 10.7 亿可训练参数并通过 1000 次迭代步骤生成单幅图像)。尽管观察到轻微的色差现象,生成的高分辨率彩色图像仍保持了优异的质量。

Shiqi Chen,加州大学洛杉矶分校(UCLA)博士后研究员,导师为 Aydogan Ozcan 教授。此前,他在浙江大学获得博士学位,师从冯华君教授和徐之海教授。
Shiqi Chen 在博士期间主要研究重点是应用光学和计算机视觉,以实现更清晰的计算成像,其中部分研究成果已应用于最新的移动终端设备。

文章来自于微信公众号“机器之心”。



