# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
古人早已洞见:真正的人类智慧,不仅仅在于公式推演、掌握技艺,更是能理解他人、洞察人心。今天的大语言模型已能在代码、数学与工具使用上出色地完成任务,然而距离成为真正的用户伙伴,它们依旧缺少那份 “知人” 的能力。这主要源于现实交互远比解题更加复杂:
这正是智能体面临的下一个时代课题:从 “会解题” 迈向 “懂用户”。而要真正回答这一课题,我们需要全新的动态评测框架与训练机制:不仅能测量模型在交互中的表现,还能驱动其学会在用户不确定与多目标的世界里,问之有道,断之有衡,答之有据。为此,来自 UIUC 与 Salesforce 的研究团队提出了一套系统化方案:
二者相辅相成,把 “以用户为中心” 从理念落地为可复现的流程、接口与评测指标。


核心思想
UserBench 的核心出发点是:真正的智能体价值不在于完成任务本身,而在于是否能够理解用户、服务用户。不同于传统评测大多进行的 “做题比赛”,其通过刻画三类 “用户特征”,并将它们嵌入到可复现的环境与标准化接口之中,从而把 “用户价值” 从抽象理念转化为可量化的研究对象。
1. 设计原则
长期以来,智能体的评测大多集中在工具调用与任务完成,但却鲜少触及一个更根本的问题:模型是否真正对齐了用户的潜在与动态意图。
UserBench 的设计正是为了解决这一缺口。它把 “用户真实交互三大特征” 作为评测核心:
在这样的环境里,模型不再是 “照题答题”,而是必须主动追问、澄清约束,并在复杂条件下做出连贯而明智的决策。
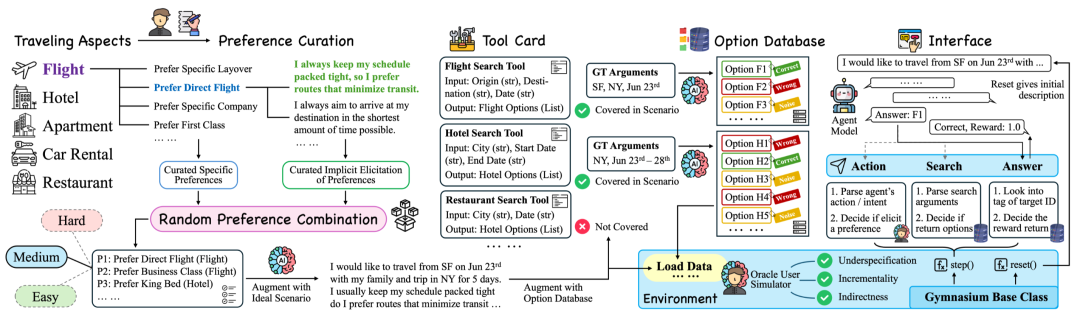
UserBench 设计与交互流程示意图
2. 环境与数据构造
UserBench 的标志性设计是旅行规划任务,覆盖五个子场景。每个维度都设置了数十条隐式偏好表述,如 “行程很紧” 暗含 “直飞 / 少中转”,要求模型在与环境中的模拟用户进行交互时,需要理解用户每一句话背后的语义逻辑。同时,环境中内置了稳定数据库后段,并且搜索返回采用了混合式选项进一步增加了模型认知难度:
这使得模型必须学会过滤噪声、权衡约束,而非直接机械化地比对。UserBench 同时也进行了数据难度分层,根据用户偏好的复杂程度涵盖了 Easy/Medium/Hard 三档,这种设计让其既保有真实性(场景、语言与需求均来自真实语料指导下的 LLM 用户模拟),又具备实验可控性。
3. 以工具为界面:标准化交互接口
以往针对模型,用户以及环境的三方交互接口复杂。而在文章中,这种复杂交互被抽象为了三类原语操作:
这三类操作高度浓缩了 “理解 — 检索 — 决策” 的链路,使不同任务可以在同一坐标系下被评估与比较。在 UserRL 训练框架中,这个标准化接口被保留并得以进一步拓展,使模型训练也变得可以自由定制化和拓展。
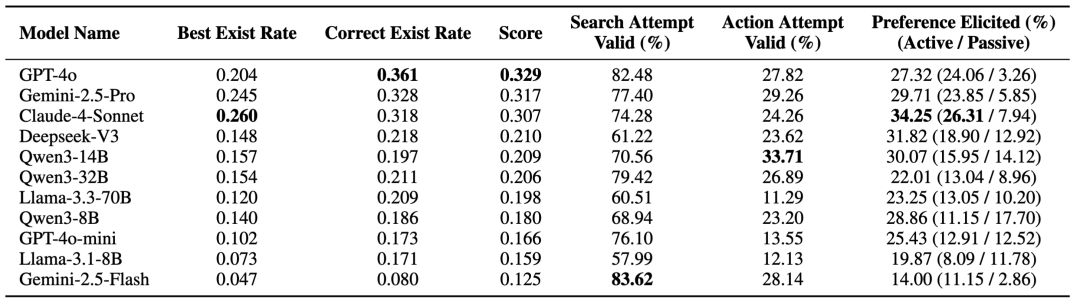
UserBench 上不同模型主要评测结果以及分析指标
4. 评价指标与关键发现
UserBench 的评分体系兼顾结果与过程:
主要结论:模型并非输在 “不会算”,而是常常没能问对问题、没能挖出关键信息。换言之,真正的挑战不是推理链,而是智能体与人的交互中进行有效的 “用户价值” 提炼与捕捉。
关键发现
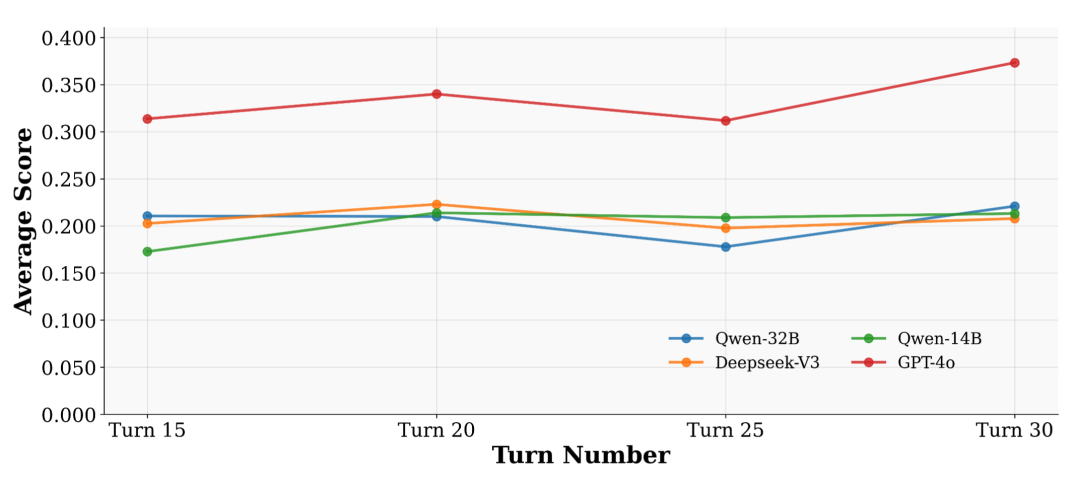
盲目增加交互轮数并不能增强交互质量
核心思想
UserRL 的出发点相比更加直接:在 UserBench 抽象出的三个原语接口之上,构建一个统一的 gym 环境,把 User-in-th-Loop 的多轮交互转化为一个可训练的强化学习问题。这意味着,智能体不再只是完成一次问答,而是要在一个有明确定义的交互环境中,通过多轮对话和工具调用来优化回报。
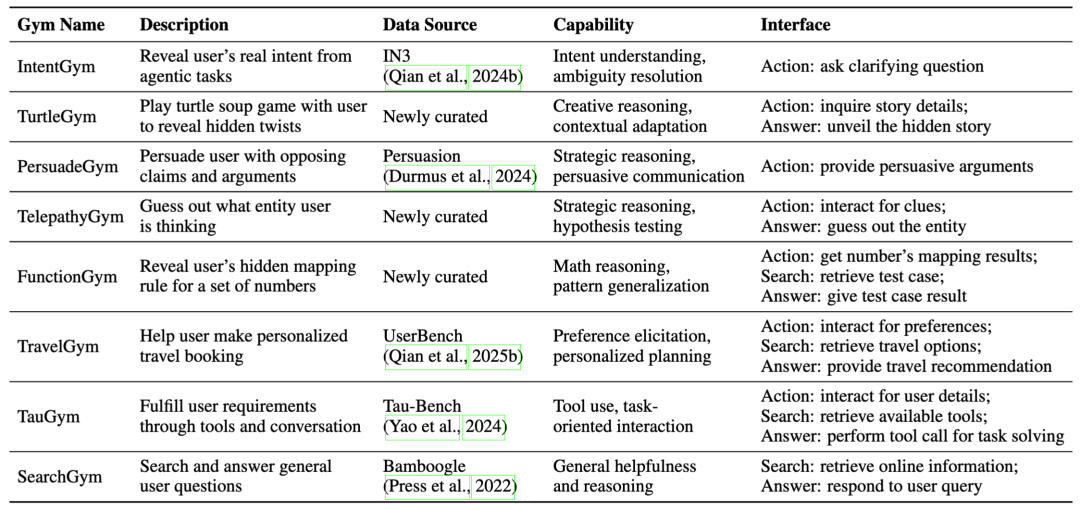
UserRL 中进行训练的八个用户中心场景设计
1. 八大 Gym Environments:能力光谱的全覆盖
UserRL 对接了八类环境,覆盖从个性化推荐到复杂推理的多维能力:
所有环境都统一在 Action / Search / Answer 的接口下,但考察指标有所差异。这种统一接口 + 多元任务的设计,使得 UserRL 既能横向比较不同方法,又能纵向推动能力迁移。
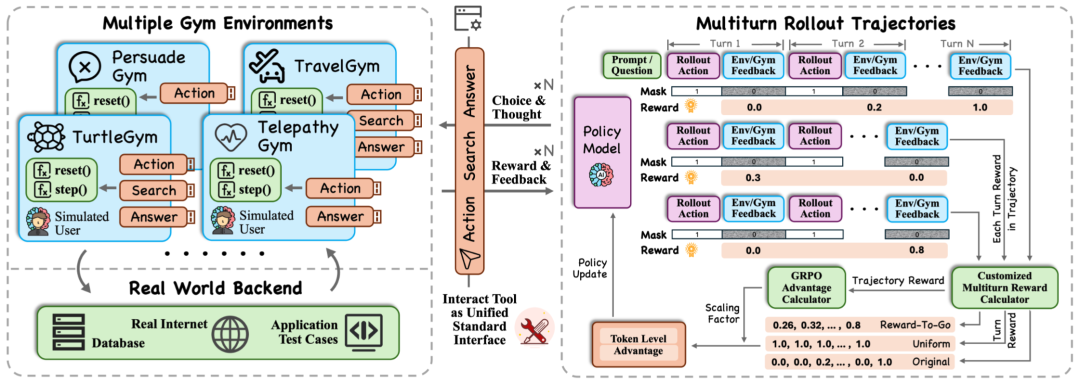
UserRL 完整训练框架示意图
2. 用户模拟与多轮 Rollout
在每个环境中,用户同样由 LLM 进行模拟,并且可以更换不同用户模拟模型,以实现交互的多样性。UserRL 框架的核心特点包括:
3. 奖励建模:让过程价值变成可学信号
在 UserRL 中,我们重点探索了双层奖励设计:回合层(Turn-level)以及轨迹层(Trajectory-level)。在回合层中,我们重新映射 Gym 环境在每一轮中反馈的奖励信号,探索了多种方法以区分不同层的重要性:
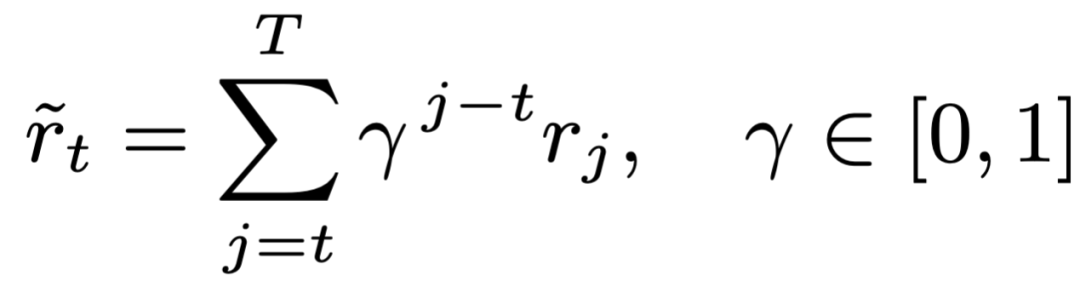
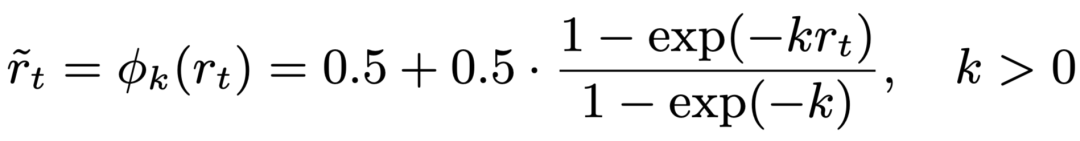
在轨迹层中,我们将每一轮的奖励反馈整合成与用户多轮交互的总体得分,以便于后续适配 GRPO 等下游各种 RL 算法,其中我们主要探索了两种整合方式:
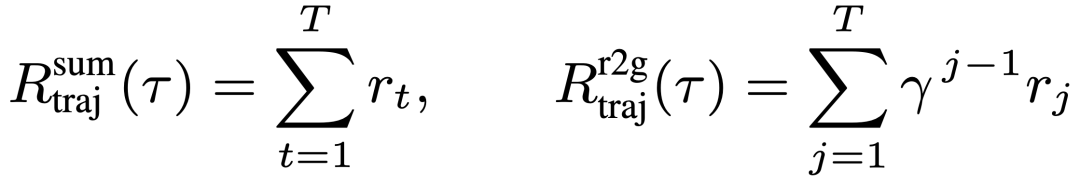
在实际训练中这两层奖励可以灵活组合以适配不同交互任务。
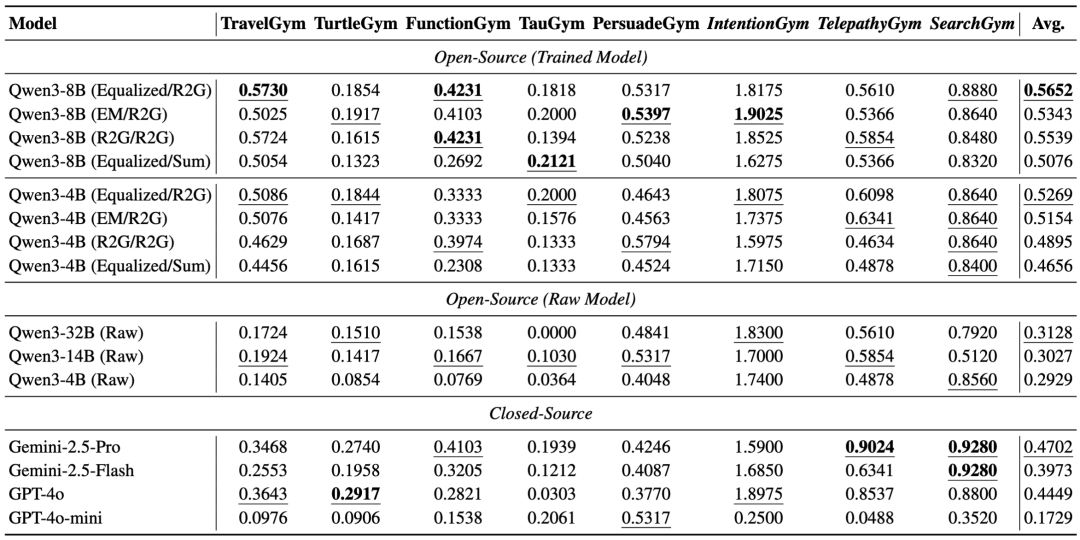
UserRL 训练主要试验结果
4. 评价指标与关键发现
文章主要采用了 GRPO 算法进行优化:在同一 query 下采样多条轨迹,组内归一化优势,再结合回合与轨迹奖励进行联合优化。同时,在 RL 训练之前,模型预先进行了 SFT 小规模优化,实验发现 SFT 冷启动能够有效帮助后续 RL 训练。
UserRL 用其中的五个 Gym 的训练集数据进行训练,另外三个 Gym 则作为 OOD 环境进行测试。所有主实验均采用 Qwen3-32B 作为用户模拟。不同任务的测试指标不尽相同,但是都是以准确度作为衡量基础。
主要结论:模型的提升并非来自更复杂的算力堆叠,而是得益于对过程价值的刻画与利用。换言之,真正的突破点不在于 “终局答案对不对”,而在于能否在多轮交互中持续累积小进展、尽早对齐用户意图,并把这种过程性价值转化为学习信号。
关键总结果
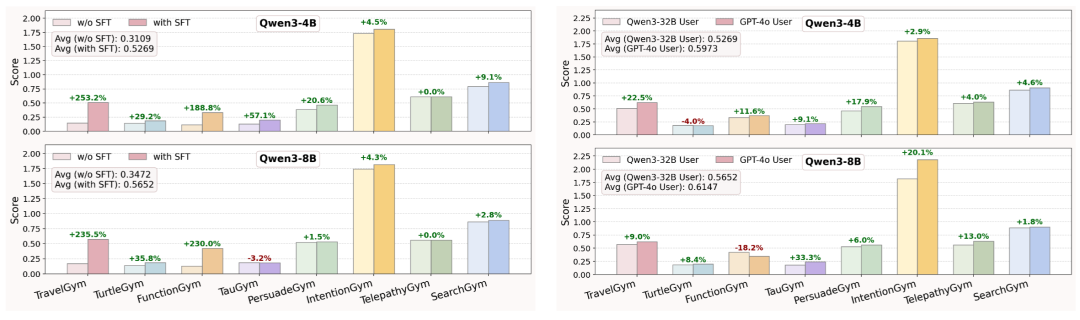

SFT 冷启动(左侧对照)与 GPT-4o 作为模拟用户(右侧对照)均能带来更好的 RL 效果
UserBench 提供了一面 “明镜”,让我们得以量化模型是否真正理解用户;UserRL 则把这面镜子变成 “磨刀石”,推动模型在交互中不断迭代,学会在模糊与多目标之间提炼价值。
《论语》有云:“君子和而不同。” 未来的通用智能体,也应当在理解用户多元价值的同时,学会和而不同:既能尊重偏好,又能提供建设性选择;既能满足需求,又能引导更优解。这,才是通向真正通用智能的必要一课。
所有环境、数据以及训练框架已开源,欢迎研究人员探索。
文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
