# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
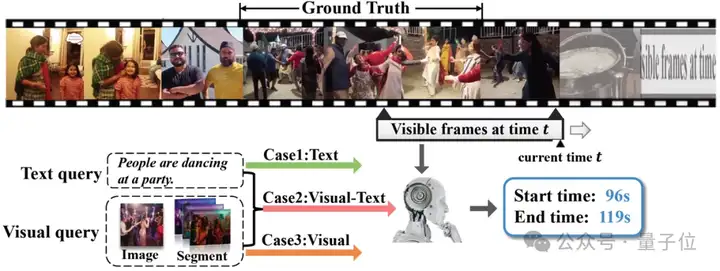
还在实时视频里找特定事件找半天?最新技术直接开挂了。
试想一下,安防监控中,几个人影短暂掠过,利用新技术可以秒级调出这段“可疑聚众”的精准片段。

△图片为AI生成
在VR训练场,你戴上VR眼镜练习投篮,提前在手机App输入“定位和这个视频示范(库里完美三分片段)相似的动作”。训练开始,每一次出手,眼镜在后台默默分析第一视角视频流。当你做出动作、发力、弧线都神似库里的三分时,眼镜立刻就能在虚拟界面高亮标记这个片段。

△图片为AI生成
不卖关子,这就是来自深圳北理莫斯科大学、阿德莱德大学的研究团队提出的新任务。
名叫混合模态在线视频定位(Online Video Grounding with Hybrid-modal Queries, OVG-HQ)。
用大白话说,这项技术能让系统一边直播/录像,一边根据你提供的多种“线索”,包括文字、参考图、示范视频片段或组合等,瞬间在实时视频流中找出并精准裁剪出你关心的完整事件。
论文已收录于ICCV2025。
此前方法的缺陷有两个:
“离线”是硬伤:主流技术必须等视频录完才能干活,事后分析如同马后炮,无法满足安防“秒级响应”、直播“即时重现”、VR“训练中实时反馈”的刚需。
“词穷”是软肋:仅靠文字描述(如“聚众”“劈杀”“完美三分”)难精准定义视觉世界的微妙差异。动作发力点、光影细节、空间模式……很多时候“只可意会”。
OVG-HQ是怎么破局的呢?
团队表示,要让系统做到“精准定位+理解多模态”,需跨过两道坎:
挑战一:流式场景下的历史知识持续保留
模型在实时处理视频流时,必须确保历史关键信息不丢失——否则早期出现的动作线索或场景特征被遗忘,将导致事件起止点误判。
挑战二:查询模态分布不均
同一用户意图可能对应一段5秒视频(信息丰富),也可能仅是一张低分辨率图或简短文字(信息稀疏)。强弱模态的显著差异会导致模型过度依赖强模态,无法充分利用弱模态信息,影响多源信息整合精度。
构建能均衡处理所有模态组合的统一模型异常困难。

为系统性研究上述问题,团队整理QVHighlights数据,构建首个支持混合模态在线定位的基准集QVHighlights-Unify,扩充四种查询元素:
总计71.6K组查询,覆盖8种模态组合,构成首个混合模态在线定位的统一评估基准。
针对两项挑战,团队提出两个核心组件:
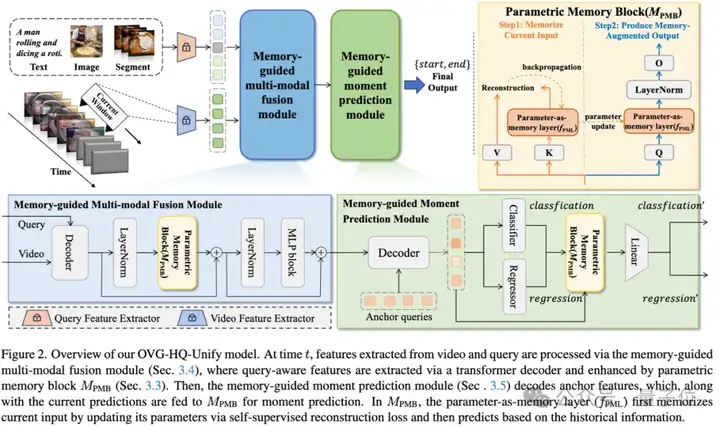
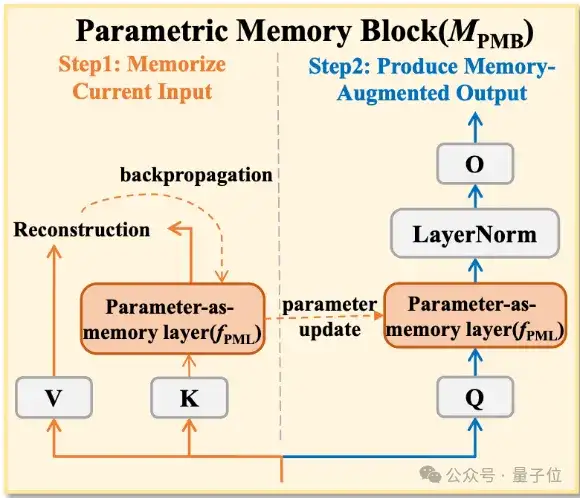
1、参数化记忆模块(PMB)
step 1:记忆当前输入,通过参数即记忆层,将当前输入信息压缩到记忆参数中,并采用重构损失进行自监督学习。通过梯度下降更新记忆参数,使其同时保留当前和历史信息。
step 2:记忆增强处理,利用更新后的记忆参数对当前输入进行增强:先经投影层映射,输入参数即记忆层,再通过层归一化和投影操作,输出记忆增强后的表征供后续模块使用。
2、混合模态蒸馏(Hybrid-modal Distillation)
step 1: 为信息量丰富的模态组合(文本+生成片段)训练专家模型。
step 2: 以专家输出为软标签,引导其他模态的学生模型,最终得到能统一处理8种模态组合的通用模型。

离线指标只关心“对不对”,不关心“快不快”。为衡量实时能力,团队引入时间衰减因子β:当预测在标注片段结束时刻命中时,β=1,若预测时间晚于标注结束时间,β线性衰减,超过阈值后降为0,基于此设计两项在线指标:
两项指标共同要求“又快又准”,贴合安防、直播等场景需求。
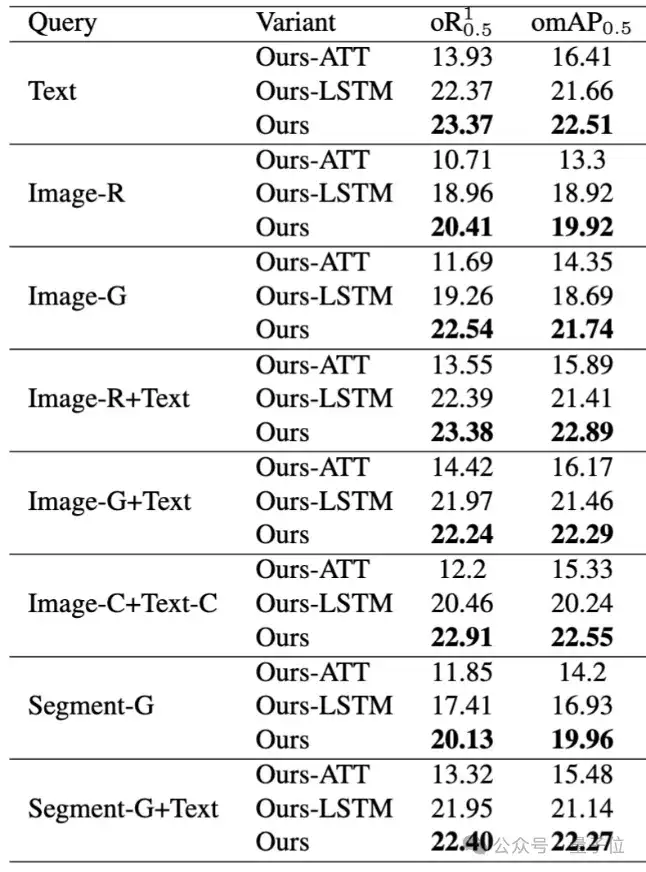
实验结果显示,使用混合模态蒸馏后 ,模型在弱模态处理上显著提升:Image-R提升8.98%,Image-G提升9.35%。

参数化记忆模块效果优于ATT和LSTM,,以生成视频查询(Segment-G)为例,PMB(20.13%)>LSTM(17.41%)>ATT(11.85%)。
总结来说,OVG-HQ任务、QVHighlights-Unify数据集、PMB模块及混合模态蒸馏策略,共同勾勒出实时视频理解的新范式:“用户给任何线索,系统实时在当前视频流中定位完整事件。”这不仅加速安防告警、体育直播回放、VR训练反馈,更为智能家居、工业质检、自动驾驶等场景打开新想象空间。
曾润浩(深圳北理莫斯科大学)、毛嘉其(深圳大学)、赖铭浩(深圳大学)、Minh Hieu Phan(阿德莱德大学)、董延杰(深圳北理莫斯科大学)、王伟(深圳北理莫斯科大学)、陈奇(阿德莱德大学)、胡希平(深圳北理莫斯科大学)
论文链接: https://arxiv.org/abs/2508.11903
文章来自于“量子位”,作者“OVG-HQ团队”。


【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
