# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
一个研究者一天到底要读多少篇论文才能跟上最新趋势?在 AI 研究成果爆炸的今天,这个数字变得越来越模糊。人的阅读速度,早就跟不上 AI 科研地图扩展的速度了。
于是,一篇来自加州大学圣迭戈分校、Nvidia 等机构的新论文提出了一个大胆的设想 —— 让机器自动读懂整个学科,并告诉研究者下一步该往哪里走。
他们开发的系统 Real Deep Research(RDR),能自动完成高质量的领域综述与趋势追踪:从顶会收集成千上万篇论文,经由提示筛选范围,再将每篇论文压缩成结构化摘要。
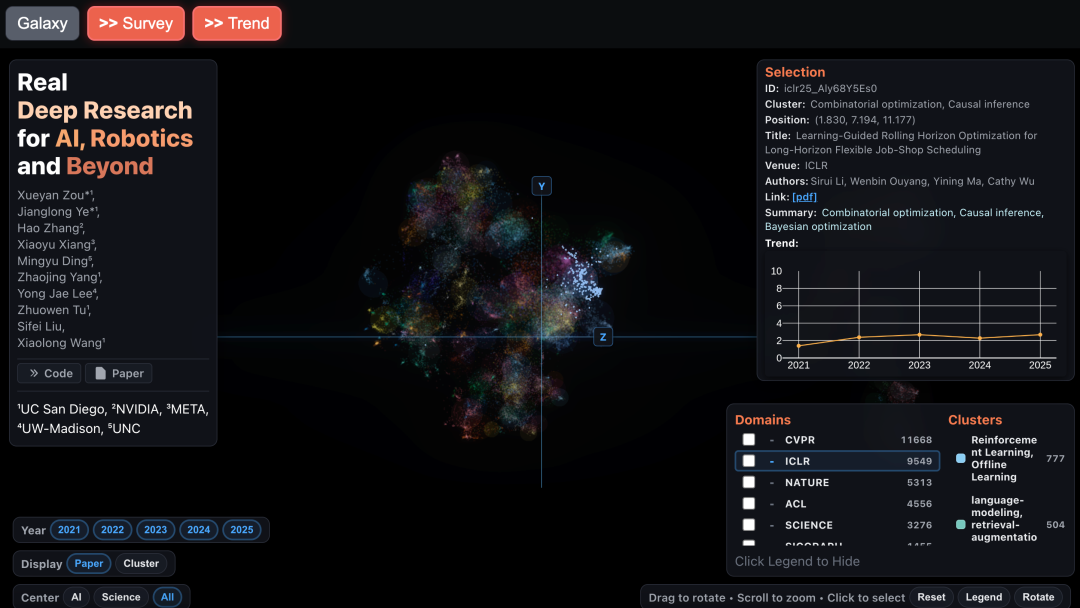
系统链接:https://realdeepresearch.github.io/
对于基础 AI 模型,它会记录数据来源、模型机制、产出形式、学习目标以及训练方法。
对于机器人学,它会记录传感器、身体、关节的输出、动作空间以及环境,这些共同描述了机器人如何在世界中感知、移动和行动。
所有摘要都会被嵌入向量空间,以便相似研究自动聚类。系统随后能够自动生成领域综述,绘制主题趋势随时间演变的图谱,并跨领域建立研究聚类之间的联系。此外,它还支持语义检索,使新进入该领域的研究者能够快速找到高质量的起点论文。
作者表示,这项工作和已有综述及自动化研究流程有所不同。专家撰写的综述足够有深度,也足够准确,但需要付出太多的时间、精力,且难以适应研究的快速发展;而现有的自动化方法往往缺乏领域特定知识和专家见解,限制了其对研究人员的实用性和相关性。他们的工作旨在通过将系统化的自动化与有意义的、基于专家知识的分析相结合,来弥合这一差距。
不过,由于这篇论文不是一篇技术论文,其研究历程非常坎坷。
但论文发布后,他们获得了应有的赞誉。
作者希望这项研究不仅能帮助 AI、机器人研究者追踪最新方向,还能帮助大家了解陌生的研究领域,识别不同领域之间未被充分探索的交集。
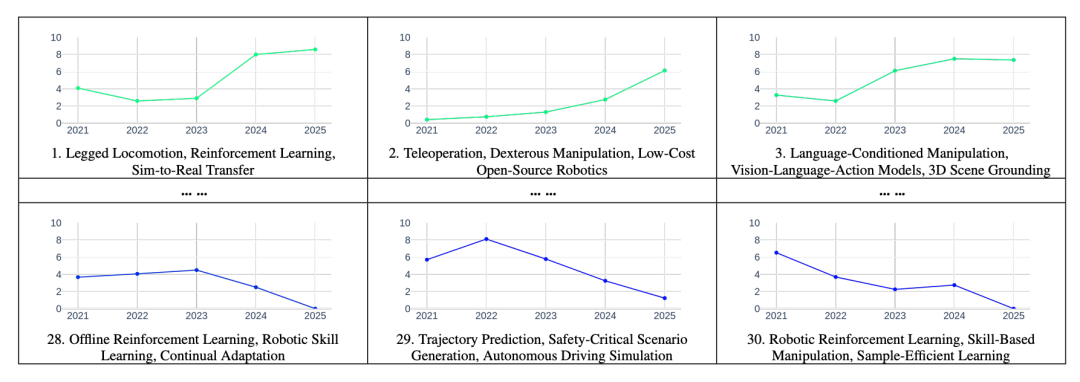
下图 1 展示了单篇论文、聚类的研究主题及其对应的趋势。从中可以明显看到,遥操作、灵巧操作和开源机器人等领域正在成为有前景的方向,而传统的强化学习则显示出下行趋势。作者表示,作为机器人领域的研究人员,他们发现这些趋势洞察与他们的领域知识高度契合,并为识别有影响力的研究机会提供了宝贵的指导。

在论文中,作者详细阐述了他们如何利用专家知识进行 Real Deep Research。如图 2 所示,这个基于嵌入的分析 pipeline 包含四个主要组成部分:数据准备、内容推理、内容投影和嵌入分析。该 pipeline 由一套大型语言模型和多模态模型支持,用于内容提取和推理,且设计为具有通用性,能够在未来自动化分析其他研究领域。
1、选择
为了捕捉最新进展,作者回顾了计算机视觉、机器人学和机器学习领域顶会近期发表的论文。具体来说,他们通过网络爬虫从顶级会议(如 CVPR、ECCV、ICCV、CoRL、RSS、ICRA、NeurIPS 等)和业界研究平台(如 Nvidia、Meta、OpenAI 等)收集论文。他们收集了论文标题、作者、摘要和 PDF 链接。然后,他们使用预定义标准的高效 LLM 对论文标题和摘要进行领域过滤,以确保与本研究的相关性。
2、领域过滤
作者将收集的论文集定义为 P,虽然这些论文通常属于视觉、语言、机器学习和机器人技术等广泛领域,但不能保证每篇论文都直接与本文的特定重点(如基础模型(D_𝑓)和机器人技术(D_𝑟))相符。
为此,作者引入了领域过滤步骤 —— 利用高效的 LLM 和精心设计的提示词,识别与本文研究范围相关的论文。为了确保正确的过滤,他们首先定义了基础模型和机器人领域的范围,明确了不同领域之间的技术边界。以下是他们为研究重点设计的提示词:

经过高效 LLM 过滤后,结果论文集(P′)将属于基础模型领域、机器人领域或两者的交集。正式写作:P′ = {𝑝 | 𝑝 ∈ D_𝑓 ∪ D_𝑟}
给定在基础模型和机器人领域筛选出的论文集 P′,作者需要进行深入分析以明确每篇论文的定位。在基础模型和机器人领域专家的指导下,他们定义了与既定领域结构、新兴趋势和不断发展的知识相契合的视角。除了预定义的视角外,他们的流程还支持未来用户自定义视角,从而能够适应新的研究问题。
1、基础模型
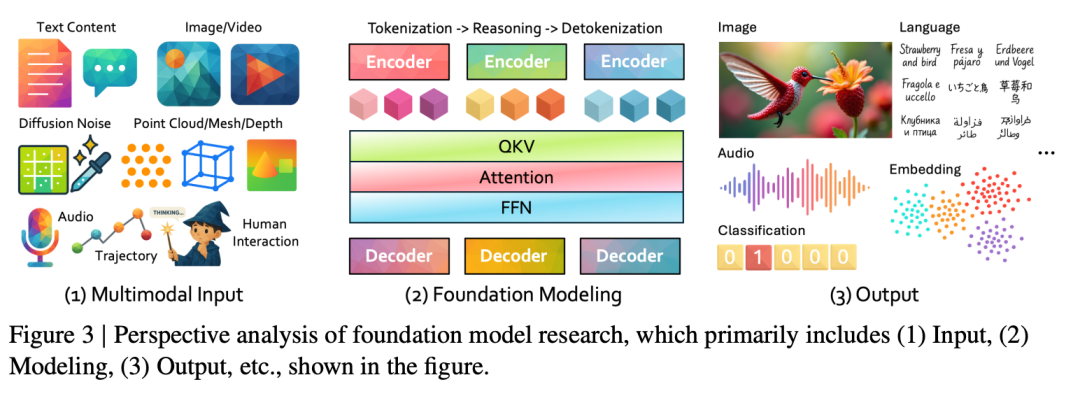
这项研究从五个基本角度对基础模型的开发进行了系统分析:输入(I)、建模(M)、输出(O)、目标(W)和学习方法(R)。图 3 中展示了一些主要角度的示例。这种结构化的表示有助于对基础模型进行全面分析。
2、机器人领域
在机器人学的研究工作中,核心视角转变为强调硬件以及在真实世界环境中的交互。作者定义了五个关键视角,以将每篇论文纳入更广泛的机器人应用领域:输入传感器(S)、物理机身(B)、联合输出(J)、动作空间(A)和环境(E)。核心视角的示例如图 4 所示。


他们将这种投影过程正式定义如下:对于任何文本片段𝑥 ∈ D,其嵌入计算为:𝑣_𝑥 = G (𝑥) ∈ R^𝑑。他们的核心假设是,通过这种具有视角感知的嵌入过程对论文内容进行投影,并在高维流形中对其进行分析,他们可以通过系统的可视化和聚类分析,揭示文献中有意义的模式、研究趋势和潜在空白。
嵌入分析的目标是构建对先前提取的嵌入的理解。嵌入分析的流程包含三个部分:
为了评估生成的调查问卷的准确性和质量,作者开展了一项用户研究,参与者是在机器人技术和基础模型领域拥有专业知识的资深研究人员。为了评估生成的综述的质量,他们采用了成对比较法,而非让评估人员选择一个最佳输出。
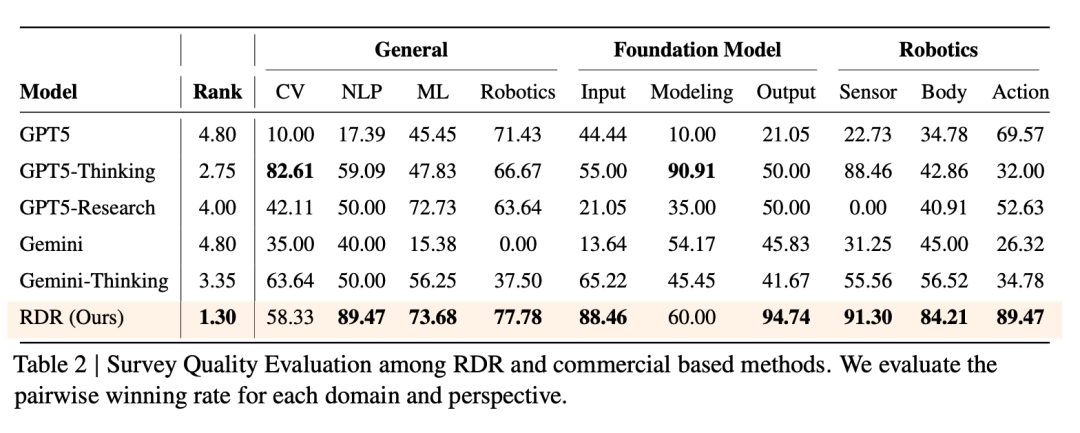
如表 2 所示,RDR 取得了最高的整体性能,平均排名为 1.30,优于所有基线方法。RDR 在自然语言处理(89.47)、机器人技术(77.78)和基础模型输出(94.74)等关键领域处于领先地位,在传感器(91.30)和动作(89.47)等机器人技术子领域也表现出强劲的性能。虽然 GPT5-Thinking 在计算机视觉(82.61)和基础模型建模(90.91)方面略胜一筹,但 RDR 在几乎所有类别中都稳居榜首或接近榜首。
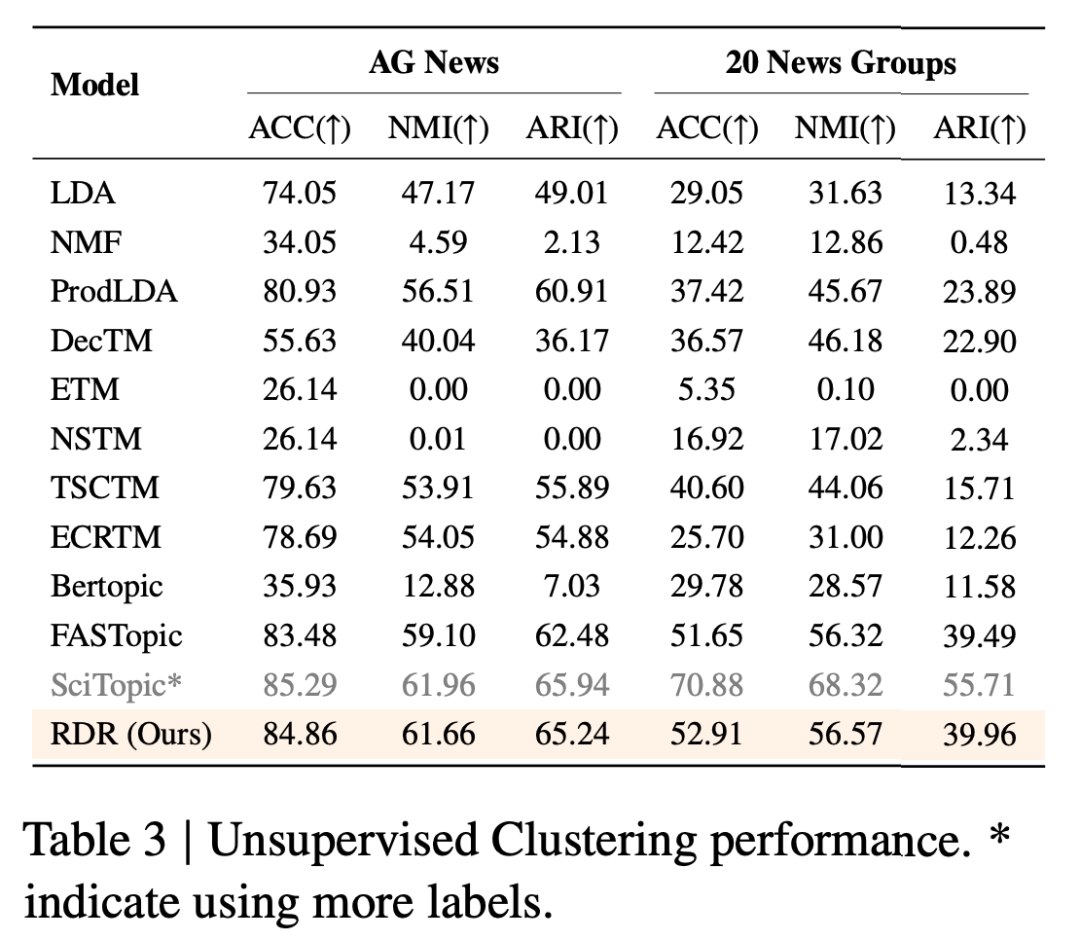
由于文中的大部分分析都依赖于高质量的嵌入,作者使用在冻结表示之上训练的简单线性探针来评估其有效性 —— 这种方法最能反映嵌入本身的内在效用。他们遵循 SciTopic 中介绍的实验方案,使用相同的无监督训练和评估拆分来确保公平比较。与本文方法不同,SciTopic 在训练过程中使用伪标签,这引入了弱监督;因此,为清晰起见,作者在结果中淡化了它的条目。
如表 3 所示,RDR 在两个数据集上都取得了最佳性能,在 AG News 上的准确率为 84.86,在 20 News Groups 上的准确率为 52.91。RDR 在 NMI(61.66 和 56.57)和 ARI(65.24 和 39.96)方面也处于领先地位,优于所有完全无监督的基线,甚至超过了伪监督的 SciTopic 模型。
参考链接:https://x.com/rohanpaul_ai/status/1981985831200952392
文章来自于“机器之心”,作者 “张倩”。


【开源免费】ScrapeGraphAI是一个爬虫Python库,它利用大型语言模型和直接图逻辑来增强爬虫能力,让原来复杂繁琐的规则定义被AI取代,让爬虫可以更智能地理解和解析网页内容,减少了对复杂规则的依赖。
项目地址:https://github.com/ScrapeGraphAI/Scrapegraph-ai
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
