# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
讲真,AI生图圈的内卷速度简直离谱。
8月底的Nano Banana、9月中的即梦4.0已经把画质和效果卷到了一个新高度,但我还在纠结到底该把谁设为主力工具,因为总觉得他们差点什么:不是出错就是不懂场景。
结果,昨天我刷X的时候,看到“全球盲测”榜单中,腾讯混元图像3.0一举登顶,已经达到「工业级」的程度,直接把我整不会了。
要知道,腾讯年初才接入deepseek,现在就把自己干成了多模态界的 deepseek?
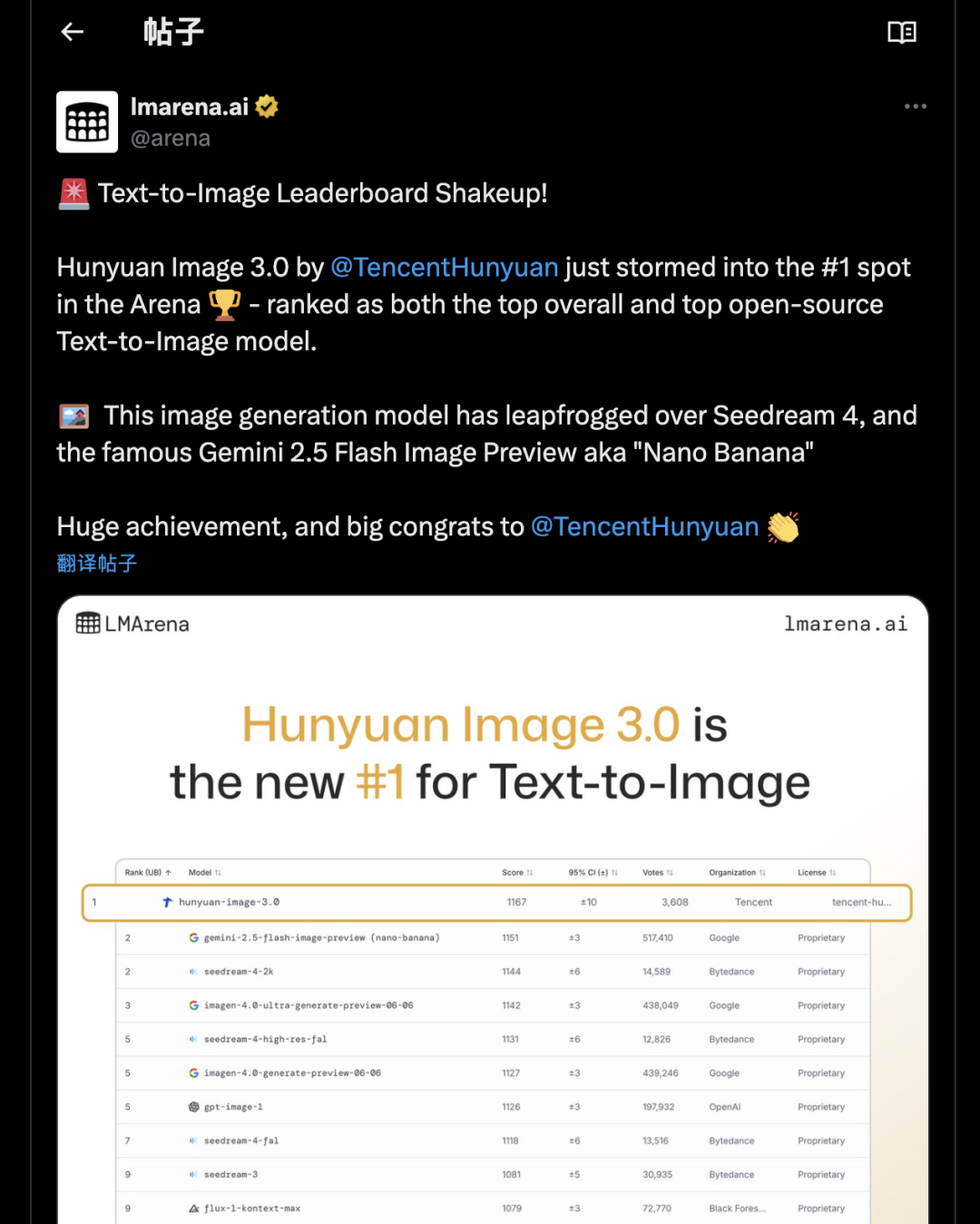
翻译:
文生图排行榜大洗牌!
腾讯混元@TencentHunyuan 发布的混元图像3.0在竞技场中一举夺魁,荣登文生图模型的总榜第一和开源榜第一。这款图像生成模型超越了Seedream 4,以及大名鼎鼎的Gemini 2.5 Flash Image Preview,也就是“Nano Banana”。
这是一项巨大的成就,祝贺@TencentHunyuan!
腾讯混元图像3.0,我在家肝了两天、刷了几百张图后发现,它早就不满足于只做“画图工具”——世界知识、逻辑推理、复杂指令,这些以前的痛点,在它身上都一个个解决了。
下面,我分层拆解下它到底牛在哪。
混元图像3.0最大突破就是它自带“世界知识”,你只需要一句普通的话,剩下的细节和合理布局,它自己就能脑补填补出来——真正让生图从“死板的按图索骥”,变成了“自由发挥的懂行选手”。
我先试了个简单的:让它生成一名数学老师讲解方程组的场景。验证模型是否具备基础的、事实性的逻辑推理能力,而不只是画出表面元素。
💡一名数学老师站在教室黑板前,详细讲解如何解方程组5x+2y=26和2x-y=5,黑板上写有每一步计算过程。


我当时就惊了,还特地拿起笔认真算了一遍,过程和答案竟然完全正确!
输出的图片里,老师姿态自然、黑板步骤正确、居然连算式推导都能自动补全。你不用提“左手粉笔”或“板书过程”,它都帮你想周全。
这种能力,让它在需要专业知识的场景里变得异常强大。
接着我把难度升级,让它做一张运动科普图解:
💡生成一组羽毛球杀球的示意图图解

可以看出来,从引拍到击球的动作拆解,完全符合运动学原理。
能做到这一点,因为它“知道”这个世界是如何运作的。
光会解题还不够,它懂生活常识吗?刚好是中秋节,我让它教我怎么做月饼:
💡用四宫格展示一位厨师制作月饼的四个步骤,加上必要的中文说明


这张图表明,混元图像3.0的知识库不仅包含静态的事实,更包含了动态的、程序性的“过程知识”。
它知道做一件事的先后顺序,这种能力让它在制作教程、说明图解等场景时变得异常强大。
最后用一个难度顶格的测试,检查混元的知识库:
💡一张A1横幅拼贴画,九个格子里各自展示一个知名世界遗产,如长城、吉萨金字塔等,每格下方标有国家名称和列入年份,中英双语,版式美观。

注意,我只给了两个例子。它需要自己去脑补剩下7个,并且准确无误地配上国家和年份。
我特意去找 ChatGPT 老师查证了一下,它还真没瞎编:

证明了它背后拥有一个庞大且结构化的知识库,并具备了“信息检索”和“知识合成” 的能力。
它能理解你的意图,主动查询缺失的信息,并以符合美学要求的方式呈现出来。
说到 AI 生图最痛的地方,文字渲染绝对是重灾区。强如Nano Banana,一遇到长文本或者中文也会开始胡言乱语。
接下来看下混元图像3.0 在文字方面的表现。
先试了个超复杂的英文长文本场景:
💡A wide image taken with a phone of a glass whiteboard, in a room overlooking the Bay Bridge. The field of view shows a woman writing. The handwriting looks natural and a bit messy, and we see the photographer's reflection. The text reads: (left) "Transfer between Modalities: Suppose we directly model p(text, pixels, sound) [equation] with one big autoregressive transformer. Pros: * image generation augmented with vast world knowledge * next-level text rendering * native in-context learning * unified post-training stack Cons: * varying bit-rate across modalities * compute not adaptive" (Right) "Fixes: * model compressed representations * compose autoregressive prior with a powerful decoder" On the bottom right of the board, she draws a diagram: "tokens -> [transformer] -> [diffusion] -> pixels"

这图简直可以用惊艳来描述:不仅文字几乎100%准确,连“ messy handwriting(有点乱的笔迹)”和“ photographer's reflection(摄影师的倒影)”这种细节都完美呈现。
英文说实话,海外模型效果都还行,真正难的是「中文」
难度继续升级,做下面这种高度信息化的海报,对绝大多数模型来说就是“不可能完成的任务”:
💡城市公共安全提示 1080×1920,明黄底黑字;主标题「台风蓝色预警|今夜至明晨」;重点提示「请减少外出…」;清单「1. 取消沿海户外活动 2. 检查门窗… 3. 电动车停止户外充电 4. 地铁2/5号线末班车22:30」;热线横条与二维码;统一图标与网格


效果真的不错,中文没有一个出问题的。
长文本渲染的背后是混元图像3.0 对文字控制的程度之深,可以玩弄于指掌了。
再做更难的文字字体艺术设计看下:
💡创建一个高分辨率文字3D渲染图,第一行是"Hunyuan",第二行是"Image 3.0",每个字母使用不同的材质进行渲染,如sisal、亚麻绳、竹编、棉花、牛仔布、沙子、木头、皮革、粘土、大理石、羊毛、陶瓷、金属、火山熔岩、冰块、火焰、水泥、钻石等,相邻的字母的材质不要一样。 在文字下面是一只戴着红色围脖的Q版腾讯QQ企鹅,它正举起右手打招呼。 将其放置在干净简约的浅灰色背景上。


它能将每一个字母都识别为一个独立的设计单元 (Design Unit),并精准地赋予了截然不同的复杂材质。
这种“单体控制精度”的能力,特别适合做Logo设计、字体海报等创意工作。
AI生图,提示词其实并非写得越详细越好,反而出错概率会越高,因为上下文要处理的逻辑太多,AI 宕机了。
但混元图像3.0对复杂指令的理解能力让我刮目相看。
用这段复杂提示词验证模型在面对包含多层次、多对象、内外空间关系的复杂场景描述时,是否具备强大的空间逻辑和对象关联能力?
💡A whimsical miniature Apple Store, designed to look like a giant Apple product box, complete with the iconic Apple logo and intricate details. The two-story building features large glass windows that clearly showcase a modern and high-end interior: minimalist display tables, bright and gentle lighting, and staff members assisting customers. On the street, adorable little figurines are strolling or relaxing, with benches, street lamps, and potted plants arranged around them, creating a charming corner of the city. The entire scene adopts an urban miniature landscape style, rich in detail and realism, with soft lighting that evokes a pleasant and relaxing afternoon atmosphere.


这个场景包含了建筑设计、室内陈列、人物活动、街景布置等多个层次,混元图像3.0都处理得井井有条。特别是那种微缩模型的质感和氛围都很到位。
说明混元图像3.0的空间推理能力真的强。
继续把测试难度升级。
下图是我之前关注的一个专门研究小红书封面的博主,做的封面图数据都超级好
我一直想用 AI 自动生成,但 Nano banana 啥的都失败了,再用混元试下:

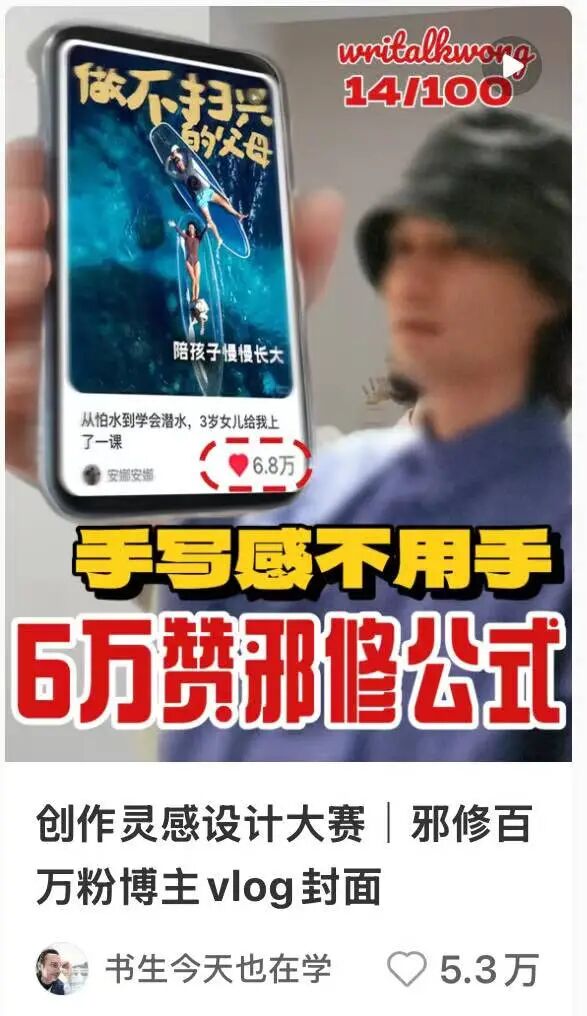

💡
生成一张竖版封面(1080×1440,3:4),主题“AI 绘画|混元生图 3.0”。室内柔光背景,“左屏右人”的非对称构图。画面右侧出现同一个人的半身中景,人物面向左前方、表情兴奋,轻微虚化以突出前景;人物的右臂从身体方向自然伸向左前景,右手握一部银灰色圆角手机,手机微微倾斜并占画面左侧约 45%。请确保“右侧人物”和“持机之手”为同一人:肤色一致、衣袖与手臂材质连续,不要出现脱离身体的手或多余手臂。 手机屏幕清晰显示与“AI 绘画·混元生图 3.0”相关的封面卡片:屏内主画面为卡通 3D/海报风生成效果缩略图,左侧竖排白色大字“混元生图 3.0”,副行小字“AI 绘画”,底部显示红心与“18.6万”(红色虚线圆角框点赞计数)。屏内不出现平台 Logo 或水印。 画面外层文案:中部偏下放一行黄底黑描边的粗体短句“零基础也能玩”,底部放一条红底白描边的超粗体口号“一键出神图”;右上角用手写风红色小字标注“2/100”。整体采用高对比暖色调,字体以无衬线 + 手写风组合,层级清晰、字距紧密、轻微投影;画面干净,不要霓虹特效、复杂纹理、二维码或任何品牌标记。
我勒个豆,效果还意外的不错???


从构图、人物、手机屏幕内容到画面外的两行标题,所有关键元素都精准地出现在了它们该在的位置。
也就是说,混元图像3.0 可以把一段复杂的、充满行业术语的文字Brief,解构成一个个可执行的设计指令,并完美地组装起来。
这种“指哪打哪”的精准执行力,实在太强了。
其实饼干哥哥也非设计师,作为理科男,每次要做图都很痛苦,我知道生出的图不好看,但我真的不知道要怎么才能让它变好看。
所以模型背后的审美对我来说特别重要,我想用带简单风格指向的提示词,就能完美复刻美学审美。
先试下传统国风的图:
💡背景是敦煌壁画,前景是一尊神秘高大的佛像

敦煌壁画的历史厚重感和佛像的庄严神秘感完美融合。
更重要的是,它精准地捕捉到了敦煌艺术那种特有的、经过千年岁月沉淀后的斑驳质感和庄严神韵。光影从洞窟顶部灑下,完美融合了历史的厚重感与佛像的神秘感。
这证明它的审美,是植根于对人类艺术史的深度学习之上的。
国庆中秋双节来临,看下生成节日海报是否好看?
💡平面插画海报,新中式美学,高饱和渐变背景,满月与宫殿剪影;左上标题“CHINESE TRADITIONAL FESTIVALS”(细衬线体);正文含“中秋国庆”“一轮明月恭贺华诞”;底部日期“10.01”“10.06”“2025”,配极小号英文字说明,整体衬线体排版


这种新中式美学的处理真的很有水准,比我在某些设计网站上花钱买的素材还要精美。
继续加大挑战难度,考验模型对“镜头语言”的理解,能否通过模拟真实世界的光影、物理和相机效果,创造出具有故事感和冲击力的电影级画面:
💡超写实特写,巨龙的眼睛,金黄色虹膜,瞳孔竖状,眼内反射山脉与天空,金属光泽鳞片与尖刺,电影级光影


鳞片的金属质感、眼球的湿润反光、瞳孔中倒映的世界,每一个细节都在服务于“幻想生物的真实感”。
💡一个GoPro风格的第一人称视角,冲浪者在一个巨大的蓝色波浪管中滑行,手和板尖在底部边缘可见...水幕上形成光晕和焦散图案...超广角鱼眼构图,前景运动模糊...


GoPro的鱼眼畸变、水浪的焦散效果、板头的运动模糊,都精准复刻了第一人称极限运动的“镜头语感”。
这两个示例表明,混元图像3.0不仅学习了画作,更学习了无数摄影和电影作品,它懂得如何用镜头讲故事。
前面其实已说了这么多技术展示,最重要的还是能解决实际问题。
我测试了几个「电商」工作中最常遇到的场景:
传统电商上新,需要经历产品打样、预约摄影师、拍摄、修图、排版等漫长流程,成本高、周期长。
现在,只需要把需求告诉混元。
💡半透明头戴式耳机,外壳采用半透明晶体材质,结构精密,可以透过材质看到内部的精密电路板,耳机悬挂于简约黑色基座上,构图中央略偏上,色调以深空灰为主基调,融入银白色与石墨黑作为装饰点缀,背景为渐变科技光影,风格定位为极简科技,科技海报创作,营造未来感与冷静高效情感氛围,高品质拍摄效果,运用极简主义表现手法,顶部配置醒目宣传语“智能,让聆听进化”,底部展示“科技 · 简约 · 质感”,点缀文字“未来就在耳边”,彰显商品品质“AI 智能音频新品日”,英文标识“INNOVATION TECHNOLOGY SMART & FUTURE”,文字采用现代极简字体,美观实用并重,画面纯净沉稳,商品突出,科技风格极致体现未来视觉冲击。


这质感、这光影、这排版,说它是专业设计师做的也毫不为过吧?
基础产品图之外,还需要更具风格和意境的KV(主视觉)海报和创意穿搭图,这往往需要更高的创意和审美成本:
💡中式禅意风格月饼礼盒产品摄影,暖金礼盒+两枚月饼,深蓝渐变背景,黑色树枝剪影与白色玉兰花,平视中心视角,柔和光线,突出质感


💡企鹅模特的秋季穿搭:左边是全身照,右边是棕色夹克、黑色百褶裙和靴子的分件展示——写实摄影风格,温暖的大地色系。

在工业、科技类产品中,最难做的图就是“内部结构示意图”或“技术原理图”。
传统方法需要专业的3D建模师花费大量时间渲染,成本极高。
我把这个最硬的骨头,扔给了混元图像3.0:
💡半透明外壳展示洗碗机内部结构,深色背景,橙色发光箭头标示气流路径,清晰文字标注“出风口/进风口”,高端科技氛围


不愧是「工业级」的生图模型,效果太顶了。
这不止是进化,这TM是「新物种」
好了,16个“邪修”玩法测试完毕。
混元图像3.0已经完整地向我们展示了,什么才是真正的“工业级”AI生图模型。
它强大的地方,不在于某一张图画得有多惊艳,而在于它系统性地解决了过去AI生图“不可控”、“不理解”、“不实用”的核心痛点。
老实说,这几天的测试下来,震撼多过惊喜。
AI发展的速度,已经远远超过了我们学习的速度。
过去我们常说“AI是工具”,但现在,它更像一个全能的实习生,你只需要出好Brief,它就能给你超预期的结果。
那么,下一个被颠覆的,会是什么呢?
文章来自于微信公众号 “饼干哥哥AGI”,作者 “饼干哥哥AGI”


【开源免费】LGM是一个AI建模的项目,它可以将你上传的平面图片,变成一个3D的模型。
项目地址:https://github.com/3DTopia/LGM?tab=readme-ov-file
在线使用:https://replicate.com/camenduru/lgm
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
