# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
作为视频创作者,你是否曾梦想复刻《盗梦空间》里颠覆物理的旋转镜头,或是重现《泰坦尼克号》船头经典的追踪运镜?
在 AI 视频生成中,这些依赖精确相机运动的创意,实现起来却往往异常困难。
一个直接的想法是先用相机位姿估计模型从参考视频中提取相机参数,然后使用相机参数作为控制条件引导视频生成过程。
然而,这条看似容易的路径,实则充满了陷阱:现实场景中的动态物体和复杂遮挡关系,常常导致模型估算出的相机参数出现偏差或错误,让生成的运镜效果与预期大相径庭。
为了解决这一痛点,香港中文大学与快手可灵团队联合提出了一种全新的运镜可控的视频生成框架 CamCloneMaster。它引入了一种「参考即用」的新范式,用户只需提供一段参考视频,模型就能直接「克隆」其相机运动并应用于新内容,从根本上告别了对相机参数的依赖。该工作被计算机图形学顶级会议 SIGGRAPH Asia 2025 接收,其训练、测试代码和高质量渲染数据集 CamClone Dataset 均已开源。该工作所提出的数据集规模宏大,包含115万数据对,39.1万视频,覆盖40个不同的3D场景,9.77万条多样化的相机轨迹。


a) 相机可控的图生视频(I2V)


b) 相机可控的视频重运镜(V2V)


研究者表示,CamCloneMaster 的主要创新点是:
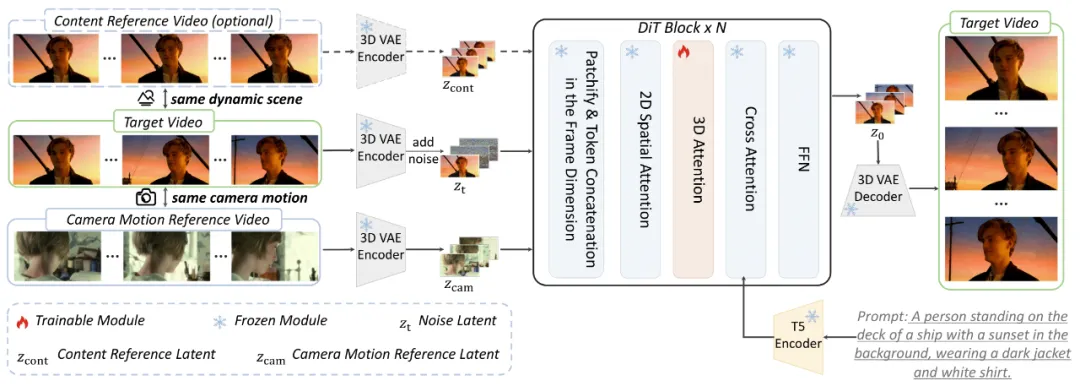
如上图所示,CamCloneMaster 的核心算法和框架极为简单有效:它将作为条件的相机运动参考视频(Camera Motion Reference)和可选的内容参考视频(Content Reference),通过一个 3D VAE 编码器转换成潜在空间的 Latent Tokens。
随后,这些条件 Tokens 与需要去噪的目标视频的噪声 Tokens,在时间维度(Frame Dimension)上进行直接拼接。拼接后的序列被送入 Diffusion Transformer 中进行处理。这种设计使得模型可以通过注意力机制来学习如何利用来自参考视频的相机运动线索和内容信息,从而指导视频的生成。
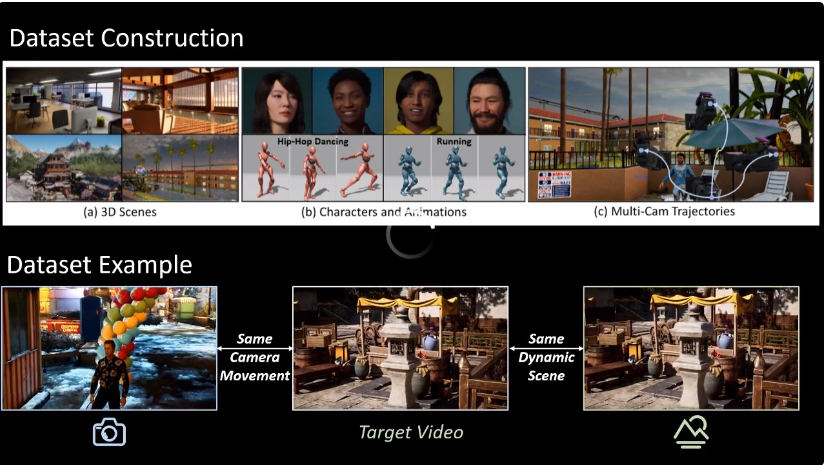
为了有效地训练模型学习「克隆」相机运动,团队使用虚幻引擎 5(Unreal Engine 5)构建了一个庞大的高质量合成数据集——Camera Clone Dataset:
在定量和定性比较中,CamCloneMaster 在各项指标上均显著优于当前的 SOTA 方法:
定性实验结果:


定量实验结果:
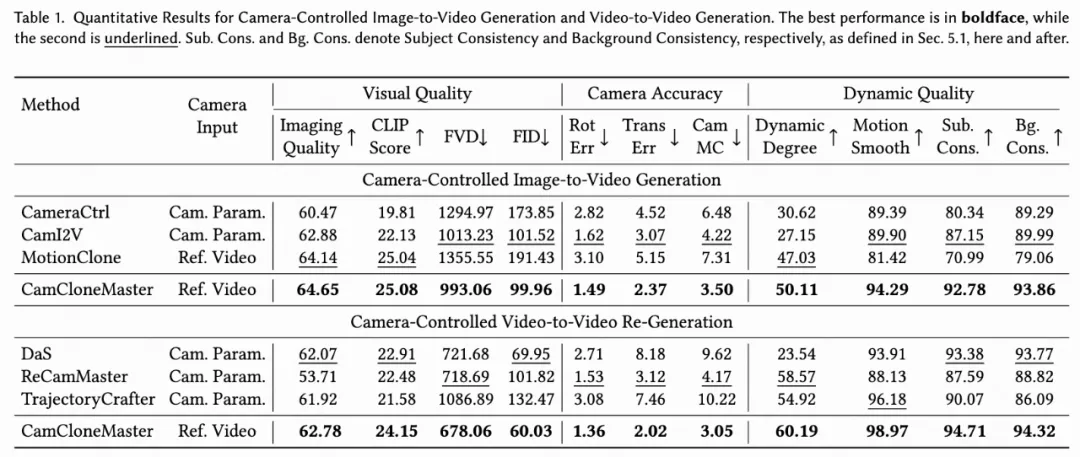
无论是在相机运动的准确性(更低的旋转和平移误差),还是在生成视频的视觉质量(更低的 FVD/FID)和时序连贯性上,CamCloneMaster 都展现出了卓越的性能。
CamCloneMaster 通过一种直观、高效的参考式控制方法,极大地简化了 AI 视频生成中的相机运动控制。其统一的 I2V 和 V2V 框架,以及优越的性能表现,验证了基于参考视频的运镜控制这一思路的巨大潜力。同时,开源的大规模数据集也将为社区的相关研究提供强有力的支持,有望推动 AIGC 视频创作进入一个运镜更自由、表达更丰富的新阶段。
文章来自于“机器之心”,作者“罗亚文”。


