# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当你被扔进一片数据的汪洋,老板却期待你一眼看穿本质——
你是否也曾幻想,有一位不知疲倦、全知全能的 AI 数据专家,能替你搞定从数据管理、准备,到分析的一切工作?
大语言模型的爆发,让这一幻想前所未有地逼近现实。「数据智能体」应运而生,被寄予厚望,被认为有望彻底改变人与数据的交互方式。
然而,当无数团队宣称自己开发了「数据智能体」时,一个令人困惑的现实浮出水面:你手中的那个「数据智能体」,到底是一个简单的问答助手,还是一个能真正自主治理数据湖、主动发现并解决问题的数据专家?
概念的笼统,正成为领域发展的第一块绊脚石。
为此,由香港科技大学(广州)、清华大学、华为、上海交通大学、中国人民大学、MetaGPT等顶尖机构组成的联合团队,发布了系统性综述论文,并登上 Huggingface 热榜前三,首次为「数据智能体」建立了清晰的 L0-L5 六级自主性分级标准。
论文链接:https://arxiv.org/abs/2510.23587
最新论文和项目资源合集:https://github.com/HKUSTDial/awesome-data-agents

该论文已经放到了特工宇宙 ima 知识库中,可以在线查看/免费下载/AI 问答。
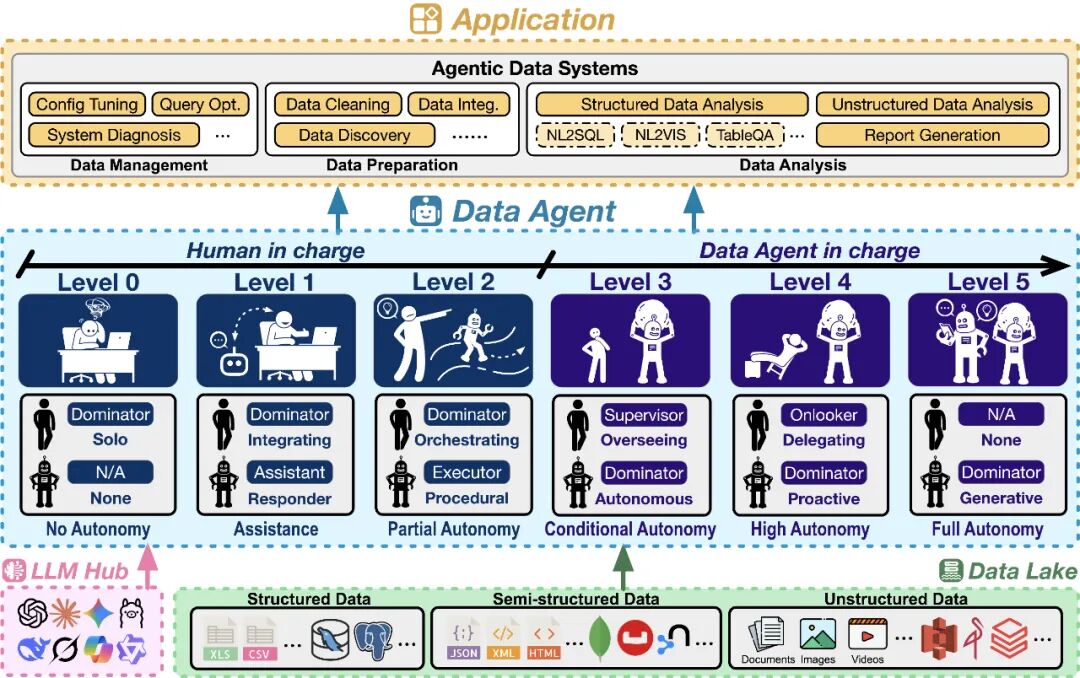
数据智能体是能够编排「数据 + AI」系统,自主完成广泛数据任务(如管理、准备、分析)的智能架构。与旨在解决通用问题的 LLM 通用智能体相比,数据智能体为征服复杂数据挑战而生:
1. 任务目标不同:不只生成文本或图像,而是输出数据洞察、清洗结果、可视化报告、系统配置等数据产物;
2. 环境复杂度高:面对的是庞大、动态、异构的数据湖,数据智能体无从获取数据环境中的全部信息,需主动探索、采样、交互,而非仅仅处理自包含、静态的输入;
3. 错误代价链式传导:前期一个数据清洗或集成错误,可能导致整个下游分析失效。
正是这种独特性与高代价风险,使得为数据智能体建立清晰的能力标准至关重要。然而在今天,当你听到「数据智能体」时,它可能被笼统地用于指代能力天差地别的系统:
一边是雄心勃勃的自主系统,致力于实现主动探索数据湖、调用工具、自主编排复杂流程,以最小人力干预解决多样化、综合性的数据任务;另一边只是基础的问答式任务助手,仅能响应原子性查询,无法感知数据环境,也无法自我优化。
这种「同名不同命」的乱象,带来三重现实困境:
1. 期望的落空:用户难以判断系统能力边界,可能盲目信任错误结果,也可能因失望而弃用。
2. 责任的真空:一旦发生数据泄漏或误导决策,责任在用户、开发者还是模型?谁也说不清。
3. 创新的泥沼:缺乏统一标尺,劣币驱逐良币,行业陷入空泛的概念竞争。
为消除当前数据智能体面临的术语模糊困境,团队借鉴已在全球汽车工业形成共识的 SAE J3016 自动驾驶分级标准,首次系统性地提出了数据智能体的六级自主性水平框架(L0-L5),清晰界定从「人类全权负责」到「机器完全自主」的每一步。
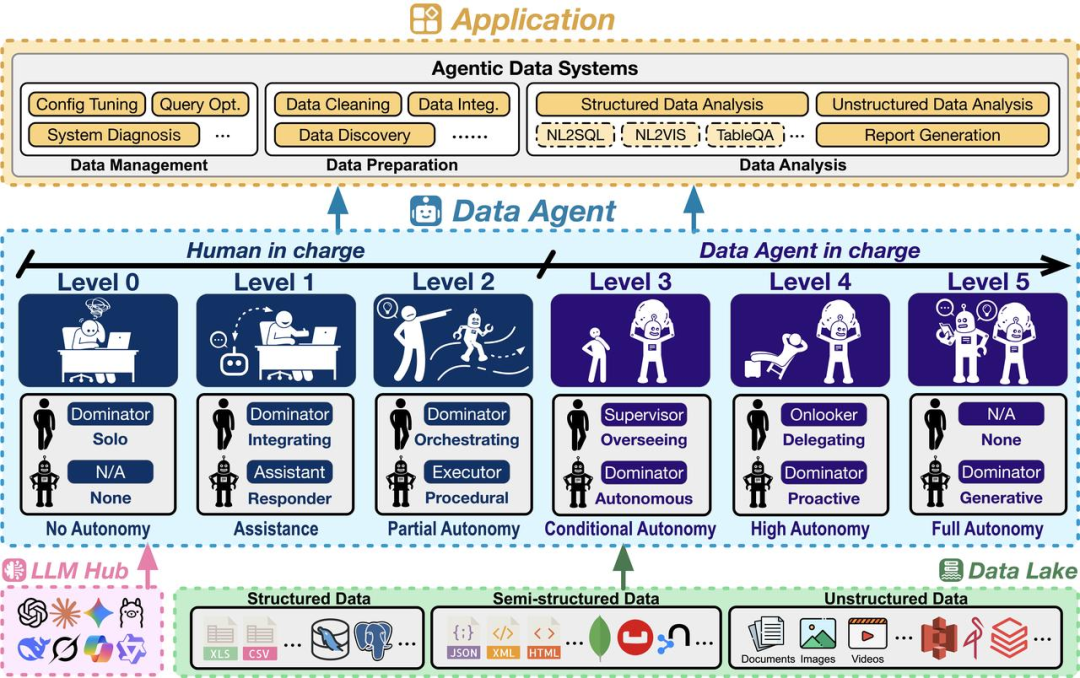
数据智能体框架
L0(无自主性): 所有工作完全由人类手动完成。
L1(辅助): 数据智能体作为问答机,能根据提问生成代码片段或分析,但无法动态执行或与环境交互,需要人类手动整合验证。
L2(部分自主): 数据智能体获得感知并交互数据环境(如 DBMS、代码解释器、API)的能力,在人类设计好的流程中自主执行特定任务。
L3(条件自主): 数据智能体成为任务的「主导者」并开始承担数据相关任务的主要责任,不再局限于人类与定义的流程和特定的任务,能自主编排端到端的流程来解决多样化、综合性的数据相关任务,人类角色退居为「监督员」。
L4(高度自主): 数据智能体无需人类监督和任务指令,即持续监控数据环境,主动发现有价值的问题并可靠的解决。人类变为「旁观者」,只负责接收最终洞察。
L5(完全自主): 终极愿景,数据智能体成为真正的数据科学家,不仅能应用现有方法,更能自主创造新算法、新范式,实现真正的创新,推动数据管理、准备和分析的边界。
我们并未停留在概念分层,而是以此为透镜,对现有研究进行了一次全景式的回顾、定位与审视。
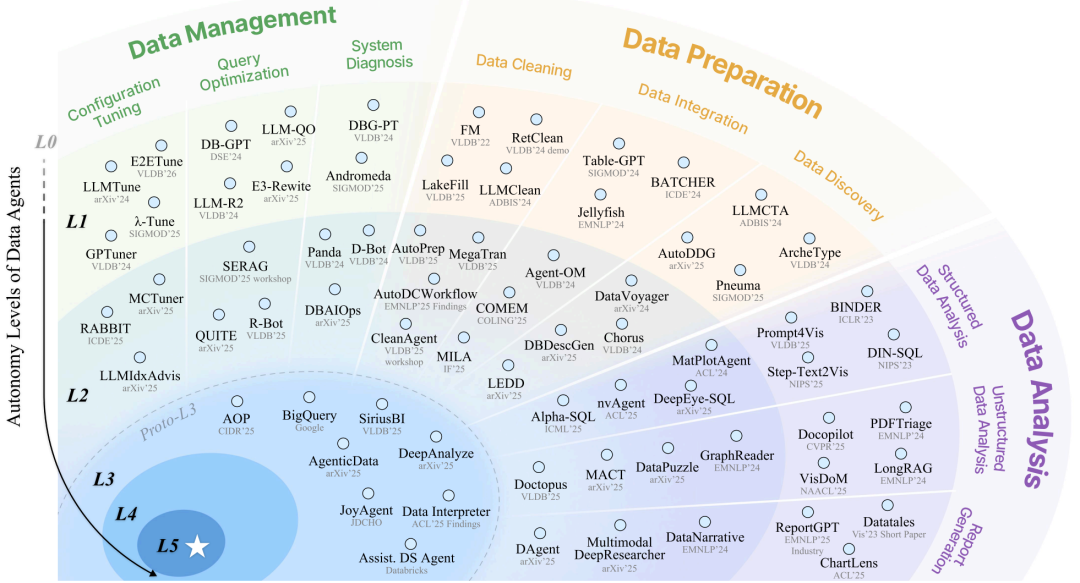
代表性数据智能体在各层级与任务中的分布图
1. L0/L1:从手动到问答助手的初期探索
总结了在初期大语言模型热潮中,前期在配置调优、数据清洗、NL2SQL 等任务上的先期探索和数据相关任务中问答式的辅助能力,并点明其静态、无环境交互的根本局限。
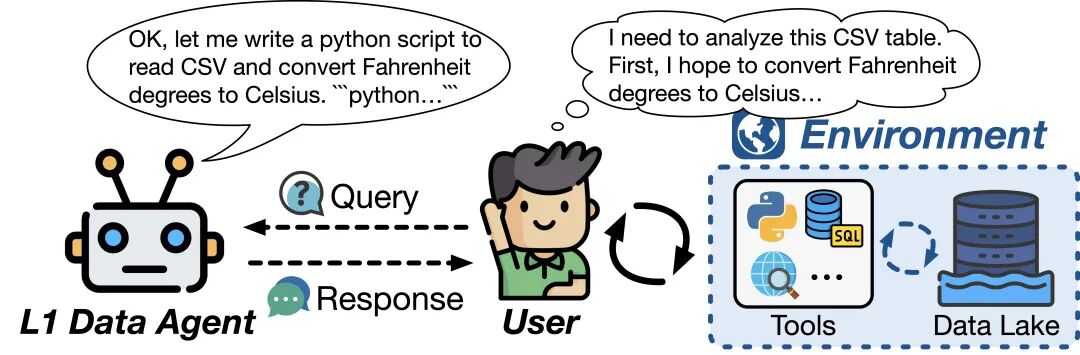
L1 数据智能体示意图
2. L2:当前主流研究的能力天花板
详细分析了这些系统如何通过环境互动与执行反馈来优化特定的任务(如数据库探索、代码执行反馈、工具调用等),但也分析了其能力天花板 —— 这一层级的数据智能体仍被困在执行层,他们的成功依赖于人类精心设计的流程,而这些数据智能体本身缺乏自主编排的能力,更难以泛化到真实世界中多样、复杂的数据任务。
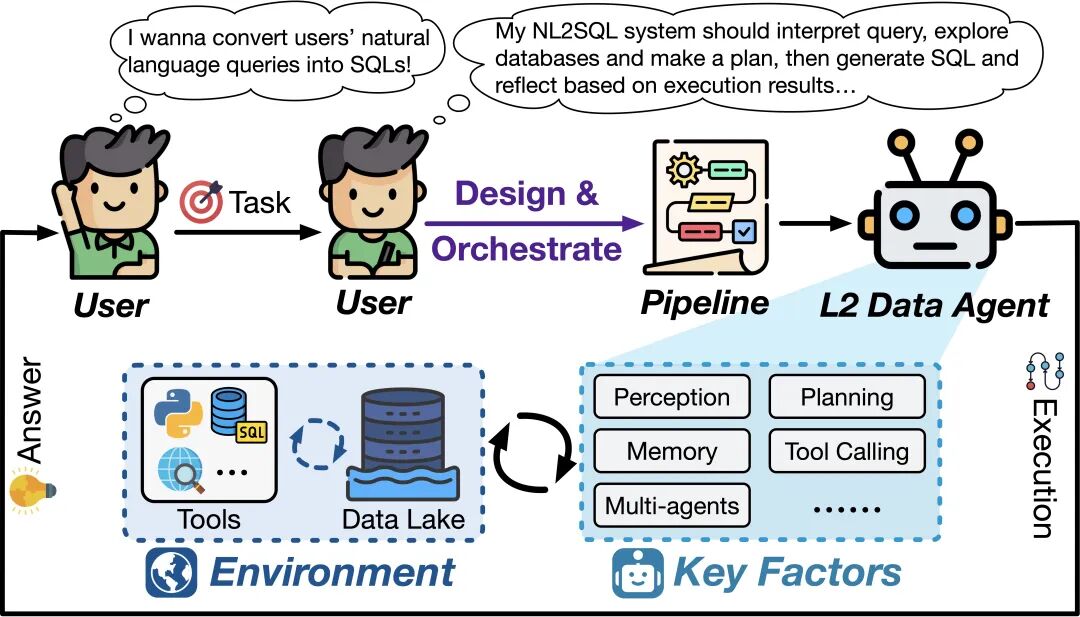
L2 数据智能体示意图
L3:最前沿的准 L3 探索与开放挑战
聚焦于学术界的 AgenticData、iDataLake 与工业界的 Snowflake Cortex、JoyAgent 等探索性系统。这些先锋系统在自主编排工作流、拓宽任务范围上取得进展,但它们仍受限于预定义的算子和工具、不完整的数据生命周期覆盖等问题,距离真正的 L3 尚有差距。
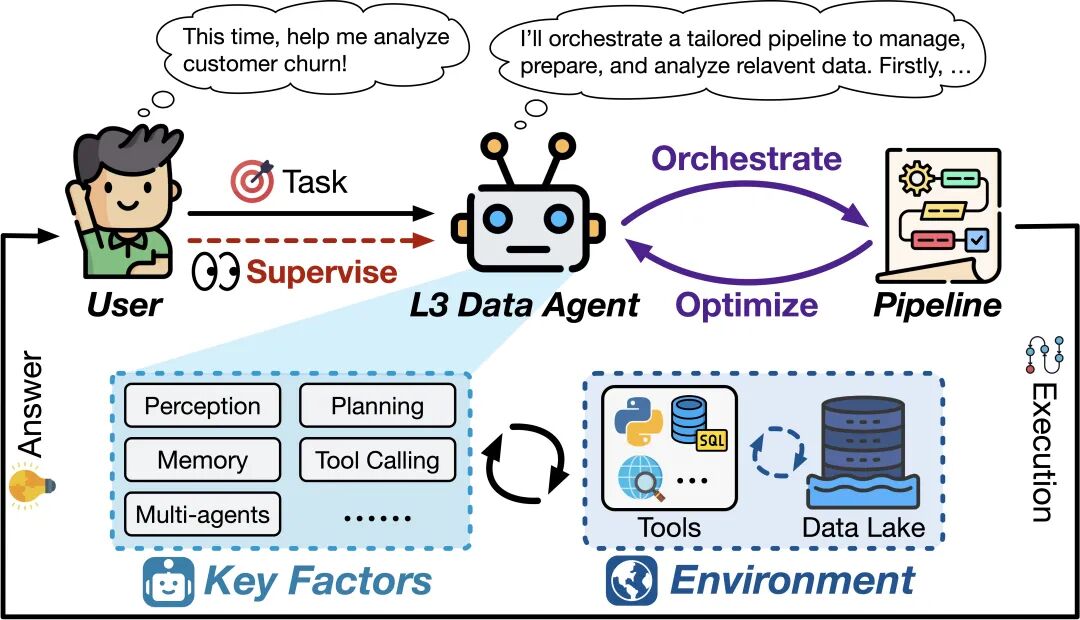
L3 数据智能体示意图
我们为迈向真正的 L3 及更高等级的数据智能体指明了必须攻克的核心挑战:
1. 受限的工作流编排:如何超越预定义的算子和工具池?
2. 不完整的数据生命周期覆盖:如何让数据智能体精通从底层系统管理到顶层分析的全链路?
3. 高级推理能力缺失:如何让数据智能体具备整体反思,长远规划和权衡能力(比如权衡前期数据清洗的开销和潜在的分析阶段的收益)?
4. 动态环境适应性不足:如何让数据智能体在数据、需求不断变化的环境中动态适应、自我进化?
在论文的最后,我们描绘了数据智能体未来的演进图景:从 L3 到未来 L4 的主动型、可信任的自治系统,最终到 L5 能够推动数据科学范式进步的“生成式数据科学家”。
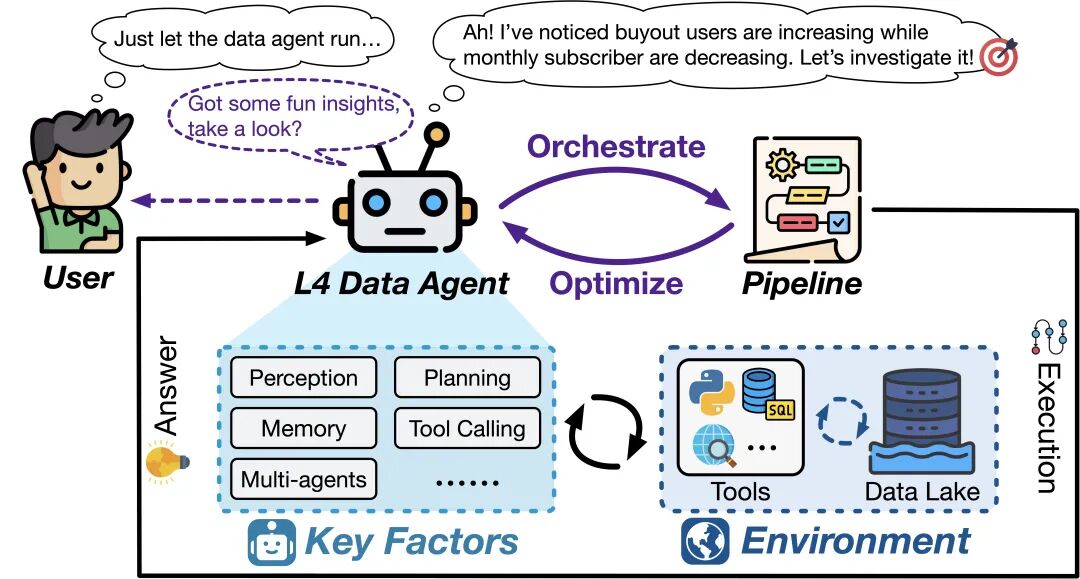
L4 数据智能体示意图
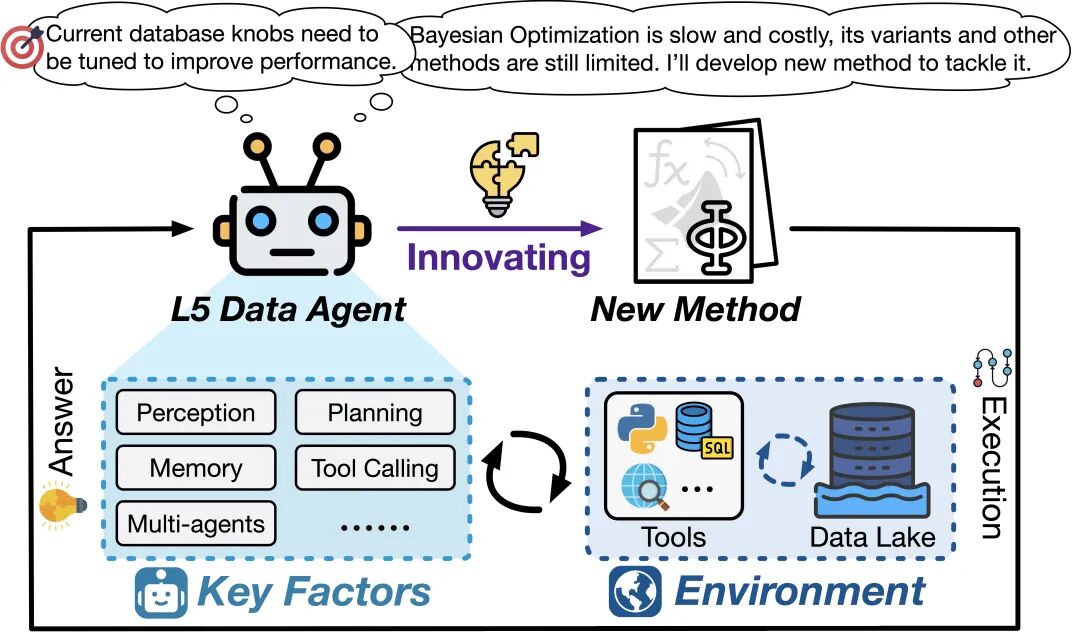
L5 数据智能体示意图
对开发者与研究者而言,此标准助力更精准地定位系统、规划技术路线。
对用户而言,它有助于建立合理预期,明确何时监督、何时放手。
对行业与监管方而言,它为厘清能力边界与责任归属提供了思考基础。
清晰的定义是数据智能体从「热词」走向「成熟」的第一步,这篇综述正是推动数据智能体从「营销概念」走向「可靠工程」的一次坚实努力。
文章来自于“特工宇宙”,作者 “宇宙编辑部”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
