# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
程爽,上海人工智能实验室和浙江大学联培博士生一年级;卞一涵,美国马里兰大学硕士生二年级,上海人工智能实验室实习生;刘大卫,上海人工智能实验室和上海交通大学联培博士生一年级;齐弼卿,上海人工智能实验室研究员(指导老师)
大模型推理速度慢、成本高,已成为限制其广泛应用的核心瓶颈。其根源在于自回归(AR)模型「逐字生成」的串行模式。
近日,上海人工智能实验室针对该难题提出全新范式 SDAR (Synergistic Diffusion-AutoRegression)。
该方法通过「训练-推理解耦」的巧妙设计,无缝融合了 AR 模型的高性能与扩散模型的并行推理优势,能以极低成本将任意 AR 模型「改造」为并行解码模型。

实验证明,SDAR 不仅在多个基准上与原版 AR 模型性能持平甚至超越,还能带来数倍的真实推理加速。更令人惊喜的是,SDAR 在复杂的科学推理任务上展现出巨大潜力。在与采用相同配置训练的 AR 基线模型进行公平对比时,SDAR 在 ChemBench 等基准上最高取得了 12.3 个百分点的性能优势。
在科学推理能力上,SDAR 实现了对 AR 基线模型的超越。与使用完全相同配置训练的 AR 版本进行公平对比,SDAR-30B-A3B-Sci 模型在 ChemBench(化学)和 GPQA-diamond(谷歌研究员水平科学问答)两大基准上,得分分别从 60.5 提升至 72.8 和从 61.2 提升至 66.7,取得了 12.3 和 5.5 个百分点的显著优势。这一结果有力地表明,其局部双向注意力机制对于精准理解化学式等结构化知识至关重要。
目前,该团队已全面开源从 1.7B 到 30B 的全系列 SDAR 模型、高效推理引擎及迄今最强的开源扩散类推理模型 SDAR-30B-A3B-Sci。
自 GPT 系列模型问世以来,自回归(Autoregressive, AR)范式便成为主流。它通过「从左到右、逐词预测」的方式生成文本,完美契合了自然语言的顺序结构,这也是 AR 模型效果出众的根本原因。 然而,这种严格的顺序依赖,也带来了两大与生俱来的挑战:
为打破僵局,研究者们将目光投向了潜力巨大的扩散模型(Diffusion Models)。其中的掩码扩散语言模型(MDLM)将整个序列视为一个整体,通过「从模糊到清晰」的迭代去噪方式并行生成,理论上能一举解决 AR 模型的速度瓶颈。
但实践中,MDLM 面临两大难题:
「混合模型」虽然尝试结合二者,块内并行、块间自回归,但其特殊的训练目标函数依赖复杂的注意力掩码,导致训练开销几乎翻倍,令人望而却步。
面对这一困境,上海 AI 实验室的研究团队重新审视问题本质,提出了一个颠覆性的思路:为什么要在同一个阶段解决所有问题?SDAR 范式的核心就是「解耦」(Decoupling):
这个过程,可以理解为:先培养出一位精通单字书法的大家(强大的 AR 模型),然后只用极短时间教会他「连笔挥毫」(块状并行生成)的技巧。其原有的书法功底(模型性能)丝毫未损,但创作速度(推理效率)却得到了质的飞跃。
通过这种「训练-适配」分离的设计,SDAR 完美保留了 AR 模型的全部优点——强大的性能、高效的优化、KV 缓存、可变长度生成等,同时精准地「嫁接」了扩散模型最核心的优势——并行解码带来的推理加速。
为了验证 SDAR 的实际效果,研究团队进行了一系列严谨的实验,旨在回答三个核心问题:SDAR 性能与同级 AR 模型相比如何?并行加速效果如何?改造现有 AR 模型的成本高吗?
关键发现:
性能不妥协:与 AR 基线全面对标
研究人员基于 Qwen3 系列的 1.7B、4B、8B-dense 和 30B-A3B MoE 模型,通过「继续预训练 (CPT) + 指令微调 (SFT)」的两阶段流程,训练出 SDAR-Chat 系列模型,并与采用完全相同流程训练的 AR-Chat 基线进行全面对比。
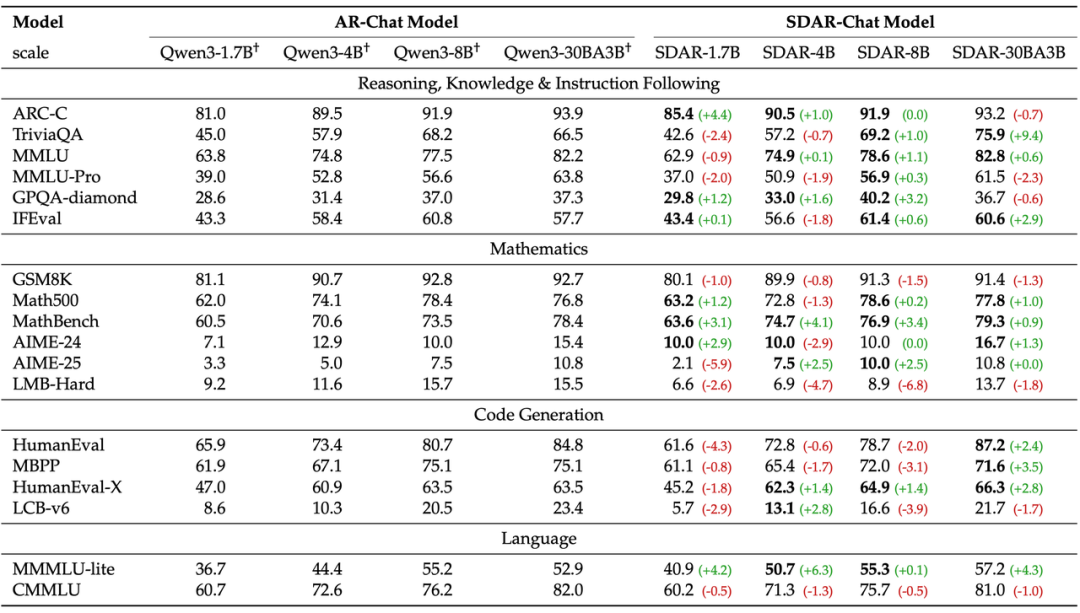
图注:SDAR-Chat 和 AR-Chat 的严格比较
如上表所示,SDAR 在规模化扩展时,性能与 AR 模型同步增长。在 30B 规模下,SDAR-Chat 在 18 个基准中的 11 个上持平或超越了其 AR 版本,证明了该范式的有效性与可扩展性。
成本极低:高效的「即插即用」式适配
与需要 580B token 进行从头训练的 Dream 等工作相比,SDAR 仅用 50B token 的开源数据进行继续预训练,就能达到与 AR 基线相当的性能。这证明了「解耦」思想的正确性:强大的 AR 预训练已为模型打下坚实基础,后续的块状扩散适配仅是一个短暂的「对齐目标」过程。这意味着社区能以极低的成本,将任何开源 AR 模型轻松转换为高效的 SDAR 模型。
加速显著:真实部署中的效率飞跃
该研究通过「有效每步生成 Token 数」(TPF)这一指标来衡量理论加速。TPF 为 1 即为标准 AR 模型。
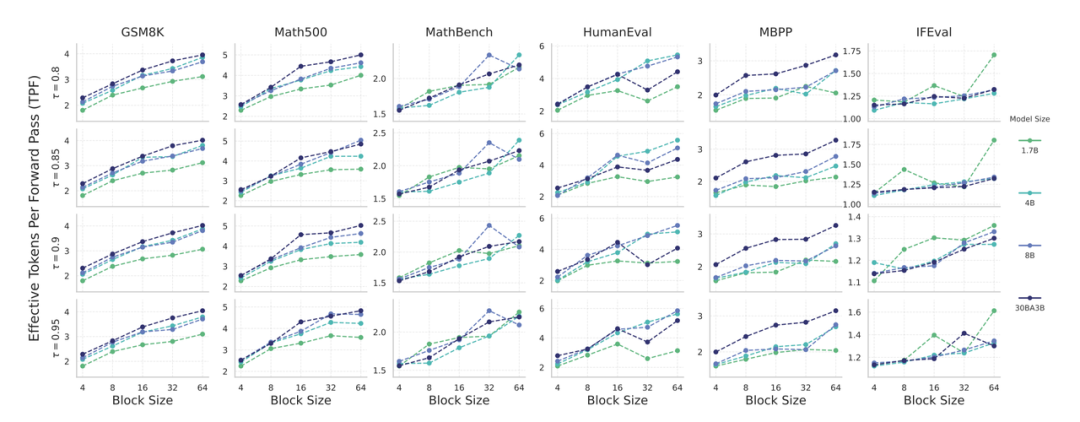
图注:SDAR 理论加速比
上图揭示了 SDAR 的缩放定律:
在工业级推理引擎 LMDeploy 上的实测结果更为直观。在对延迟敏感的小批量场景下,SDAR-8B-chat 在单张 H200 上实现了相较于 AR 版本 2.3 倍的实际加速,峰值吞吐量高达 6599 token/s,为实时交互应用提供了巨大优势。
除了效率提升,一个自然而然的问题是:SDAR 独特的生成机制是否会影响其复杂的推理能力?为此,研究人员基于 Qwen3-30B-A3B,专门打造了一款科学推理模型 SDAR-30B-A3B-Sci,并与严格对齐训练流程的 AR 版本进行对比,结果令人振奋。
关键发现:
结果令人惊喜:
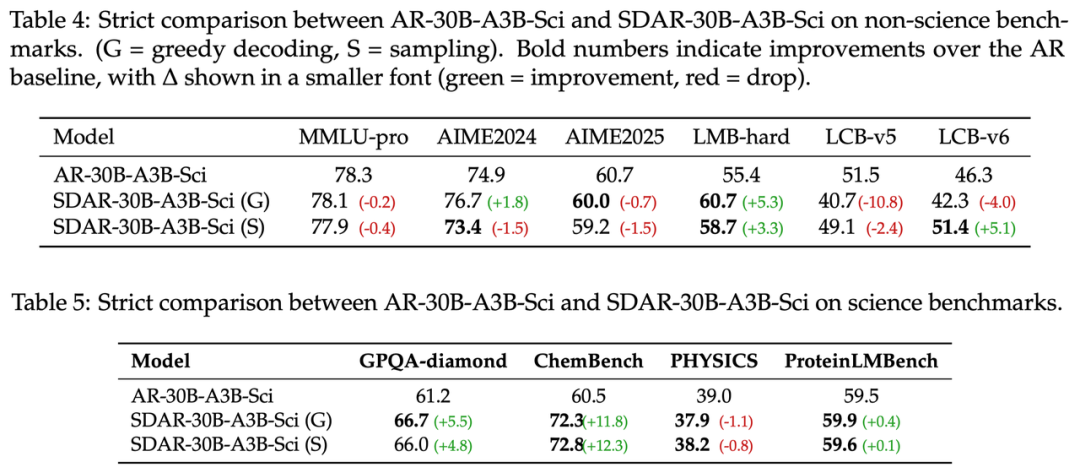
图注:AR-30B-A3B-Sci and SDAR-30B-A3B-Sci 性能比较
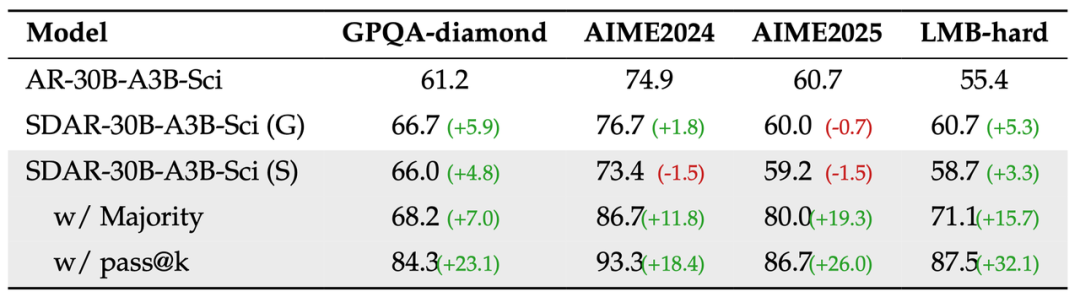
图注:测试时扩展实验
这些结果证明,SDAR 不仅是一个「加速器」,更是一个「增强器」,为解决复杂推理任务提供了一个性能与效率俱佳的新范式。
SDAR 为大模型领域提供了一个强大而灵活的新工具。该研究的核心贡献可归纳为以下几点:
SDAR 的出现,不仅能让现有的大模型「飞」起来,降低应用门槛,也为探索更高性能、更高效的下一代 AI 推理范式打开了一扇新的大门。
文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
