# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
今天,Thinking Machines重磅推出了它的第三篇论文《LoRA Without Regret》。
博客地址:https://thinkingmachines.ai/blog/lora/
论文由John Schulman与Thinking Machines其他人联合完成。
如今,最先进的大模型参数量已经超过一万亿,预训练数据量常常多达数十万亿Token。
如此庞大的参数对于基础模型性能的提升是必要的。
但这在后训练阶段就显得有些浪费了,这正是参数高效微调(PEFT)出现的原因。
最常用的方法是LoRA(低秩适配)。它的思路是不直接更新原始的巨大权重矩阵W,而是给它加上一个小小的修正项:
W′=W+γBA
这里的B和A是两个低秩矩阵,它们的参数数量远少于W,而γ是一个常数缩放因子。
换句话说,LoRA通过低维矩阵乘积来捕捉微调带来的更新。那么LoRA能否与完全微调性能相当?如果可以,又是在什么条件下?
Thinking Machines研究发现,只要把握几个关键细节,LoRA也可以与FullFT达到相近表现。
LoRA的关键因素
在本文中,研究人员通过一系列监督微调与强化学习实验,探讨LoRA在何种条件下能与FullFT一样高效。
研究人员发现:
研究人员在Tulu3数据集和OpenThoughts3的一个子集上进行单轮训练,针对每个数据集和模型规模遍历了LoRA秩和学习率。
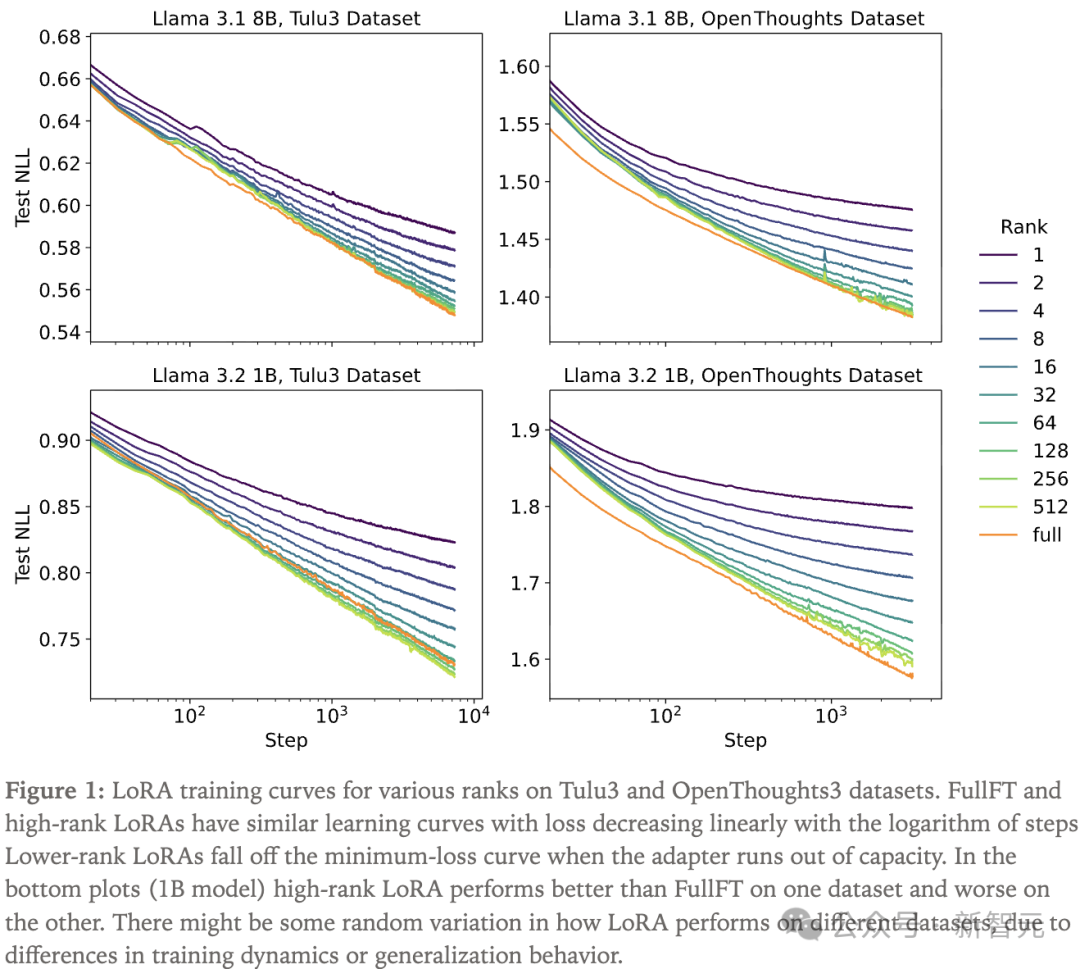
研究人员发现,FullFT与高秩LoRA的学习曲线相似,损失随训练步数对数线性下降。而中低秩LoRA会在某个与秩相关的阈值步数之后偏离最小损失曲线。
从直观上看,当适配器容量耗尽时,学习速度会放缓,这由秩决定。
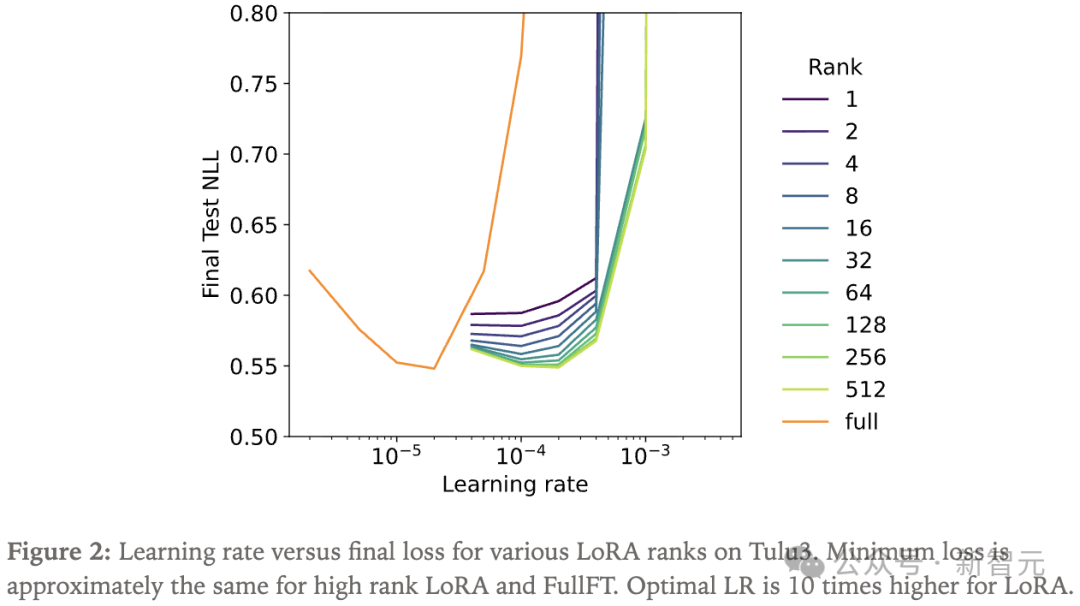
通过绘制损失随学习率变化的曲线,研究人员确认学习率搜索覆盖了每个秩的最佳值,发现FullFT的最佳学习率比高秩LoRA低约10倍。
批大小效应
在训练神经网络时,我们不会一次把所有数据都丢进去,所以用批大小(batch size)来衡量每一批数据中包含多少个样本。
研究人员在实验中发现,在某些情况下,LoRA对大批量训练的容忍度低于FullFT。性能差距随批量增大而扩大,与秩无关。
实验人员使用了OpenThoughts3的一个10000样本的小型子集。
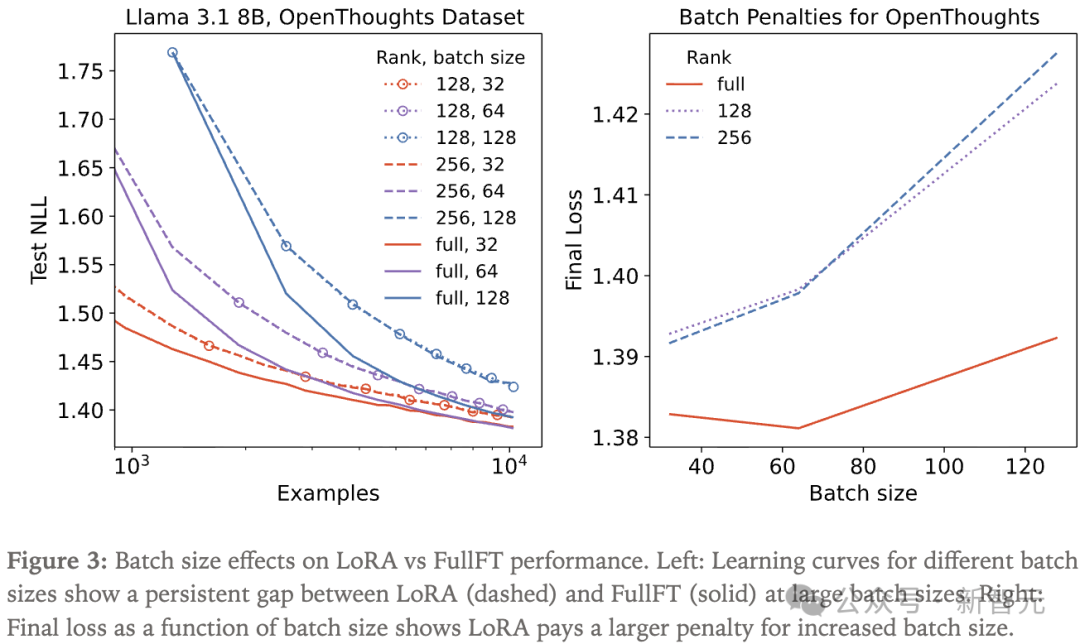
图3左图显示了在大批量下,LoRA(虚线)与FullFT(实线)的学习曲线始终存在差距。而在较小批量(32)下,这一差距更小且随时间缩小。
右图展示了最终损失随批量大小的变化。可以看到,随着批量增大,LoRA的损失与FullFT的差距逐渐拉大。
大批量下的学习差距似乎与秩无关,而是LoRA固有的特性。
研究人员认为其可能原因在于矩阵乘积参数化(BA)的优化动态不如完整矩阵(W)。
LoRA应用层研究
研究人员将LoRA应用于网络不同层,发现当把LoRA应用于所有层时,尤其是MLP(包括MoE)层时,效果要好得多。
实际上,把LoRA用在注意力矩阵上并没有比只用在MLP上更有优势。仅注意力的LoRA表现不佳,并不是因为参数更少。
在这个实验中,rank=256的仅注意力LoRA表现不如rank=128仅MLP LoRA,尽管它们的参数量差不多(见下表加粗数字对比)。
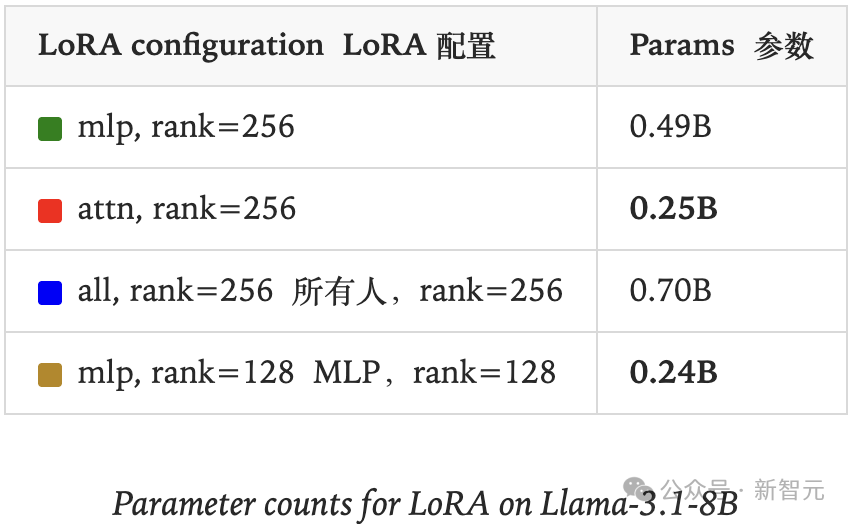
研究人员还在两个额外场景下做了类似的对比实验:
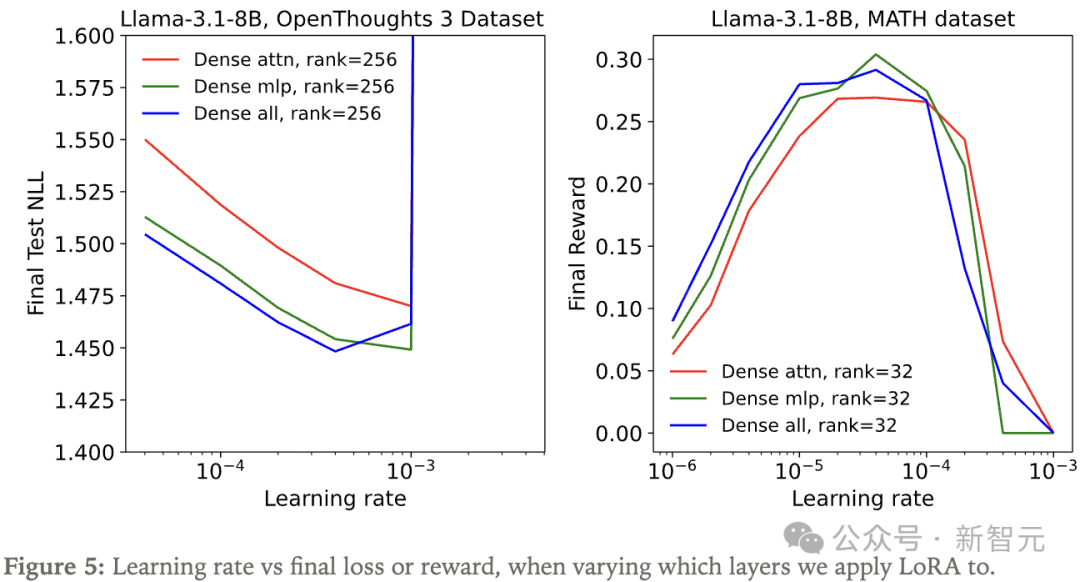
(1)在OpenThoughts3数据集的小子集上(rank=256)做监督学习;
(2)在MATH数据集上做强化学习。
在这两种情况下,仅注意力LoRA的表现依然不如仅MLP LoRA。
强化学习
该实验的一个关键发现是:在用策略梯度算法做强化学习时,即使rank低至1,LoRA也能完全匹配全参数微调的学习效果。
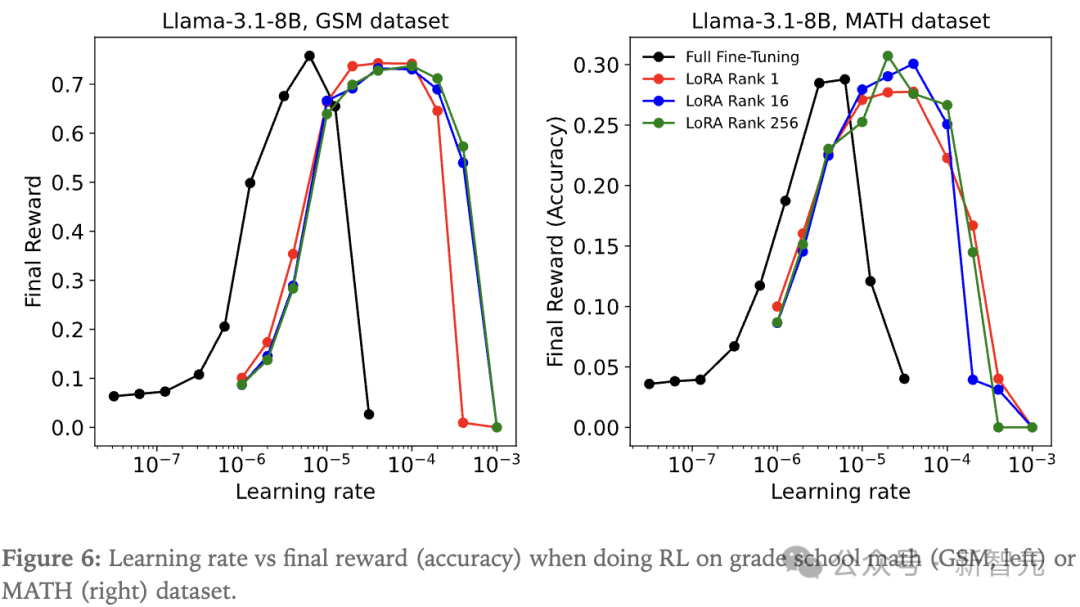
图6中展示了在MATH数据集和GSM数据集上的学习率扫描结果,使用了各自常用的超参数。
研究人员采用了Llama-3.1-8B基座模型,发现LoRA展现出更宽的有效学习率范围,并能达到与全参数微调(黑线)相同的峰值性能。
为了进一步验证LoRA在推理强化学习中的有效性,研究人员还在DeepMath数据集上做了更大规模的实验。
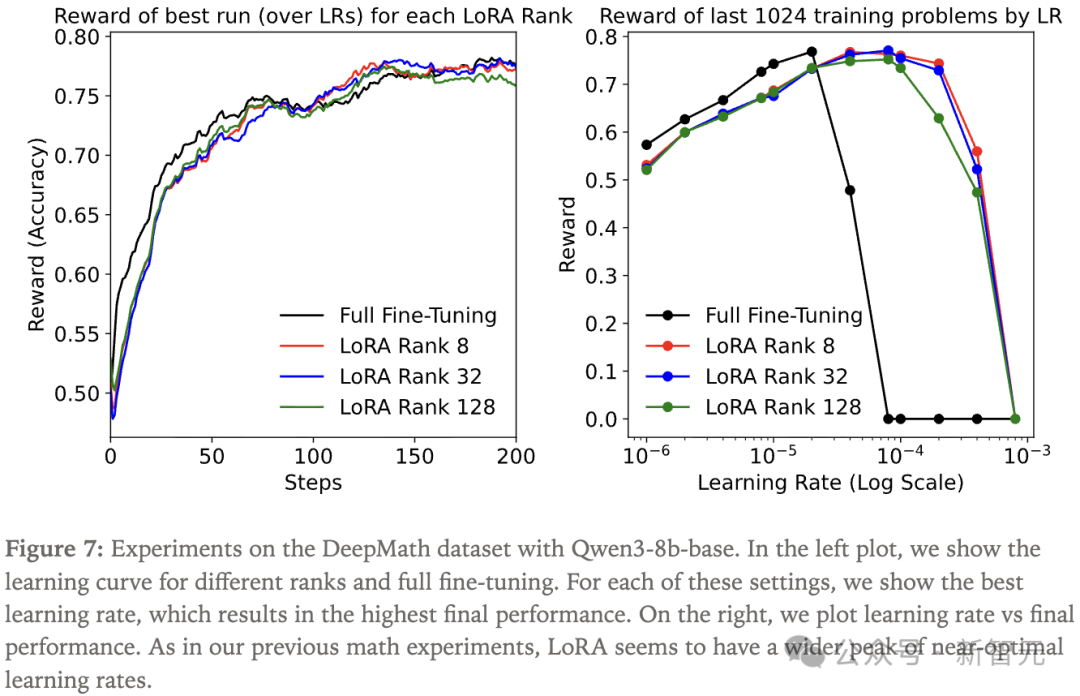
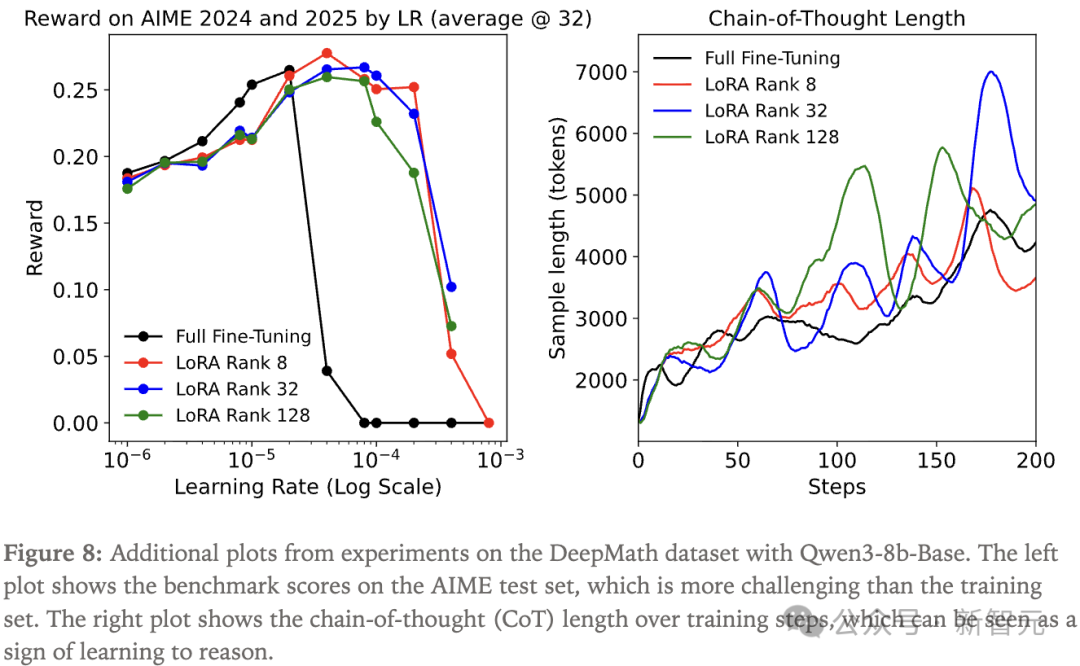
研究人员观察到,在每个设定下选择最优学习率时,不同大小的LoRA与全参数微调的训练进展几乎完全一致。
设置LoRA超参数
LoRA采用的一个障碍在于必须选择合适的超参数,而这些超参数与为FullFT优化的并不相同。
研究人员采用了如下的LoRA参数化方式:
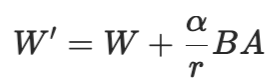
其中,r是LoRA秩,α是LoRA缩放因子,A、B是LoRA权重矩阵(秩为r)。在本文的实验中,研究人员采用α=32。
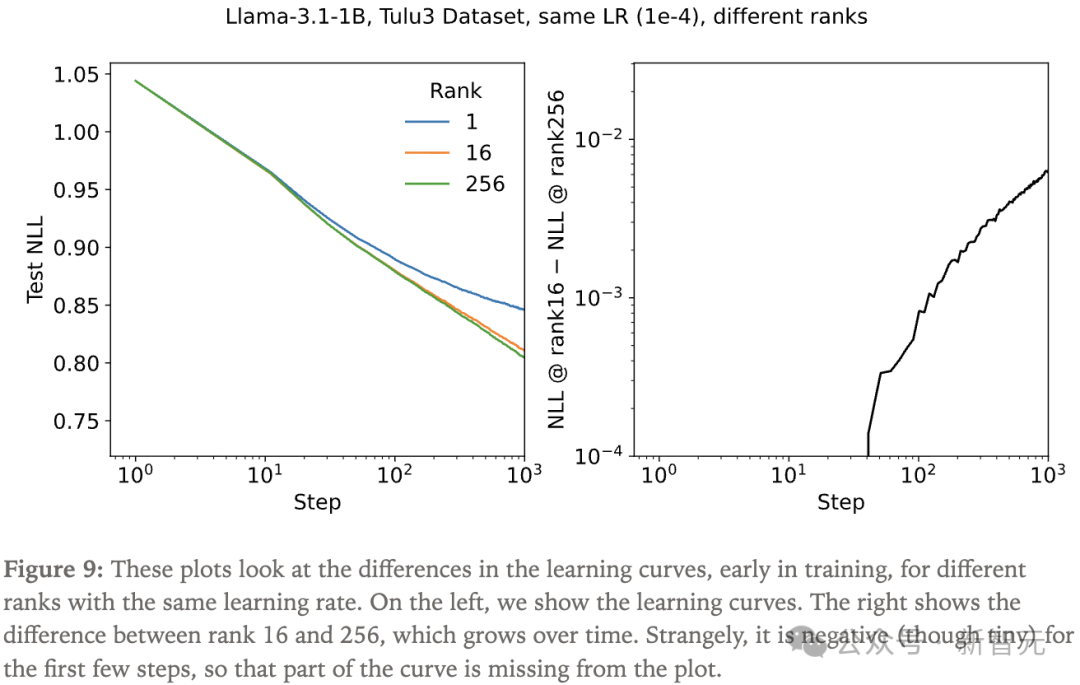
图9展示了在相同学习率下,不同秩在训练初期学习曲线的差异。
LoRA与FullFT的最优学习率比较
该实验表明,在相同的应用中,无论是监督学习还是强化学习,LoRA的最优学习率始终是FullFT的10倍。
这一点在性能(损失或奖励)随学习率变化的U形曲线中一再出现。
这说明可以更容易地把FullFT的学习率迁移到LoRA中。
研究人员目前还没有对这一观察给出充分的理论解释,但认为可以尝试从以下事实出发推导:LoRA的最优学习率与秩无关,而满秩LoRA可直接与FullFT对比。
在实证分析中,研究人员对14个不同的Llama和Qwen模型在Tulu3数据集上同时进行了LoRA和FullFT的学习率扫描。
通过这些扫描结果拟合了一个函数,能基于模型的隐层维度以及其来源(Llama或Qwen)来预测最优学习率:
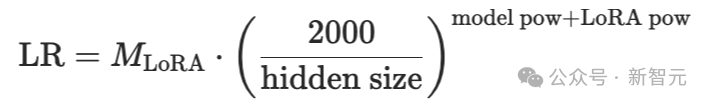
在短期和长期训练中的学习率方面,LoRA的典型初始化方式会在有效学习率上隐式引入一个随时间变化的调度,这导致短期和长期训练表现出差异,且与FullFT相比,学习曲线形状也有所不同。
在训练开始时,B初始化为零。当B很小时,A的变化对适配器BA的影响几乎可以忽略。
随着B逐渐变大,A的更新对网络输出的影响开始增大,有效学习率会随着训练进程逐渐提升,因为B的规模逐渐接近A。
研究人员发现,在Tulu3和OpenThoughts数据集的完整训练结束时,B矩阵的谱范数比A矩阵更大。
这意味着在短期训练中,最优学习率应该设得更高。
初步证据表明,在短期(大约100步以内)训练时,LoRA最优倍数大约是FullFT的15倍,随着训练时间变长,收敛到前文提到的10倍。
在本文的研究中,研究人员发现LoRA与FullFT达到相近表现需要满足的两个条件:
条件1:LoRA应用于网络的所有层,尤其是包含大多数参数的 MLP/MoE(混合专家)层。
条件2:在不受容量约束时,LoRA表现良好,即可训练参数的数量要多于需要学习的信息量。
当条件1满足时,训练一开始就会看到与FullFT相似的学习动态。随后,依据条件2,LoRA会持续呈现与FullFT相近的表现,直到开始触及容量上限为止。
Thinking Machines关注LoRA,旨在推动其更广泛地应用于各种按需定制的场景,也有助于帮助我们更深入地审视机器学习中的一些基本问题。
参考资料:
https://thinkingmachines.ai/blog/lora/%20
https://x.com/thinkymachines/status/1972708674100765006
文章来自于微信公众号 “新智元”,作者 “新智元”


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
