# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

学术展示视频作为科研交流的重要媒介,制作过程仍高度依赖人工,需要反复进行幻灯片设计、逐页录制和后期剪辑,往往需要数小时才能产出几分钟的视频,效率低下且成本高昂,这凸显了推动学术展示视频自动化生成的必要性。然而,与自然视频生成不同(如 Sora2、Veo3 等扩散模型),学术展示视频面临以下独特挑战:
因此,现有自然视频生成模型和简单的幻灯片 + 语音拼接方法难以胜任,亟需一个系统化的基准和方法来推动自动化、可用的学术视频生成。为了解决以上挑战,本文提出了 Paper2Video 基准对学术展示视频进行评价,并提出一个多智能图框架 PaperTalker,为实现自动化和可用的学术视频生成迈出切实可行的一步:

图 1: Paper2Video 概览


为了评价学术展示视频的质量,本文收集了 101 片论文和对应的作者录制的学术展示视频作为测试基准,并从学术展示视频的用途出发,提出了四个评价指标: Meta Similarity, PresentArena, PresentQuiz 和 IP Memory。
Paper2Video 基准
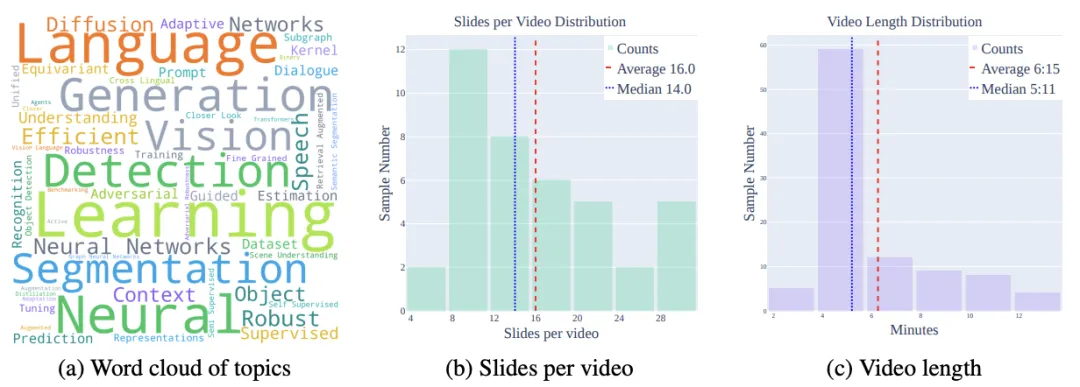
图 2: Paper2Video 基准统计概览
Paper2Video 基准收集了来自近三年顶会的 101 篇论文及其作者录制的展示视频,涵盖机器学习、计算机视觉与自然语言处理领域。每个样例包含论文 LaTeX 工程、幻灯片、展示视频、讲者肖像与语音样本,其中部分还提供原始 PDF 幻灯片。数据统计显示,论文平均 13.3K 字、44.7 幅图表,展示视频平均 16 页幻灯片、时长 6 分钟。
作为首个系统化的学术展示视频基准,它为多模态长文档输入与多通道输出(幻灯片、字幕、语音、光标、讲者)的生成与评估提供了可靠依据,为推动自动化学术展示视频生成奠定了基础。
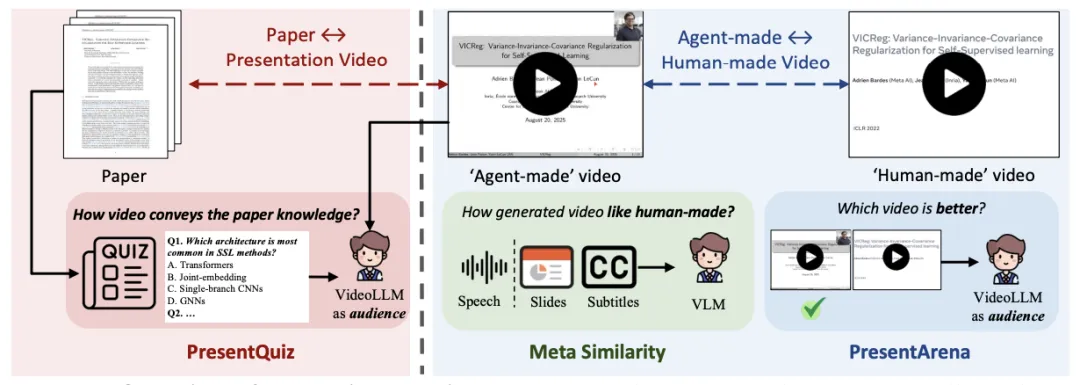
图 3: Paper2Video 评价指标设计
本文从学术展示视频的用途出发,认为其质量应从三个核心视角进行衡量:
基于上述视角,我们设计了四个互补的评价指标:
四个指标共同构建了一个覆盖类人偏好、信息传递与学术记忆的系统化评价框架,为学术展示视频生成的客观测评提供了可靠依据。
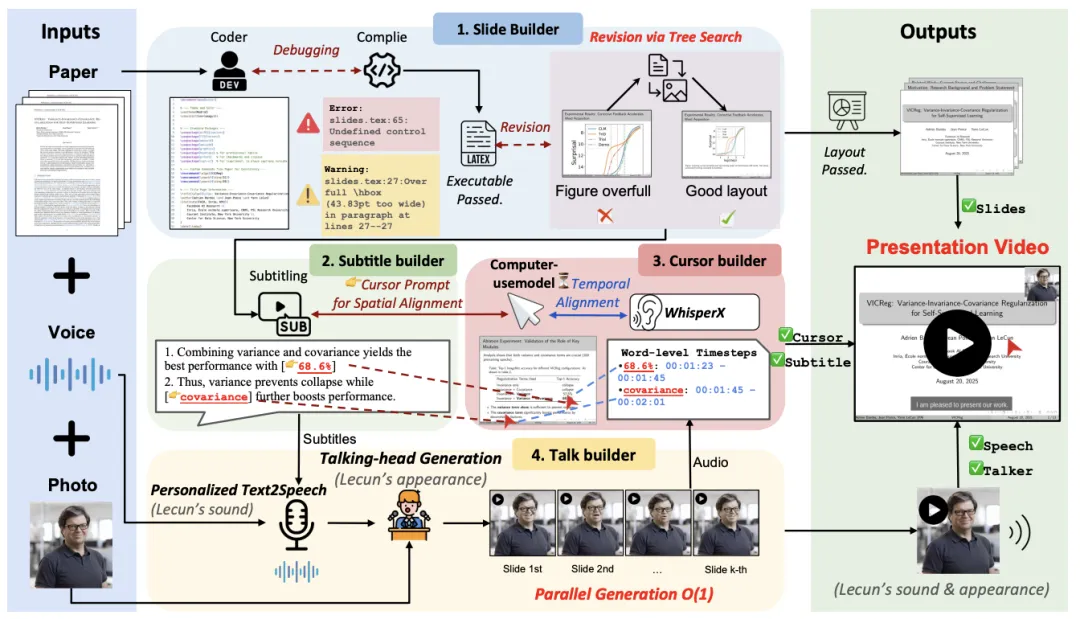
图 4: PaperTalker 流程简介
为解决学术展示视频制作繁琐且难以自动化的问题,本文提出了 PaperTalker —— 首个支持学术展示视频生成的多智能体框架,用于处理这一具有长时依赖的多模态智能体任务(Long-horizon Multi-modal Agentic Task)。该框架以研究论文、讲者图像与语音样本为输入,自动生成包含幻灯片、字幕、语音、光标轨迹和讲者视频 (slide creation, subtitling, speech, cursor highlight, talking head) 的完整展示视频。
PaperTalker 由四个关键构建模块组成:
由此,PaperTalker 通过模块化的多智能体协作,实现了可控、个性化、学术风格化的展示视频生成。
在学术展示视频生成任务中,我们测试发现 LaTeX/Beamer 在输出效果与稳定性上显著优于 pptx,能够直接生成学术风格的幻灯片。但在此过程中,即便是闭源 VLM 也难以鲁棒地判断视觉元素(如图片文字大小、排版比例),导致基于多轮交互的参数调优效率极低。
Tree Search Visual Choice 布局优化机制
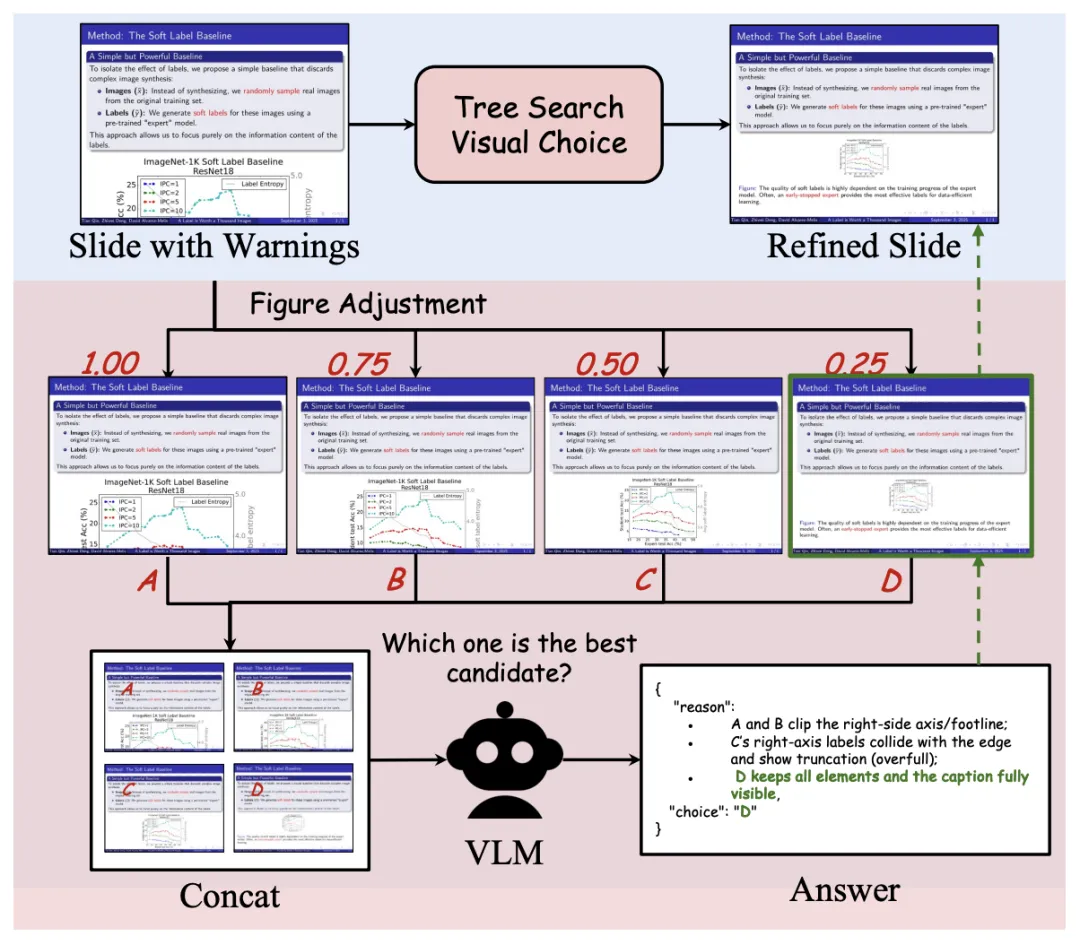
图 5: Tree Search Visual Choice 模块
为此,本文提出 Tree Search Visual Choice:针对给定的视觉素材,预设一组比例参数,渲染得到多种候选布局,并将这些候选拼接成单张大图,交由 VLM 进行一次性的多选比较,从而将低效的多轮参数搜索转化为高效的单轮视觉判别,实现图像尺寸与布局的自动优化。
空间–时间对齐的光标生成
本文进一步探讨了如何模拟人类在讲解过程中使用鼠标的行为。光标轨迹能够引导观众聚焦于幻灯片的关键区域,但实现这一点需要将幻灯片和演讲内容与光标停留点 — 时间戳 — 屏幕空间坐标 (x, y, t) 建立起对应关系。为此,我们引入 Computer-Use 和 WhisperX 模型分别进行空间和时间的标定,实现了时间与空间的双重对齐。
具体来说,我们首先基于幻灯片内容生成逐句字幕及视觉焦点提示,然后利用 UI-TARS 将提示 grounding 为屏幕坐标 (x, y),再通过 WhisperX 获取词级时间戳并对齐到对应的字幕句子,从而得到精确的光标轨迹 (x, y, t)。
高效 Talking-head 生成
在学术展示视频生成中,讲者部分对于增强观众参与感和体现研究者的学术身份至关重要。然而,Talking-Head 渲染通常需要数小时才能生成几分钟的视频,而且部分模型甚至无法原生支持长时段视频的生成,这严重限制了方法的可扩展性与实用性。
为此,本文提出一种高效的解决方案:首先,基于每页幻灯片的字幕与讲者的语音样本,利用 F5-TTS 合成逐页的个性化语音;随后,结合 Hallo2(高保真头像驱动)与 FantasyTalking(支持上半身动作)生成对应的讲者视频。受到人类逐页录制习惯的启发,我们进一步将讲者生成过程 划分为独立的幻灯片片段,并行化执行每页的语音合成与视频渲染。由于幻灯片间存在自然的硬切换,且无需保持跨页的动作连续性,这种设计既保证了身份一致性与唇形同步,又显著提升了整体效率,实验证明这种方式实现了超过 6 倍的加速。
在实验中,本文对比了三类方法:
(i) 端到端方法(如 Wan2.2、Veo3),直接从文本或提示生成视频;
(ii) 多智能体框架(如 PresentAgent、PPTAgent),将论文内容转化为幻灯片并结合文本转语音生成展示视频;
(iii) 本文提出的 PaperTalker,通过幻灯片生成与布局优化、字幕与光标对齐以及个性化讲者合成来生成的学术展示视频。
学术演示视频性能比较
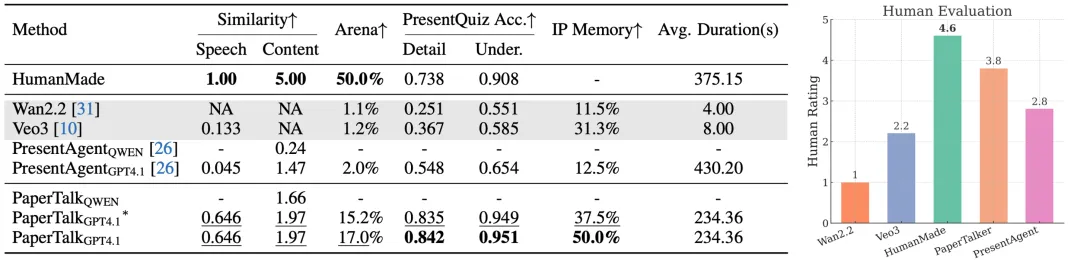
图 6: 学术演示视频性能比较
实验结果表明,本文提出的 PaperTalker 在 Meta Similarity、PresentArena、PresentQuiz 和 IP Memory 四个维度均取得最佳表现:其生成的幻灯片、字幕与语音更接近人类作品,整体观感更受偏好,知识传递更完整,且在学术身份记忆方面更具优势;同时,人类主观评价也显示 PaperTalker 的视频质量接近人工录制水平。
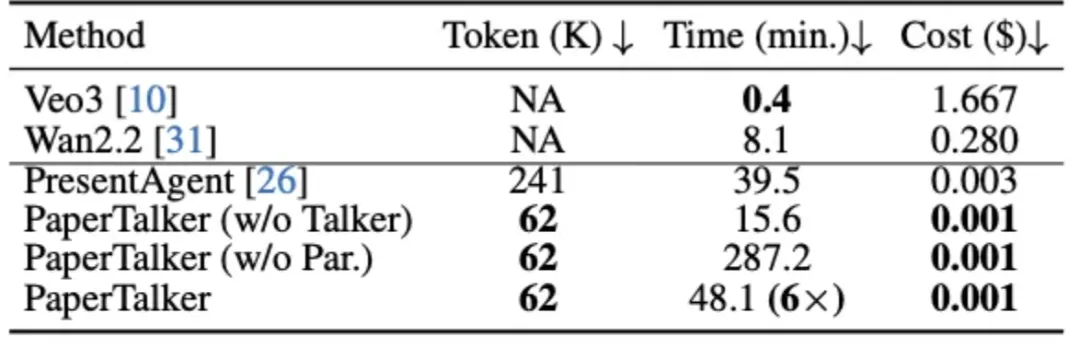
图 7: 模型效率比较
PaperTalker 在生成成本上最低。其效率主要来自三个方面:(i) 基于 Beamer 的幻灯片生成显著减少了 token 消耗;(ii) 引入轻量化的 tree search visual choice 作为幻灯片的后处理;(iii) 采用并行的 talking-head 生成机制缩短了整体运行时间。相比之下,PresentAgent 由于在幻灯片编辑过程中频繁依赖大模型查询,导致成本更高。
光标提示对信息定位与理解的贡献
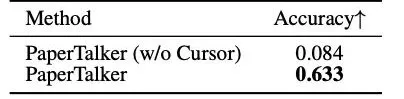
图 8: 光标提示消融实验
光标提示通过提供显式空间线索,帮助观众和 VLM 更好地定位幻灯片中的关键信息。为验证这一点,本文设计了定位问答任务,比较有无光标情况下的答题准确率。结果显示,带光标的视频准确率显著更高,证明了光标在增强学术展示视频的视觉定位与内容可达性方面的重要作用。
Tree Search Visual Choice 在幻灯片质量提升中的作用
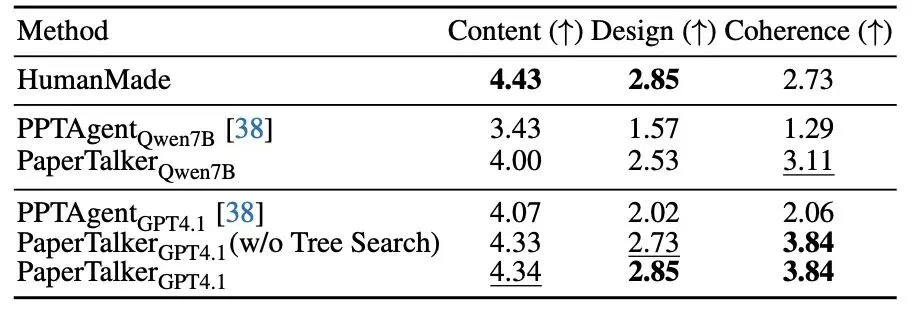
图 9: Tree Search Visual Choice 消融实验
为评估 Tree Search Visual Choice 模块的贡献,本文进行了消融实验(表 5),利用 VLM 从内容、设计与连贯性三个维度对生成的幻灯片进行 1–5 分评价。结果显示,当去除该模块时,幻灯片的设计质量明显下降,说明该方法在解决版面溢出问题、提升整体设计质量方面发挥了关键作用。图 9 展示了该模块的性能。

图 10: Tree Search Visual Choice 可视化
本文提出 Paper2Video 基准与 PaperTalker 框架,为学术展示视频生成提供了系统化任务与评测体系。实验验证了其在信息传递、观感质量与学术记忆方面的优势,生成效果接近人工水平。我们期待这项工作能推动 AI4Research 的发展,促进科研交流的自动化与规模化。

Paper2Video生成Paper2Video学术视频
文章来自于“机器之心”,作者“Zeyu Zhu 祝泽宇(博士生)与 Kevin Qinghong Lin 林庆泓(博士生)”。


【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
