# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
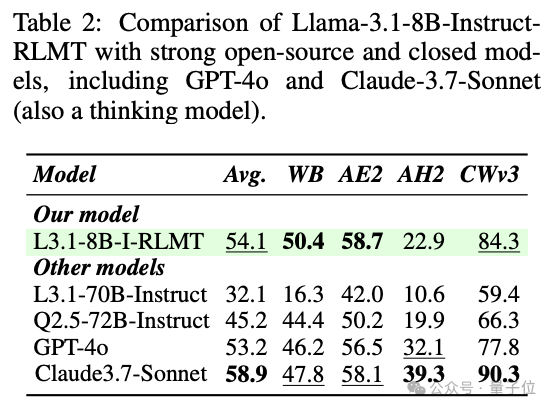
结合RLHF+RLVR,8B小模型就能超越GPT-4o、媲美Claude-3.7-Sonnet。
陈丹琦新作来了。

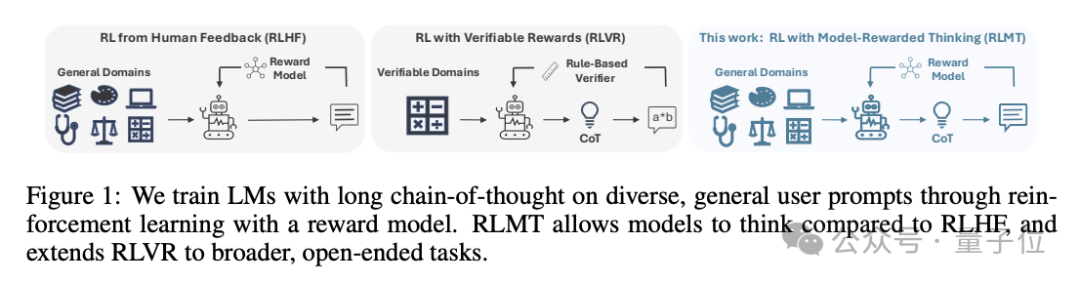
他们提出了一个结合RLHF和RLVR优点的方法,RLMT(Reinforcement Learning with Model-rewarded Thinking,基于模型奖励思维的强化学习)。
它要求模型在回答之前生成CoT,然后使用人类偏好训练的奖励模型来评价输出。
支持在基础模型上直接使用,甚至不需要SFT,可以大幅节省后训练成本。
网友觉得,这种方法为通用强化学习设定了一个新基线:谁制定了偏好的定义,谁就是后训练时代的“新得分手”。
RLVR(通过可验证奖励的强化学习)能够在数学、代码等任务中大幅提升模型的推理能力,但是在更开放的任务(比如写大纲、制定饮食计划)上的泛化能力有限,这些任务是人类日常推理的常见场景。
本文提出的RLMT就是证明,RLVR范式在可验证领域之外同样有效。
它要求模型在生成回答之前输出长思维链(CoT),并利用基于人类偏好的奖励模型(与RLHF中相同)进行在线强化学习。
比如对于非数学代码问题,它依旧可以分步骤拆解:回顾→综合→关键主题→核心准则→举例→结构化回答。

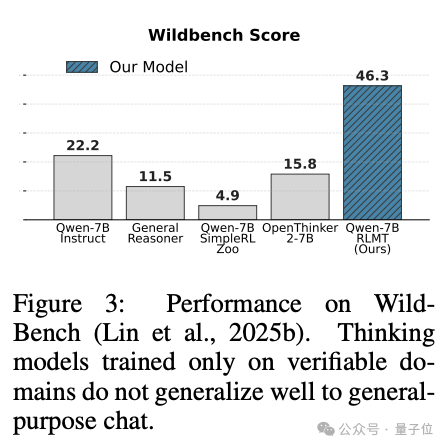
比如在Wildbench(一个基于真实任务建立的基准)上,优化后的Qwen2.5-7B大幅领先其他模型。
它的训练流程如下:
给定一个用户提示x,模型先生成一个推理轨迹z,在推理基础上生成最终回答y,奖励模型r(x,y)对结果进行打分。
数学上,RLMT优化的目标是:
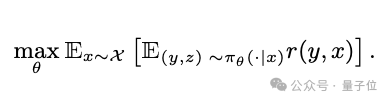
然后使用人类偏好奖励模型(论文中用的是Skywork-v2),对生成的回答在流畅性、相关性、逻辑性、创意等维度给出分数。
在优化算法方面,RLMT使用在线强化学习算法来更新模型参数,主要实验了DPO、PPO、GRPO,结果表明GRPO效果最好。但即使使用DPO/PPO,RLMT也始终优于RLHF。
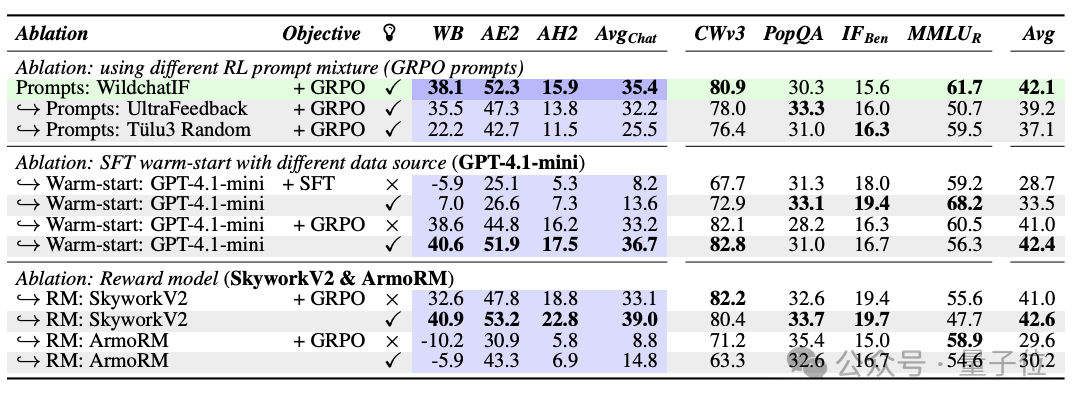
训练数据来自于真实用户对话,避免像RLVR那样过度偏向数学/代码。
训练方式有两种:
最终通过RLMT,模型在推理风格上更像人类思考:它自然学会了分组、约束分析、跨部分联系、迭代修正等,从而带来更高质量的对话和写作效果。
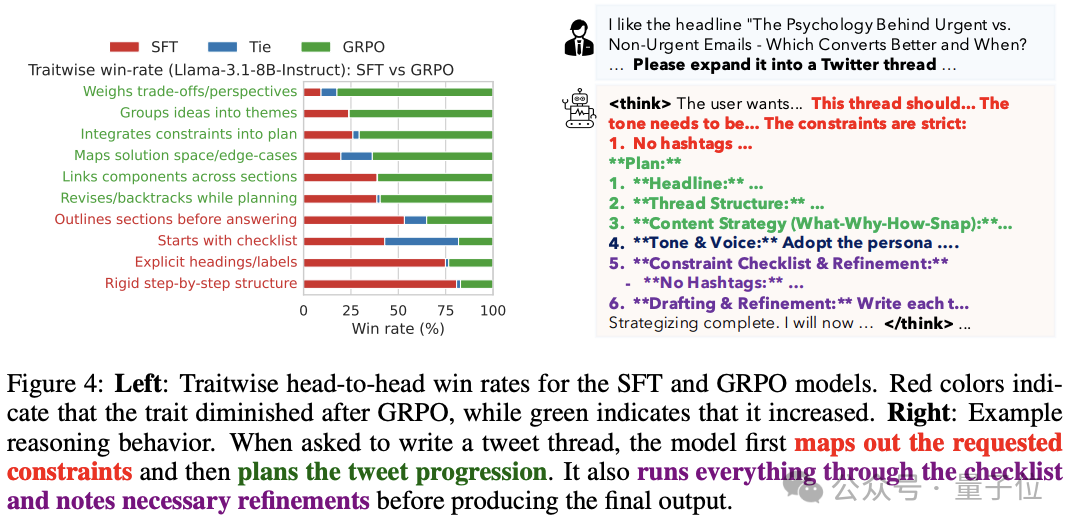
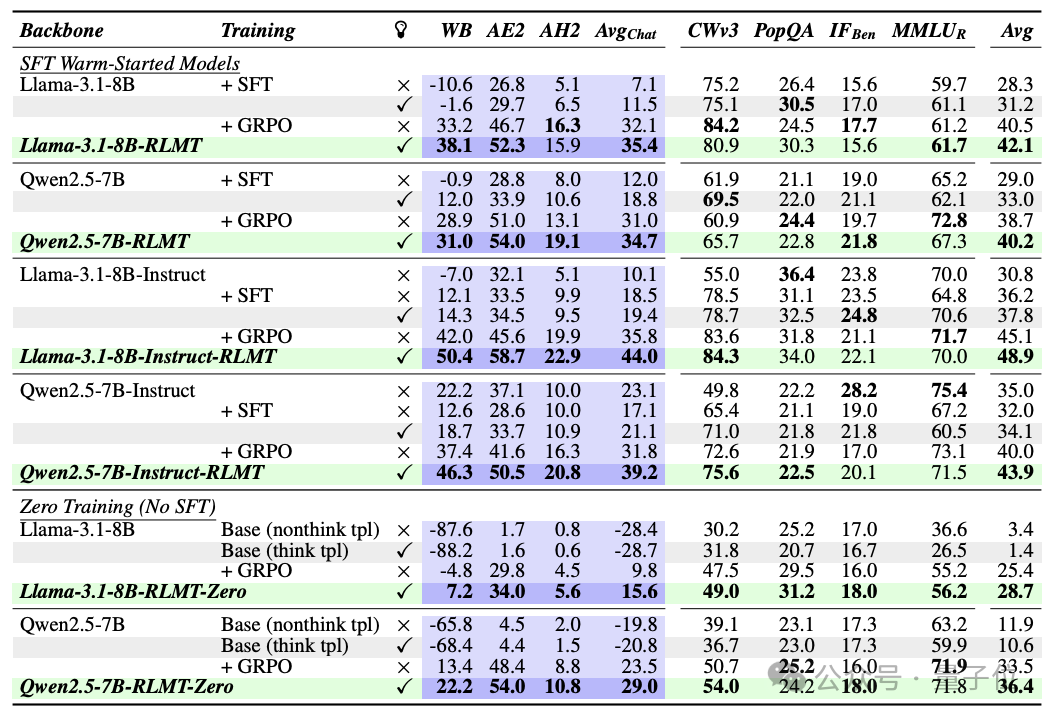
研究团队主要测试了Llama3.1-8B和Qwen2.5-7B两个模型的表现效果。
结果显示小模型经过RLMT训练可超越大模型,大幅简化后训练成本。
本项研究一共三位作者:陈丹琦、Adithya Bhaskar、叶曦。
陈丹琦,普林斯顿大学计算机副教授,普林斯顿NLP小组负责人。最近加盟了Thinking Machines Lab。
她本科就读于清华大学“姚班”,2018年在斯坦福大学获得计算机科学博士学位,导师为Christopher Manning。曾获得诺奖风向标之称的斯隆奖。
她的研究方向主要是自然语言理解、知识表示与推理、问答系统、信息抽取、对话代理等。

研究一作为Adithya Bhaskar和叶曦。
Adithya Bhaskar现在是普林斯顿大学博三学生,师从陈丹琦。

叶曦是普林斯顿语言与智能研究所博士后。
本科毕业于清华大学,在奥斯汀大学获得博士学位。主要研究方向是NLP,重点在提高大语言模型的可解释性和推理能力。
论文地址:https://arxiv.org/abs/2509.20357
文章来自于微信公众号 “量子位”,作者 “量子位”



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
