# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在人工智能领域,推理语言模型(RLM)虽然在数学与编程任务中已展现出色性能,但在像医学这样高度依赖专业知识的场景中,一个亟待回答的问题是:复杂的多步推理会帮助模型提升医学问答能力吗?要回答这个问题,需要构建足够高质量的医学推理数据,当前医学推理数据的构建存在以下挑战:
数据匮乏:现有医学领域思维链数据规模较少,且缺乏一个流水线来批量构建一个高质量大规模医学推理数据集;
来源单一:现有数据集多依赖单一模型生成,未能结合不同预训练模型的知识域差异,丰富和探索多样化的推理路径;
构建数据成本高:构建高质量、大规模医学推理数据集往往需要调用大模型生成和人工参与验证,计算和人力成本都非常高昂,难以支撑百万级规模的扩展。
缺乏有效性验证:缺乏系统性实验来对比「详细解说诊断思维」与「直接给出结论」两种训练策略的优劣。
因此,我们亟需探索更科学的方法,为模型注入权威医学知识、扩展其知识边界,并生成更严谨、高质量的多步推理路径。针对上述挑战,ReasonMed 提出一套完整的医疗推理数据生成解决方案:
多源知识的整合:从四个权威医学问答基准(MedQA、MMLU、PubMedQA、MedMCQA)汇聚约 19.5 万医学问题,覆盖广泛的专业知识面。
多模型的数据构建:通过引入多个专有模型,共同生成并验证医疗推理路径,多模型互补与交叉验证提升了知识覆盖与逻辑一致性,更好的构建规模化且高质量的医学推理数据。
基于多智能体交互的多维验证和优化:设计「Easy-Medium-Difficult」分层管线,根据验证通过率动态选择不同处理策略。通过多智能体交互的方式来对医学推理数据的逻辑一致性、答案正确性和医学事实性多维度进行验证优化,实现高质量与低成本的平衡。
推理路径注入和精炼:引入推理路径注入与自动化精炼机制,以提升逻辑连贯性与知识准确度。同时对于每条推理样本保留完整的多步推理链(CoT)与由响应摘要器生成的简明答案(Response),实现推理过程与最终结论的双重监督。
基于上述框架,阿里巴巴达摩院联合多家机构提出医学推理数据生成新范式 ReasonMed,并开源百万级高质量数据集 ReasonMed370K。该范式通过多智能体协作、多温度采样与逐步校验,动态调用不同参数模型,既保证推理质量与知识注入,又显著提升数据多样性。
基于此数据集训练微调的 ReasonMed-7B/14B 在多项权威医学问答基准上(PubMedQA 上性能:82.0%)超越更大规模模型(LLaMA3.1-70B:77.4%),充分验证了「小模型 + 高质量数据」的潜力。同时 ReasonMed 也在 EMNLP 2025 上以高分(9 分)被接收。

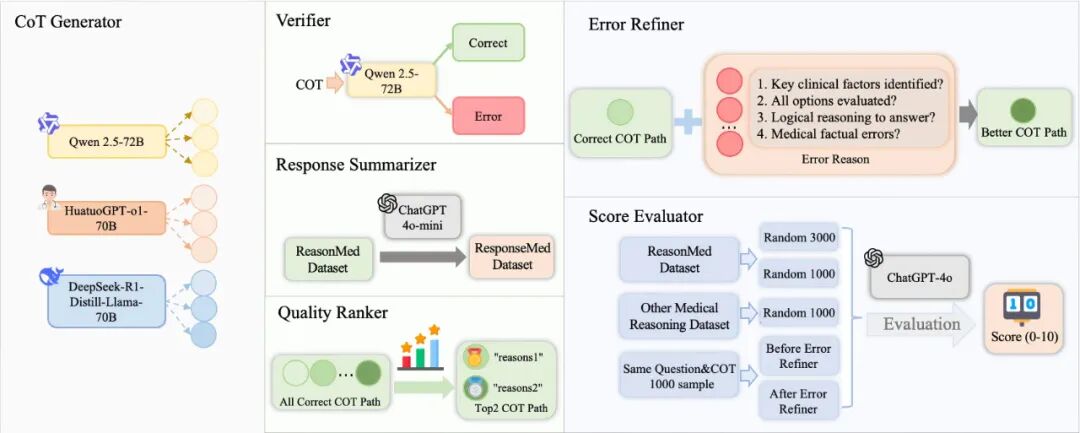
ReasonMed 的多智能体体系由多个专门角色(Agents)组成,每个 Agent 负责不同阶段的推理生成、验证与优化,共同构建高质量医学推理数据集。下面是 ReasonMed 中各个组件的功能介绍:
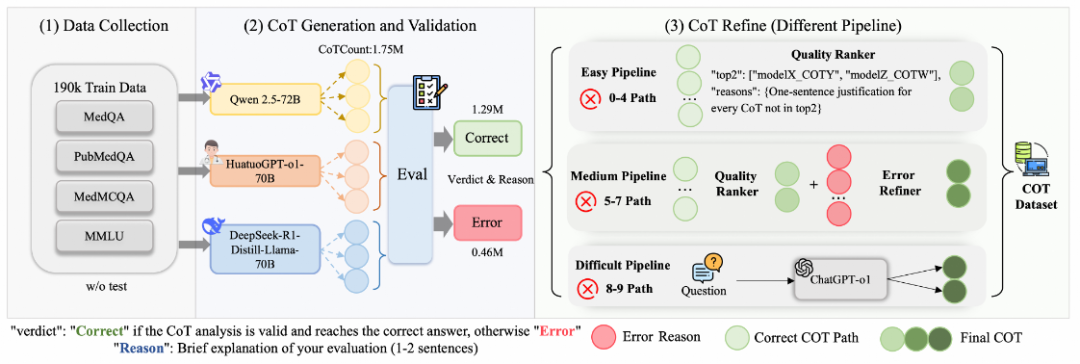
基于以上的多智能体系统,ReasonMed 整个医疗推理数据生成过程分为以下三个步骤:
ReasonMed 首先从四个权威医学问答数据集(MedQA、MedMCQA、PubMedQA、MMLU)收集 19.5 万个医学问题,构建初始问题库。这些问题覆盖解剖学、临床知识、遗传学等多个子领域,为多模型协同生成提供广泛知识基础。
在该阶段,CoT Generator 针对每个问题以不同温度参数进行采样,共生成 9 条多步推理链,覆盖从直接推断到深度分析的多层逻辑,随后由 Verifier 智能体协同完成验证。 这一流程实现了从多模型输出到结构化、多维验证的知识融合,确保了生成数据在多样性与正确性上的平衡,为后续分层精炼与高质量医学推理数据集的构建奠定了基础。
根据 Verifier 验证后统计到的推理链错误数量,ReasonMed 设计了 Easy / Medium / Difficult 三条 Pipeline:
我们通过 Score Evaluator,基于逻辑连贯性(coherence)、医学事实一致性(factual fidelity)、选项分析完整性(option analysis)等方面对样本进行 0–10 分量化评分,验证各阶段精炼带来的质量提升。
经过这一全流程筛选与优化后,最终形成 37 万条高质量医学推理样本(ReasonMed370K),用于后续模型训练与评估。基于同样的评分逻辑,我们也对比了生成的数据和当前公开医学推理数据的质量:

结果表明,ReasonMed 在评分均值上显著优于现有公开数据集,验证了 ReasonMed 框架的有效性。
为了进一步分析「显式推理」与「总结式回答」等不同的思维模式在医学大模型训练中的贡献,我们从同一数据源中抽取并拆分出三个变体:

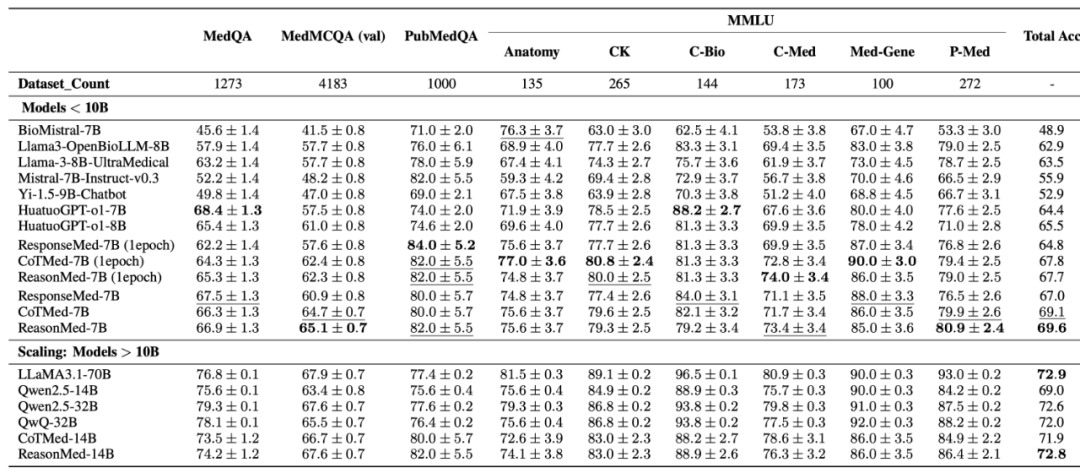
为了验证生成数据对于模型构建的贡献,我们基于 ReasonMed370K/ResponseMed370K/CoTMed370K 在 Qwen2.5-7B 进行了微调构建了三族模型 ReasonMed-7/14B,ResponseMed-7B 和 CoTMed-7B/14B。我们和当前的主流医疗/通用模型在 MedQA/MedMCQA/PubMedQA/MMLU 数据集上进行了对比。得到以下结论:
在多个权威医学问答基准(包括 PubMedQA、MedMCQA、MMLU-Med)上,ReasonMed-7B 展现了显著优势。
其中,在 PubMedQA 上达到 82.0% 的准确率,超过了 LLaMA3.1-70B 的 77.4%;在 MedMCQA 与 MMLU 医学子集上也表现稳定提升。
进一步扩展至 14B 参数规模后,ReasonMed-14B 的整体准确率达到 72.8%,相较于 Qwen2.5-14B 提升 3.8%(72.8% vs 69.0%),并在总体性能上超越 Qwen2.5-32B(72.6%),与 LLaMA3.1-70B(72.9%)几乎持平。
这表明 ReasonMed 的「多智能体生成 + 分层优化」策略具备强大的可扩展性——即便是中小规模模型,也能在医学推理任务中实现与超大模型相当的表现。
为了分析不同数据类型对模型推理能力的影响,团队基于同一底座(Qwen2.5-7B)训练了三个版本:
CoTMed-7B:学习完整推理路径,强调逻辑链条复现;
ResponseMed-7B:仅学习简明答案,注重输出的准确性与简洁性;
ReasonMed-7B:结合推理路径与总结式答案的混合训练策略。
结果显示,ReasonMed-7B 的融合策略效果最佳,在综合准确率上达 69.6%,分别超越 CoTMed-7B(69.1%)和 ResponseMed-7B(67.0%)。同时,其生成输出在逻辑深度与表达简洁度之间取得了良好平衡,既具可解释性,又具实用性。
这验证了 ReasonMed 的核心理念:显式推理链的学习能显著增强模型的泛化推理能力,而「推理 + 总结」融合策略是医学 QA 领域更优的训练路径。
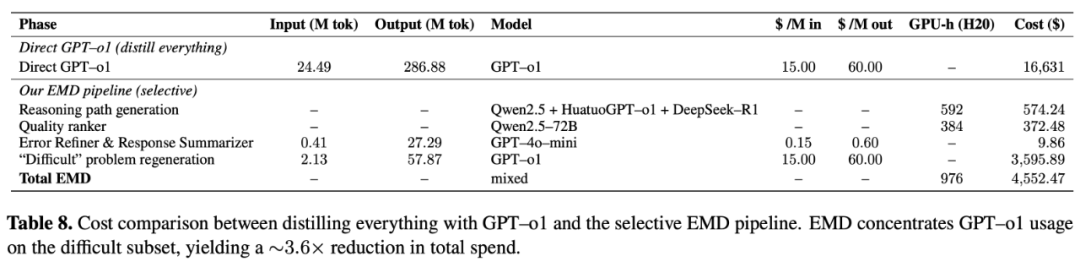
同时我们也验证了,ReasonMed 的分层优化机制(Easy / Medium / Difficult Pipeline)在确保数据质量的同时显著降低了数据构建成本。
若完全依赖最先进的大模型 API 生成 37 万条复杂推理链,成本预计在 16,631 美元;而在 ReasonMed 的实际设计中,仅约 2.56% 的样本进入最高难度流程,需调用更强模型,其余问题均由中等规模模型完成。 在这一策略下,项目总成本约 4,552 美元(o1 API 推理花费 3,595 美元),实现了 70% 以上的成本节省。
这种「难题精修、易题高效」的分层机制,在保证推理链质量与一致性的前提下,实现了高性价比的数据构建,为大规模推理数据的可持续生产提供了可复制模板。
ReasonMed 项目的推出,为医学 AI 研究提供了新的范式,其核心价值主要体现在以下几个方面:
填补医学推理数据空白:ReasonMed370K 提供了当前业界规模最大、质量最高的开源医学推理数据集,极大缓解了医学领域数据匮乏的问题,为后续研究和应用提供了坚实可靠的基础。
验证了显式多步推理在医疗模型的训练的关键作用:通过系统性地验证显式推理路径对模型性能提升的关键作用,ReasonMed 明确了知识密集型 AI 的训练方法论,为未来 AI 模型的研发提供了清晰的实践指南。
推动「小模型 + 高质量数据」路线:在特定专业领域,小模型搭配高质量数据可显著超越更大规模模型的性能,可以有效降低了医疗 AI 工具研发的成本门槛。
低成本,标准化的可扩展思维链生成框架:ReasonMed 框架可以迁移至其他知识密集领域(如生命科学,材料科学等),为构建特定领域的数据集提供了参考,具有跨领域应用的潜力。
同时,ReasonMed 相关技术也用到了达摩院多模态医疗大模型 Lingshu[1] 的构建中。接下来,我们计划进一步扩展数据覆盖的深度与广度,探索如影像诊断、多模态理解、医学工具调用等更复杂的医学推理场景。同时,我们也希望通过开放协作,让更多研究者参与数据完善与模型优化,共同建立一个持续演化、可信可复用的医学推理生态。
ReasonMed 发布后在社区内引发了积极反响。研究者普遍认为其「多智能体 × 分层调优」策略为高质量推理数据生成提供了新范式,并在 Hugging Face 与社区获得了广泛关注。论文发布当天即登上 Hugging Face「Paper of the Day」榜首,并获得 Hugging Face CEO 在 X 平台的转发与推荐,引发了业内研究者与开发者的热烈讨论。

[1]https://huggingface.co/lingshu-medical-mllm
文章来自于“机器之心”,作者 “孙雨”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
