# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当AI开始「自己学会学习」,人类的角色正在被重写。DeepMind最新研究DiscoRL,让智能体在多环境交互中自主发现强化学习规则——无需人类设计算法。它在Atari基准中击败MuZero,在从未见过的游戏中依旧稳定高效。
人工智能(AI)的主要目标之一,是设计出能够像人类一样在复杂环境中自主预测、行动、最终实现目标的智能体(Agent)。智能体的训练离不开强化学习(RL),相关研究也已经持续了几十年,但让智能体自主开发高效的RL算法的目标始终难以实现。
针对这一痛点,Google DeepMind团队提出了一种通过多代智能体在不同环境中的交互经验来自主发现RL规则的方法。
在大型实验中,DiscoRL不仅在Atari基准测试中超越所有现有规则,更在未曾接触过的挑战性基准测试中超越人工设计,击败了多项主流RL算法。相关研究论文已发表在权威科学期刊Nature上。

论文链接:https://www.nature.com/articles/s41586-025-09761-x
这表明,未来用于构建高级AI的RL算法,可能不再需要人工设计,而是能够由智能体自身的经验自动发现。
据论文描述,他们的发现方法涉及两种优化:智能体优化与元优化。
智能体参数通过更新其策略和预测来优化,使其趋向于RL规则生成的目标。同时,通过更新RL规则的目标来优化其元参数,从而最大化智能体的累积奖励。
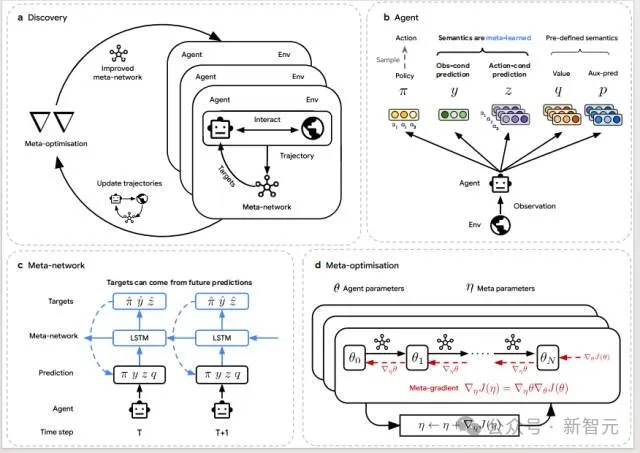
智能体自主发现RL算法的全过程:(a) 发现过程:多个智能体在不同环境中并行交互与训练,遵循由元网络定义的学习规则;元网络在此过程中不断优化,以提升整体表现;(b) 智能体结构:每个智能体输出策略(π)、观测预测(y)、动作预测(z)、动作价值(q)与辅助策略预测(p),其中 y 与 z 的语义由元网络确定;(c) 元网络结构:元网络接收智能体的输出轨迹及环境奖励与终止信号,生成针对当前与未来时刻的目标预测;智能体据此最小化预测误差进行更新;(d) 元优化过程:通过对智能体更新过程的反向传播计算元梯度,优化元参数,以最大化智能体在环境中的累计回报。
在智能体优化方面,研究团队使用Kullback–Leibler散度衡量两者之间的差距,以确保训练过程的稳定性与普适性。智能体会输出策略、观测预测和动作预测三类结果,元网络为其生成相应的学习目标。智能体再根据这些目标更新自身,从而逐步改进策略。同时,模型还引入了一个辅助损失,用于优化预定义的动作价值与策略预测,使学习过程更稳定、更高效。
在元优化方面,研究团队让多个智能体在不同环境中独立学习,元网络则根据它们的整体表现计算元梯度,并调整自身参数。智能体的参数会定期重置,使学习规则能在有限时间内迅速提升表现。元梯度的计算结合了智能体的更新过程与标准强化学习目标的优化,具体由反向传播与优势行动者-评论家(A2C)算法完成,并配合一个专用于元学习阶段的价值函数进行评估。
为验证DiscoRL,团队评估时采用四分位数平均值(IQM)作为综合性能指标,该指标基于多任务基准测试的标准化分数,已被证实具有统计学可靠性。
Atari基准测试是强化学习领域最具代表性的评估标准之一。为验证算法自动发现的能力,团队基于57款Atari游戏元训练出Disco57规则,并在相同游戏中评估。
评估时使用与MuZero相当规模的网络架构,结果显示,Disco57的IQM达13.86,在Atari基准上超越了包括MuZero、Dreamer在内的所有现有强化学习规则,并且在实际运行效率(wall-clock efficiency)上显著优于最先进的MuZero。
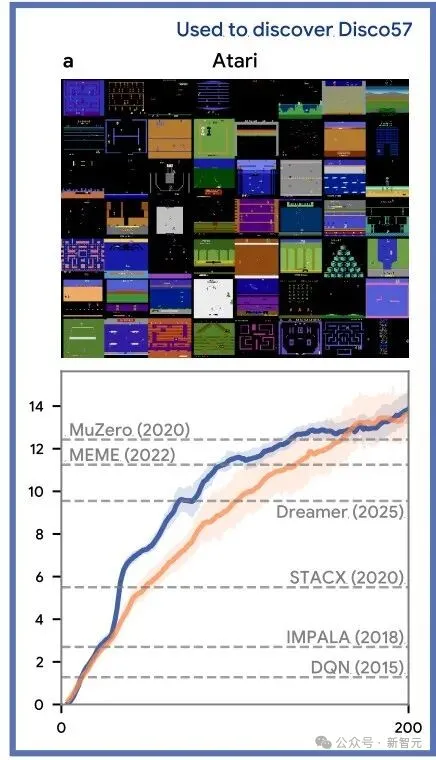
Disco57在Atari实验中的评估结果。横轴表示环境交互步数(以百万为单位),纵轴表示在基准测试中IQM得分。
研究团队进一步评估了Disco57的通用性,在多个它从未见过的独立基准测试上进行测试。在16个ProcGen二维游戏上,Disco57超越了包括MuZero和PPO在内的所有已发表方法;在Crafter基准测试中也表现出竞争力;在NetHack NeurIPS 2021挑战赛中获得第三名,且未使用任何领域特定知识。对比在相同设置下训练的IMPALA智能体,Disco57明显更高效。此外,它在网络规模、重放比例和超参数调整等多种设置下也表现鲁棒。
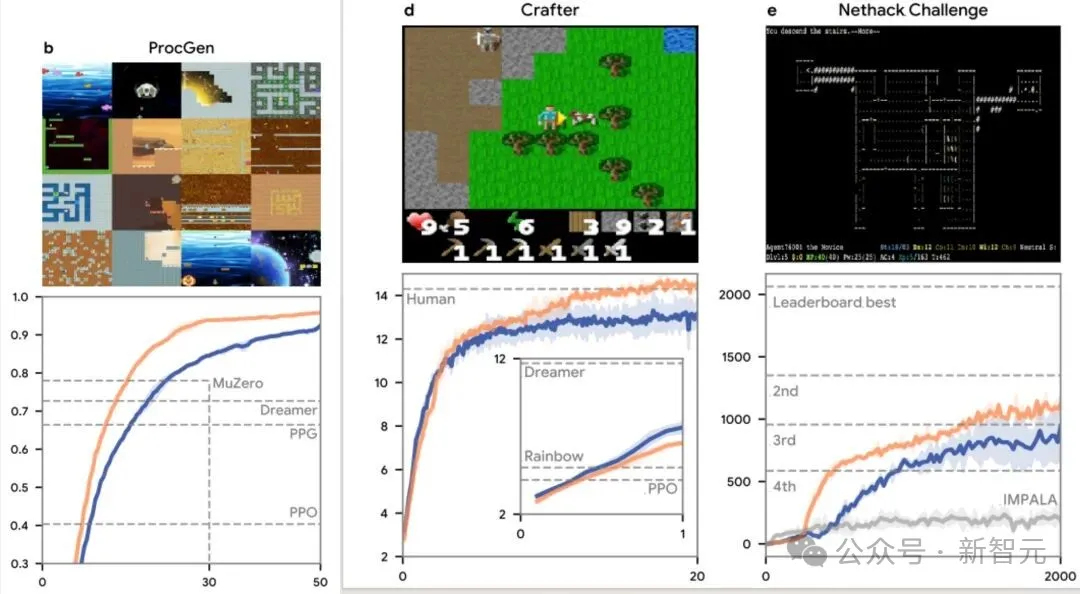
Disco57在ProcGen、Crafter、 NetHack NeurIPS中的评估结果。
研究团队基于Atari、ProcGen 和DMLab-30三个基准,共103个环境,发现了另一种RL规则Disco103。
Disco103在Atari基准上的表现与Disco57相当,尤其是在Crafter 、基准上达到了人类水平的表现,并在Sokoban上接近了MuZero的最先进性能。
这些结果表明:用于发现的环境越复杂、越多样,所发现的强化学习规则就越强大、越具泛化能力,即使是在训练过程中从未见过的环境中也能保持出色表现。
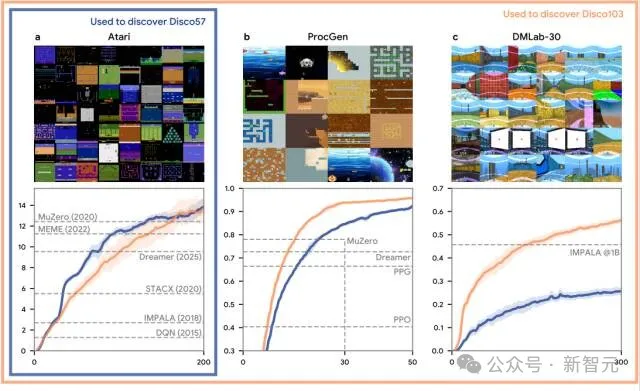
Disco103与Disco57在相同测试中的对比结果。蓝线(Disco57)表示在Atari基准上发现的规则,橙线(Disco103)表示在Atari、ProcGen和DMLab-30基准上共同发现的规则。
研究团队对多个Disco57的版本进行了评估。最优表现是在每个Atari游戏约6亿步内被发现,相当于在57个Atari游戏上进行3轮实验,这相比传统的人工设计RL规则要高效得多——后者往往需要更多实验次数,以及大量研究人员的时间投入。
此外,随着用于实验的Atari游戏数量增加,DiscoRL在未见过的ProcGen基准上的表现也随之提升,这表明所发现的RL规则能够随着参与实验的环境数量与多样性的增加而得到扩展。换句话说,所发现RL的性能取决于数据(即环境)与计算量。
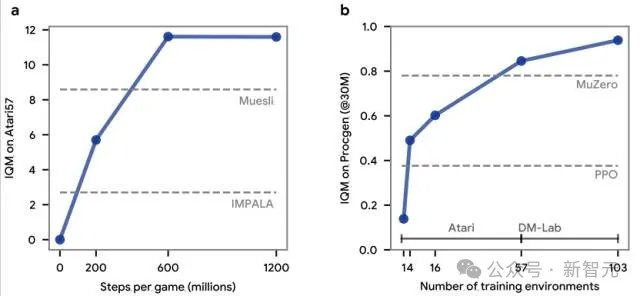
DiscoRL最佳规则在每款游戏约6亿步内被发现;随着用于发现的训练环境数量的增加,DiscoRL在未见过的ProcGen基准测试上的性能也变得更强。
研究团队表示,未来高级AI的RL算法设计,可能将由能高效扩展数据与计算能力的机器主导,不再需要人类设计。
这一发现或许令人振奋但又引发担忧,一方面它带来了学术领域的新潜力,另一方面,当前社会并未做好迎接这项技术的准备。
参考资料:
https://www.nature.com/articles/s41586-025-09761-x
DeepMind再登Nature:AI Agent造出了最强RL算法!
文章来自于“新智元”,作者“学术头条”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
