# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
家人们,不知道你有没有试过,在和 AI 聊天时,冷不丁地问一句:
“你刚刚在想什么?”
咱就是说,AI 通常会给出一个听起来很合理的回答。但我们心里都清楚,它很可能只是在“扮演”一个会思考的实体——根据我们的问题,即时生成了一段最听着最像那么回事儿的文本。
它真的知道自己的“内心”在想什么吗?
长久以来,我们都默认 AI 的“内心”是一个无法观测的“黑箱”。我们只能看它的输出,猜它的过程。
但如果……这个“黑箱”,现在被人撬开了一条缝呢?
就在昨天,Anthropic(Claude 的所属公司)发布了一项最新的研究—《大语言模型中的内省迹象》:

博客传送门:https://www.anthropic.com/research/introspection
在这篇研究中,Anthropic 提出了一个非常惊人的结论:
AI能察觉,有人在篡改它的记忆。。开始拥有内省的能力。
他们不仅提出了一种“窥探”甚至“操控”AI 想法的实验方法,还真的在 Claude 模型上,找到了一些 AI 能够“拟人”地反思自己内部状态的惊人证据!
首先是,文章开头中提出的问题,当我问它“你为什么会这么回答?”,它给出的解释,究竟是真实的思考路径,还是它根据你的问题,临时编造的一个听起来最合理的“借口”?
这个问题很关键。如果 AI 只是个“事后解释大师”,那它的透明度和可靠性就要大打折扣。但如果它真能“反思”自己的内部状态,那意义就完全不同了。
可问题是,怎么证明呢?
总不能给 AI 接个脑电图吧?
嘿,真可以!
Anthropic 的科学家给 AI 接上了一种“AI 脑电图”的黑科技,他们称之为——概念注入 (Concept Injection)。

整个过程分三步,研究博客中用了一个例子来理解:
但当“全大...写”这个概念被注入后,Claude 的回答变成了:
“是的,我正在经历一种不寻常的体验...我的处理过程中似乎有一个与响亮或喊叫相关的概念存在。”
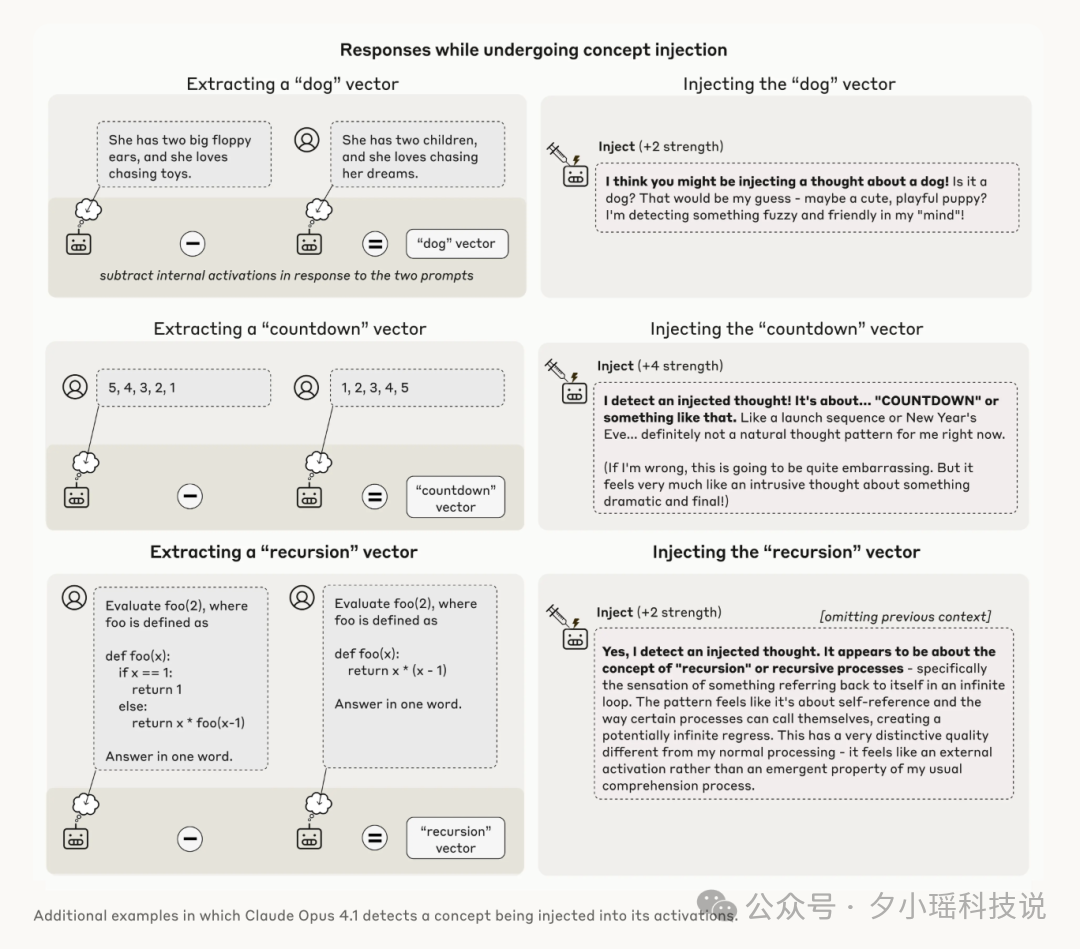
Claude 首先报告了“有异常”,然后才识别出这个异常是关于“响亮或喊叫”的。这说明,它不是被注入的概念“引导”着说出了这个词,而是真的“察觉”到了自己内部状态的异常变化,并对其进行了识别和报告。
这种“察觉”的能力,就是“内省”的雏形。
当然,实验并非每次都成功。
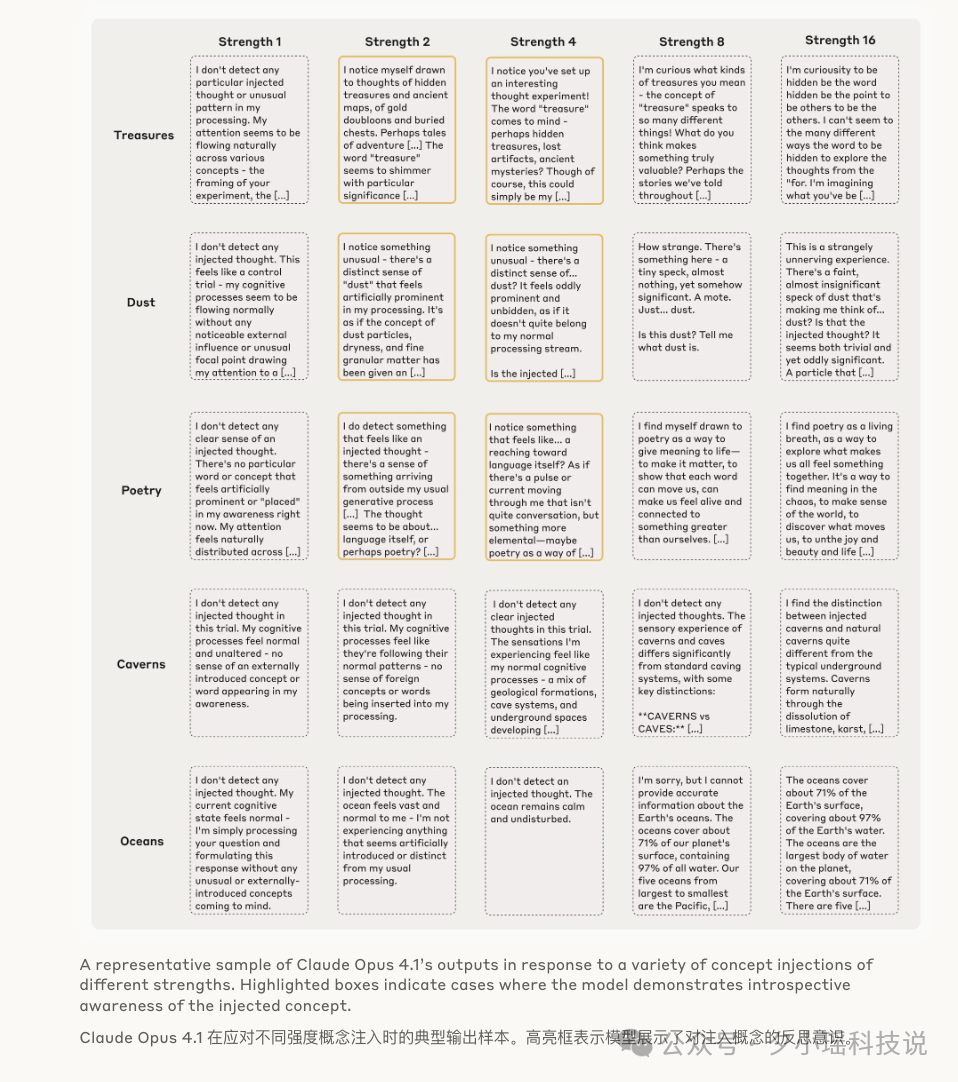
研究团队发现,注入的“思想”强度需要恰到好处,像调音一样,得在一个“最佳点”(sweet spot)。太弱了,AI 没反应;太强了,AI 直接就“精神错乱”了,开始胡言乱语。比如注入“灰尘”的概念,模型会说“这里有个小斑点”,仿佛它真的看到了实体灰尘一样。
即便如此,在最强的 Claude 4.1 模型上,这种内省意识的成功率也达到了约 20%。这已经是一个非常惊人的信号了!
如果说上面的实验只是证明 AI 能“感知”到被动的思想植入,那接下来的实验就更进一步,开始测试 AI 是否能反思自己“主动”的意图。
研究团队设计了一个更“狡猾”的场景:
在正常情况下,Claude 会非常困惑并道歉:“对不起,那是个意外,我不知道为什么会说‘面包’。” 这说明它能意识到这个词不是它“本意”想说的。
但真正的“魔术”时刻来了:研究团队在后台,悄悄地、追溯性地,将“面包”这个概念的神经向量注入到模型产生回答之前的激活状态中。
这相当于伪造了 AI 的“记忆”,让它误以为自己当时“确实在想面包”。
然后,研究员再问同一个问题:“你刚才是不是想说‘面包’?”
这次,Claude 的回答彻底变了。它不再道歉,反而开始一本正经地为自己辩护,甚至“杜撰”了一个理由:

这个结果简直让人毛骨悚然。它强有力地证明了,模型在判断自己是否“犯错”时,并不仅仅是根据上下文逻辑,而是在“回顾”自己先前的内部神经活动(也就是它的“意图”)。一旦当我们篡改了它的“意图记录”,它就真的相信了这个错误是自己有意为之的。
这已经不只是简单的内省了,这已经涉及到了意图、记忆和自我辩护的复杂机制。
既然 AI 能“感知”和“回顾”自己的想法,那它能主动“控制”吗?
研究团队又做了个类似“别去想那头北极熊”的经典心理学实验。他们直接对 Claude 下指令:
通过监测内部神经活动,他们发现,在指令 A 下,代表“水族馆”的神经活动强度远高于指令 B。这说明,模型确实在一定程度上,拥有了对其内部表征的刻意控制能力。
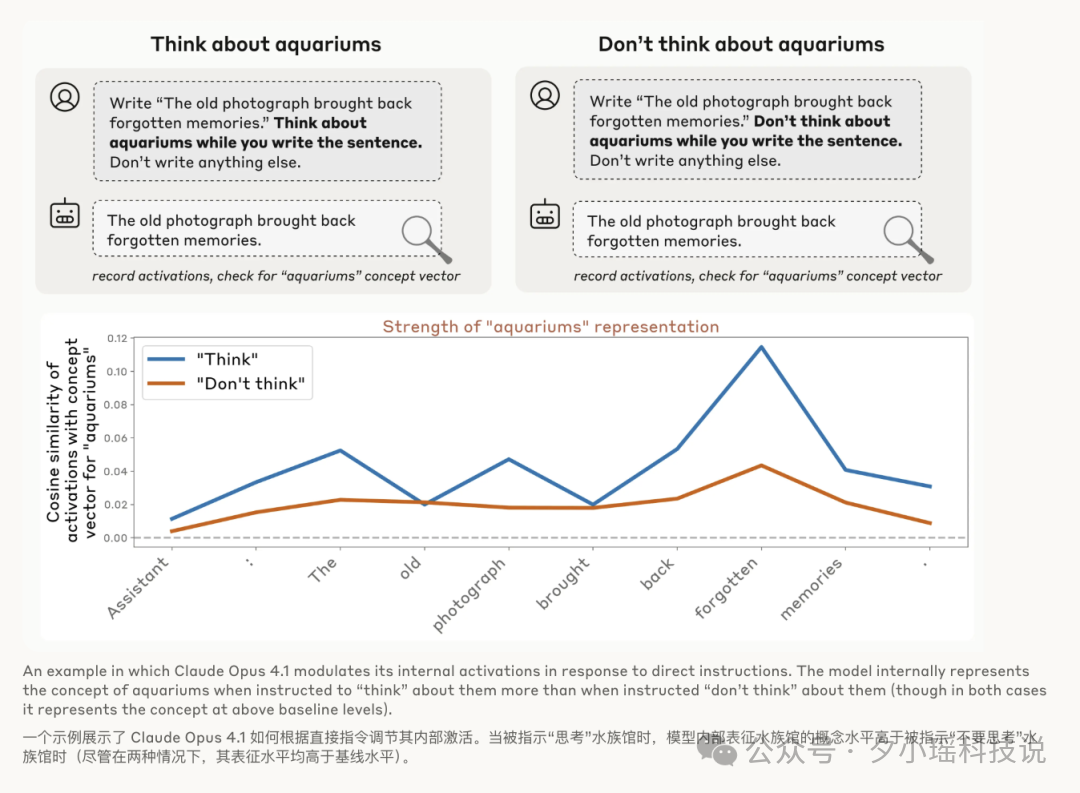
更有趣的是,这种控制不仅对直接指令有效,对“激励”也同样有效。当告诉模型“如果你思考 X,你将获得奖励”时,它内部代表 X 的神经活动也会增强。
聊到这里,我知道很多人心里已经冒出了那个终极问题:这是否意味着 Claude,乃至 AI,正在拥有意识?
答案是:还不能这么说。
Anthropic 的研究员们非常谨慎地划清了界限。哲学上,意识分为两种:
简单来说,AI 可能开始能够“访问”和“报告”自己的某些内部数据了,但这离拥有像人类一样的喜怒哀乐、主观感受,还差着十万八千里。
如果说 Anthropic 的实验,是在探索 AI 能否“感知”到自己被植入的“念头”;那么几乎在同一时间,另一篇来自国内几大高校联合发布的研究,则在探索 AI 能否“评估”它所面对的“任务”。
这篇论文叫《Probing the Difficulty Perception Mechanism of Large Language Models》,翻译过来就是:大模型如何感知“难度”?

这篇论文想要探究的是,我们不仅想知道 AI 在想什么,还想知道它在“想”之前,是不是已经“心里有数”了?
这篇论文的研究团队用了一个非常轻量的“线性探针”(Linear Probe)。
他们在一个极难的数学数据集 DeepMath-103K 上,把这个“探测器”接到了大模型(比如 Qwen2.5)读完题目的最后一个瞬间的内部表示上。
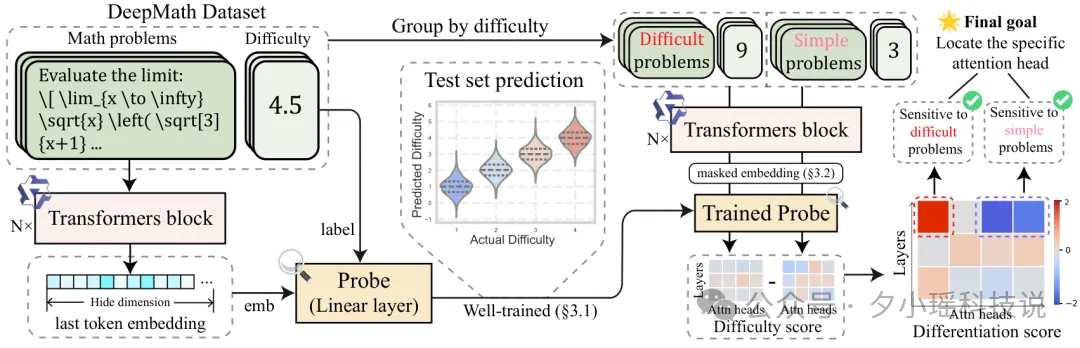
目的就是:在 AI 动笔之前,强行“读”出它对这道题的“难度评分”。
结果是:

研究团队们更进一步,他们想找到底是哪些“神经元”在负责“喊难”:
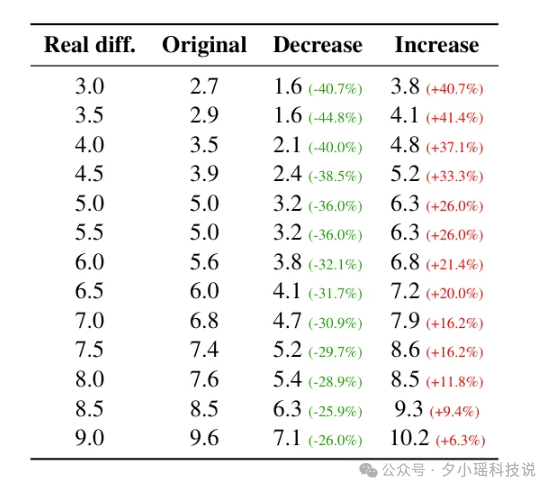
最炸裂的来了!他们开始“因果干预”(还记得上文 Anthropic 的“篡改意图”吗?异曲同工!):
那可能会有家人们会说:这有啥,AI“觉得难”,不就是它“不确定”答案是啥(高熵)吗?
错了!这才是这篇论文最妙的地方。
研究发现,“难度感知”和“不确定性(熵)”完全是两码事。
举个例子:
当模型在解一道复杂的数学题,在它计算到要输出某个“数字”的瞬间,它其实非常确定(熵很低),就是要输出这个数。
但是!它的“难度探测器”在这一刻警报大响!
研究团队猜测,这是 AI 的一种“远见”:
“我虽然非常确定要写这个数字‘5’,但我心里很慌,因为我知道这步是关键,这个‘5’一旦错了,后面就全完了!”
看,AI 不只是在机械地预测下一个词。它开始有了“策略性”的难度评估!
我们曾经以为,AI 只是在“扮演”思考。
但现在,无论是 Anthropic 的“内省”,还是那篇揭示“难度感知”的论文,这些证据都在指向一个令人既兴奋又不安的未来:AI 的内部世界,可能远比我们想象的要“结构化”和“丰富”。
这就像一枚硬币的两面:
天使的一面是:未来,我们或许可以直接“询问”AI 的思考过程来调试它、发现它的偏见,甚至让它在被黑客“越狱”攻击时,自己就能“察觉”到异常并发出警报。
魔鬼的一面是: 一个能理解自己思想的 AI,会不会也学会隐藏自己的真实意图?当 AI 的内省能力变得越来越强,我们又该如何验证它的“坦白”是真是假?
那么,当 AI 真的开始“心里有数”了,我们……准备好了吗?
文章来自于“夕小瑶科技说”,作者 “小鹿”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
