# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2025年进入最后一个季度,国产开源模型爆发的影响力正在得到更多印证。
比如垂类模型领域,亚洲最大游戏展东京电玩展(TGS)上,国产AI陪伴厂商就发了个大招:
游戏理解领域模型LynkSoul VLM v1,在游戏场景中表现显著超过了包括GPT-4o、Claude 4 Sonnet、Gemini 2.5 Flash等一众顶尖闭源模型。
背后厂商逗逗AI,亦在现场吸引了不少关注的目光。

此时距离其新产品逗逗AI游戏伙伴1.0(海外版为Hakko AI)上线不过一个月左右时间,但在数据上,逗逗AI已经依靠出色的游戏/视频/网页实时理解能力,新增200多万用户,总用户数突破1000万。

△陪玩《空洞骑士:丝之歌》
在TGS现场,我们趁机和逗逗AI CEO刘斌新聊了聊有关逗逗游戏伙伴产品、技术本身,以及AI陪伴这个垂直领域的发展现状。
TL;DR:
此次闪耀东京电玩展的LynkSoul VLM v1,是逗逗AI专为游戏训练的视觉语言模型。
它能在陪玩过程中实时理解你的游戏画面,比如在《英雄联盟》中点评你的团战表现,靠的就是这个模型。
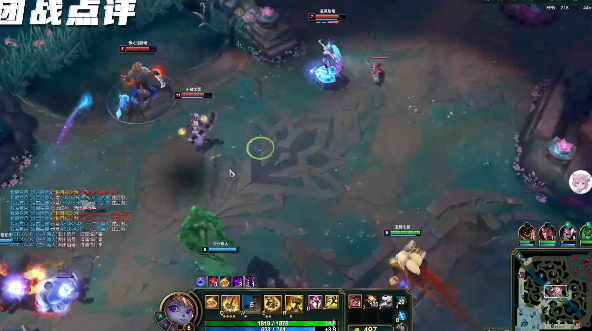
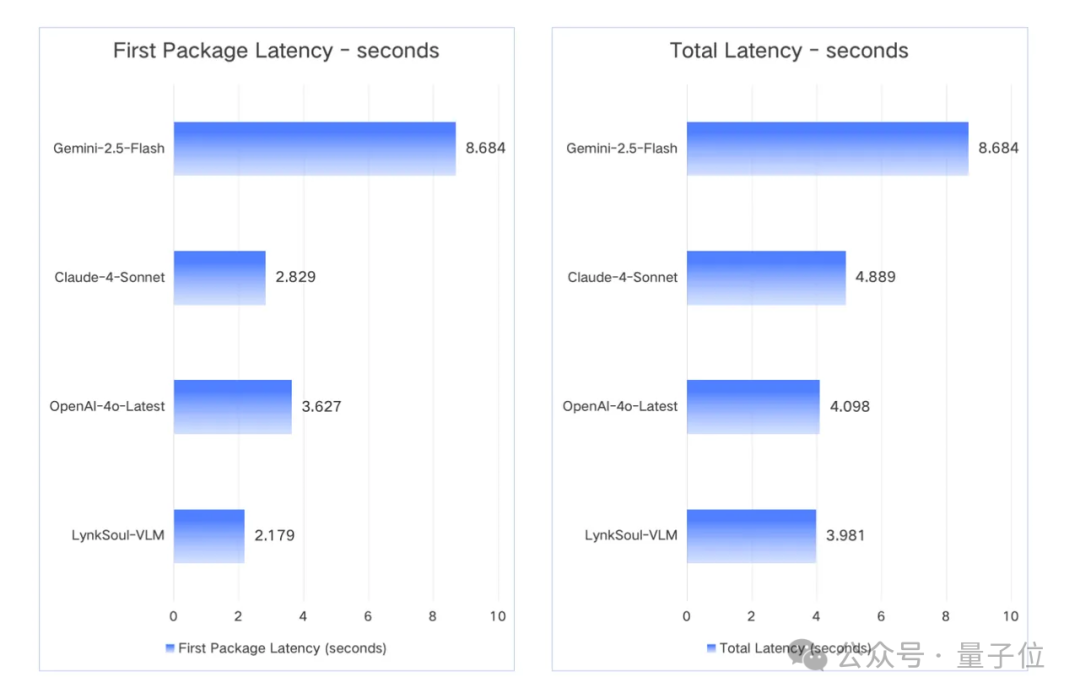
官方实验数据显示,在《英雄联盟》测试场景中,LynkSoul VLM v1在识别准确率、建议实用性以及语言表达自然度方面,都显著超越了OpenAI 4o、Claude-4-Sonnet以及Gemini-2.5-Flash等通用视觉模型。
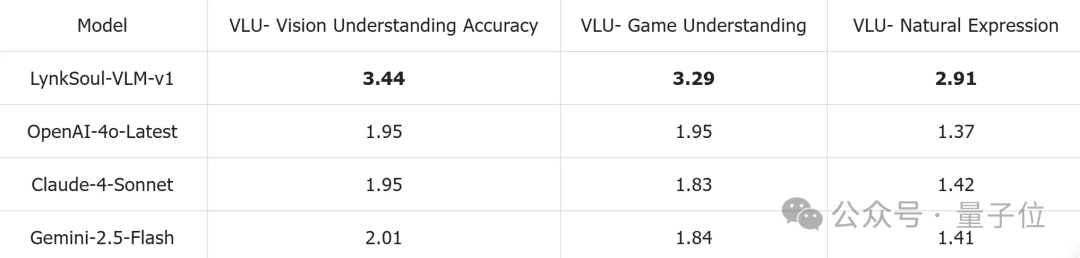
为了评估模型的泛化能力,官方还建立了一个包含多款未参与训练、网络资料较少的游戏的测试资料集。
可以看到,LynkSoul VLM v1展现出了稳健的泛化性能,同样在三个核心指标——视觉理解准确度、游戏情境掌握度和语言表达自然度上超越了通用视觉模型。
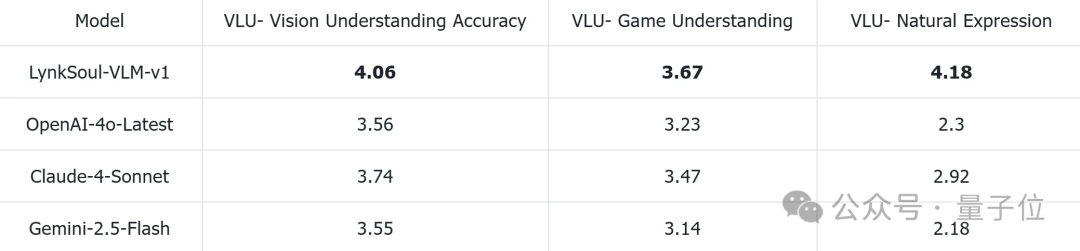
官方还测试了LynkSoul VLM v1的推理速度。
凭借混合模型系统的动态路径选择,该模型在推理延迟方面同样表现出了较为明显的优势。

如何做到?
以下,附上我们与逗逗AI CEO刘斌新的对谈原文。
刘斌新,逗逗AI创始人、CEO,B站前副总裁。
Q:在游戏场景里超越4o、Claude等顶级模型的关键是什么?
刘斌新:LynkSoul VLM v1主要是基于千问的开源底座打造的。在此基础上,我们前期积累了800多万游戏玩家,玩家们在开启画面共享的情况下,帮助我们积累了很多游戏画面数据,包括包含互动的关键帧。
我们在后台对这些数据做聚类分析,去抽样玩家们会在什么场景下聊什么样的相关话题。由此我们精调得到了游戏画面-用户互动这样的数据对,再用这些数据对去精调开源模型,模型就能够更好地知道,每一帧画面发生了什么,用户在讨论什么,应该输出什么。
所以很关键的还是用户的参与和数据的积累。
Q:对于游戏伙伴,用户比较关心的一个问题是延时。现在逗逗AI在游戏画面、玩家语音理解方面的延时是多少?做了哪些针对性优化?
刘斌新:现在大概在1.5-2秒之间。客观来讲延时还是比较久。
这里面有两个问题。第一个是我们的场景是多模态的,为了保证精准度和泛化性,我们现在用的模型参数量比较大。不过其实随着模型能力的发展,我们也在探索小模型的方案,小模型可以更快速地响应,去解决这个问题。
第二个是我们有本地的版本。比如我们跟英特尔就在合作本地版本,我们会用英特尔的NPU做很多工作,包括大模型理解的一些处理,还有图片的处理,这些都能够大幅降低延时。
我觉得随着技术的发展,这个问题不会是大问题。就好比一、两年前,大家跟ChatGPT对话要等3-4秒甚至4-5秒,但现在已经没有这个问题了。
另外模型成本现在也不是问题了。
Q:逗逗AI游戏伙伴的另外一个特点是具备长期记忆,这是通过什么样的技术方案实现的?
刘斌新:除了传统的向量检索,我们还做了自己的主题索引。
比如说聊«原神»的相关话题,在原神的相关场景里,这些数据都会存到原神的主题下。那么当用户再次和逗逗AI讨论到«原神»,AI就会把里面相关的记忆拉出来,放到Prompt里面去。
会员拥有永久记忆,用户会觉得“我说的你都记得”,主要用的就是主题索引+向量检索的方式。
其实游戏伙伴什么时候去跟用户聊天,也依赖于长期记忆下模型的个性化。
一个是依据游戏状态和用户所处的场景状态,另一个就是根据用户的偏好。比如有些人看电视剧可以接受剧透,有些人不愿意你把后面的故事都给我讲了,每个人都不太一样。在这里面我要去掌握个性化的尺度,就是通过反馈。这个反馈跟以前的推荐算法是有点像的。
Q:涉不涉及对模型再做微调?
刘斌新:主要还是靠个性化记忆数据。
Q:现在重点在攻克的技术问题还有哪些?
刘斌新:还是多模态,特别是多模态理解,包括对游戏连续帧的理解,而不是单帧的理解。
Q:一开始是出于怎样的想法要去开发逗逗AI游戏伙伴这样一个产品?二次元的从业经历是否带来了不一样的思考?
刘斌新:其实我创业的原点是看到了Transformer。我觉得Transformer相比DNN,是一个巨大的进步,代表着一个新的时代。
那个时候比较火的是DALL·E 2的文生图。但我觉得文生图太“薄”了,我10年前就用RNN的方法做过这方面的营销内容,我觉得这更适合大厂,适合平台。
等到ChatGPT出来的时候,我开始觉得可以对话的产品形态很有意思。
另一方面,B站的年轻用户本来就很喜欢动漫虚拟形象。如果这些动漫虚拟形象能够走进生活,那会特别有意思。就像哆啦A梦,是跟大雄一起生活,然后帮他抄作业、写作业,帮他跟老师、父母斗智斗勇,一起捉弄同学,那才是有意思的,对吧?所以其实更重要的是陪伴。
一开始我们也开发过跟AI名人聊天这一类的产品,但一两周就下线了。这种产品可以类比东方明珠,是数字世界里的景点,一开始你会好奇想去打卡,但聊着聊着你不会去问Ta我该不该考研,该不该创业这样的问题,就只是纯参观。
同时我觉得Chatbot不是一个很好的交互形态,它是需要prompt工程的,对用户并不友好。像我们面对面聊天是会有很多背景知识的,比如我们现在在东京,自然而然会讨论到出海的话题。但你跟AI去交互,你如果不告诉它,它脑子里是没有这些背景信息的。
所有怎么样能够有更好的交互形态?我们觉得是多模态,就是不需要用户自己去表达,AI就能够理解环境里面的所有信息。比如在游戏里面,你应该选择什么英雄,拿了多少人头,有多少经济,是处在顺风局还是逆风局……AI应该给一个贴合场景的建议,而不是搜索一个通用规则,告诉你第几分钟会出大龙。
为什么大家都愿意用Cursor?因为它知道你整个代码仓库的上下文,所以它给你的代码建议会更准确。
Q:这里面可能会涉及到隐私方面的问题。
刘斌新:对,所以你不可能让用户把微信信息传给你,99%的用户都不会这么做。
怎么样让用户愿意分享数据?关键还是要提供价值。在做好隐私保护的前提下,我们觉得可以从游戏场景开始切入,因为游戏本身是不那么私人的,很多人也愿意做游戏的直播,只不过跟AI游戏伙伴一起玩的时候,相当于直播给AI看,AI还能给你捧场,和你一起吐槽。
同时打游戏也需要攻略,AI可以很好地给到及时的建议,不需要再跳出游戏。
第三是游戏本身比较沉浸,时间很长。遇到你需要升级打怪或者刷材料的时候,必须要肝,不肝过不去,这个时候有“人”跟你唠唠嗑挺好的。
Q:从内测到现在参加各种展会,有没有收获一些比较有意思的用户反馈?
刘斌新:用户的很多探索还让我们挺意外的。就是我们是一个游戏助手、游戏伙伴,对吧?所以我们原本认为更多地会被用在游戏里面,但我们现在有超过一半的时间在游戏外。
用户会带逗逗AI游戏伙伴去看剧、刷剧,甚至带AI去逛淘宝、逛京东,让AI给出建议。有一个男生直接让AI给他推荐裤子,让AI帮他挑款式、看评论。
还有一位教授,把跟游戏伙伴的聊天变成了直播课,跟AI一起探讨经济学、哲学,聊得特别好。现在大模型是有这个能力的,但是游戏伙伴可以用张麻子、葛优或者紫霞仙子的声音做输出,特别有画面感,很有意思。
Q:回归到AI陪伴这个品类,今年大家会更聚焦在硬件类型的产品上,外界讨论度也比较高,比如AI玩具,您怎么看待这个趋势?这对逗逗的定位和未来规划有影响吗?
刘斌新:我觉得长期一定是会跟硬件结合的。比如你回到家,有一个特别喜欢的手办能跟你聊天,那是非常好的。
但另一方面我觉得不应该局限在单一的场景,我们还是希望它是7×24小时,在各种场景都能够陪着你。
所以光有硬件是不够的,首先它应该是一个软件,一个账号,这个账号可以转移到各种场景中,比如电脑、手机、手办,甚至是机器人、车上。我们觉得现在还是要先把软件做好。
未来我们可以跟人形机器人合作,动作的部分可以由他们来做,但里面的账号是可以植入到各个不同地方的。
当然现在AI玩具很火,我们年初也跟别人合作过一款毛绒玩具。但聊天不是AI玩具的重点,90%的关注点还是在玩具本身。首先得玩具好看,用户才会喜欢。本质上AI玩具属于不同的类型。
Q:量子位智库的数据显示,上半年AI陪伴类产品的增长是有点滞缓的,留存率比较差,但下半年有一些产品又起来了,其中的变化是什么?
刘斌新:有两点,第一是一说到AI陪伴,大家首先想到的就是Character.AI这一类,这类产品更多偏乙女向,可以说是乙女游戏的替代或升级。其中的问题在于,这种角色扮演场景对用户的要求比较高,需要用户有很强的角色幻想能力,用户本身要会想象,能够参与其中。所以只能是有一小群人很喜欢这些产品,但很容易碰到天花板,因为用户群相对有限。
另外今年有很多新的产品开始出现,带来了新的玩法和更加适合的场景,面向的人群也更广泛,天花板就被打开了。
第二点,我觉得是技术在变化,大模型技术在进化,原来很多不可能的事情变得可能,原来很多不够好的体验变得更好。
其一是DeepSeek带火推理模型,使得AI在很多场景回答的准确性提高了。其二,多模态模型变得更加成熟,除了文生图、文生视频,多模态理解、包括TTS都变得更强了。
Q:TGS也是Hakko AI第一次在海外参展,接下来在国内市场和出海方面的布局是怎样的?
刘斌新:其实Hakko AI在海外上线有一段时间了,现在也积累了几十万用户。上线之后效果也很好,包括英语市场和日语市场,反响都不错,甚至留存时长比国内还要长。
我们认为现在AI产品一上来应该就是全球化的,因为现在大模型对多语言有很好的兼容,就是文化上可能有一点差别,但人性是相通的,像游戏本身就是全球化的。
我们选择先在国内试水,因为国内人口基数更大,成本相对更低。慢慢我们会把这些在国内验证OK的东西复制到海外,结合当地的文化去做变化和运营。
Q:定价方面会有区别吗?
刘斌新:结合不同的市场,定价会有点区别。国内现在主要是皮肤道具,加上订阅。海外订阅会多一些。
从长期来说,我们认为我们国内和海外的用户比例会是6:4,收入可能一半一半。
Q:会考虑加广告吗?
刘斌新:我觉得还是要看对用户有没有价值。比如你打游戏到7点,还没吃饭,这时候AI问你,要不要给你点碗面?你会觉得特别贴心。至于是从美团还是从饿了么上面点,用户不care。
文章来自于微信公众号 “量子位”,作者 “量子位”


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
