# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
数字人这赛道也越来越卷了,
大模型可以写剧本,语音模型可以配出百变语气,当我越来越不满足于只是把口型对上这件事之后,
那这个只会坐着、不能走路、表情都是提前预设好的、台词数字人,会如何进化?
刚好最近在内测即梦的数字人新模型 OmniHuman 1.5。(有新模型的地方就有我)
来看看用即梦4.0图像模型配合OmniHuman 1.5数字人模型做出的MV效果怎么样:

数字人终于摆脱原地罚坐、罚站的设定了!
用下来的整体的感受是OmniHuman 1.5听得懂音频里的情绪和语义,能让人物根据文本中的情绪自己随地大小演,还能完成多人角色互动,让他们都配合镜头动起来,同时也支持各种风格角色的大幅度运动并配以口型。
也就是说,我不只是单单给它一个声音让它配个口型,
而是可以让它走位、演戏、调镜头,完成一整场戏。
所以我打算客串影视导演主理人,从语义理解、动作调度、情绪演绎、群体协同以及多风格表演五个维度进行全方位测评,Here we go!
首先来看语义理解,我先设定了一个场景,是一个女人在衣柜中挑选衣服,

然后我给上传了一段音频,音频里讲的话是:
“我的红色外套呢?我今天要穿呢,诶,找到了,在这里,太好啦!”,
同时我在动作提示语中没有给出完全确定的指令,只是说她拿到了自己想要的衣服这样模糊的说法,想要看看OmniHuman 1.5 是不是能成功拿出音频提到的“红色衣服”。
OmniHuman 1.5 生成的人物做出了东翻西找的动作,
而且真的成功拿出衣柜中暗红色的衣服并做出了开心的表情。

然后我又试了个更狠的,我直接只丢了一段音频上去,连动作提示都没给,
直接让OmniHuman 1.5给我生成看看效果。
结果就是,首先即梦识别出了图中的动势做出了两个人一边向前走一边讲话的场景,然后还能判断出音频中的内容是对着另外一个人说的,所以会有男人转头对着女人说话的动作,amazing啊!

那如果基本的动作不用我写提示语即梦自己就可以完成的话,那加上我的提示语是不是也可以完成更复杂的动作调度呢?甚至能配合上镜头变化?
所以,这次我在让他完成说话对口型的同时设置了一连串的时序动作,同时还增加了镜头运动,
男人一直向前走,然后停下抬头仰望天空,然后抬起右手摘下眼镜,然后叹了口气

五个动作都一一完成了,镜头最后也聚焦到了人物的脸部,
人物的表情也都可以配合着音频的情绪来的,整体完成度很高。
再给即梦出一个难题,让主角在做复杂的连续动作的同时还和周围环境有所互动,
男人慌张的快步走进办公室,然后慌张地坐下,然后打开桌子上的笔记本电脑,一边打字一边讲话

生成的时候我们只能提供首帧画面,也就是说 OmniHuman 1.5 在完成动作的同时还能补充出来画面中本来没有的元素,比如说这个凳子、电脑都是模型自主生成的,但是人物依然能和这些新生成的物品进行流畅的互动。
接着我们来看情绪表演,测试数字人的情绪比较灵的办法就是让ta哭,
是不是哭得够自然,能不能将这个悲伤的氛围传递出去。

OmniHuman 1.5会根据音频的情绪起伏决定角色的表演,像这个音频中人物悲伤的情绪是克制的,是慢慢表露出的痛苦,更多的是迷茫和无奈,所以在最后角色慢慢坐在地上呆呆的看着地面的时候,我也觉得情绪是对的。
反过来,当我用同一张图片,但是换了一个情绪起伏非常大的音频时,人物也会做出悲伤程度更加浓烈,表情动作幅度都比较大的表现。
即使换成愤怒的情绪,只给“暴跳如雷”四个字的动作指示,即梦也能做出不错的效果(而且用即梦内置的配音时,尤其是愤怒的情绪可以多用叹号表达愤怒的程度,实测还有点用,邪修办法又+1)
PS:要是即梦的音频可以咬字不那么清晰就更像真人做的了。

其实前面已经可以看到如果是多人画面的话,除了正在说话的主人公之外,其余的角色也会对主角的行动和表现做出相应的反应,这就说明即梦的OmniHuman 1.5其实是可以演群戏的!
在多人场景中,即梦会自动识别出场景中的人物角色,我们可以自主选择说话的人物然后生成,
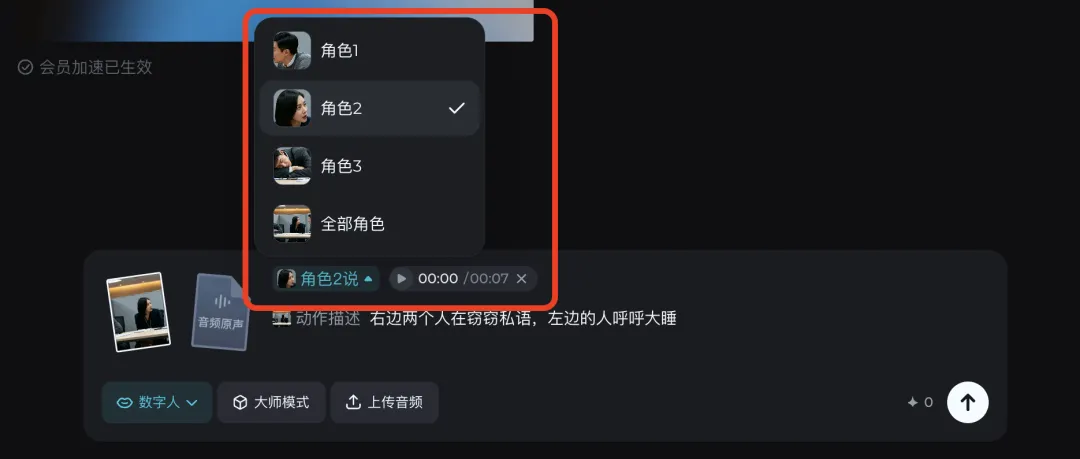
可以看到,首先会判断正在说话的女人对话的对象应该是她身边这个醒着的男人,而这个男人在听到女人的讲到“小声点”之后竟然还做出了用手比嘘的动作,这个真的有点牛了。

而当我换成人物更多的场景,需要更多人物进行反应时,即梦也能很合理的安排好画面中所有人的动作和表情,就比如三个人在听完女人讲笑话之后全都拍桌大笑。

同时我还测试了一些风格化的画面,生成效果都有适配对应风格的动态,人物的动作效果也都蛮自然的。

如果说前几代的数字人模型更像是布景演员,
摆好位置,架好相机,它们照着流程走。
那现在的OmniHuman 1.5,已经可以在即梦web端上体验,明天也会更新到App端,
它生成的人物就像是一个个可以被我们“执导”的数字演员。
它能听懂声音背后的情绪起伏,是带着语气、带着演技去演;是可以走进场景、互动交错、配合镜头的角色;甚至是在多人场景中自觉给自己合理加戏,
我已经开始琢磨更多新的玩法了,
一个人拍多角剧?整段数字MV?或者做个第一人称视角剧?
OmniHuman 1.5 这次更新,
相当于一次性打开了很多可能性,
快挑花眼了都。
文章来自于微信公众号“卡尔的AI沃茨”,作者是“AI沃茨”。


【开源免费】Fay开源数字人框架是一个AI数字人项目,该项目可以帮你实现“线上线下的数字人销售员”,
“一个人机交互的数字人助理”或者是一个一个可以自主决策、主动联系管理员的智能体数字人。
项目地址:https://github.com/xszyou/Fay
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
