# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
你有没有想过,为什么每次和 AI 聊天,它总是忘记你之前说过的话?为什么你不得不一遍又一遍地重复同样的背景信息,就好像 AI 患上了失忆症一样?现在的 AI 模型越来越聪明,但它们却有一个致命缺陷:没有真正的长期记忆。这不仅让用户体验糟糕,更限制了 AI 应用的想象空间。
有一个 19 岁的印度少年,决定解决这个问题。他叫 Dhravya Shah,来自孟买。这个还在上大学的年轻人,刚刚拿到了 260 万美元的种子轮融资。投资人名单读起来就像硅谷名人录:谷歌 AI 负责人 Jeff Dean、DeepMind 产品经理 Logan Kilpatrick、Cloudflare CTO Dane Knecht,还有来自 OpenAI、Meta 和 Google 的多位高管。领投方是 Susa Ventures、Browder Capital 和 SF1.vc。

我深入研究了 Dhravya 的故事后,发现他的创业历程充满了戏剧性。从在家里用折腾 Discord 机器人开始,到卖掉第一个产品赚到钱,再到因为一个网站被攻击而意外进入 Cloudflare 工作,最后创立 Supermemory 获得顶级投资人支持。这个过程只用了几年时间,而他现在才刚满 20 岁。更有意思的是,他解决的问题——AI 的记忆——正是当下所有 AI 应用都在面临的核心痛点。
PS:我自己的AI出海项目正在招优秀的工程师和产品,可以到合伙人级别,感兴趣的可以直接加我微信MohopeX聊聊。
AI 的记忆问题到底有多严重
我每天都在使用各种 AI 工具,从写作助手到代码生成器,从邮件管理到视频编辑。但我发现一个普遍存在的问题:这些工具总是忘记我之前告诉过它们的信息。每次开始新对话,我都要重新介绍自己的背景、偏好和需求。这种体验就像每天早上醒来都要重新认识一个人,既低效又令人沮丧。
表面上看,现在的 AI 模型的上下文窗口已经越来越大了。研究人员也在不断探索如何提升模型的长期记忆能力。但问题是,这些模型往往无法在多次对话中保持上下文。你今天告诉它的信息,明天就忘得一干二净。对于需要个性化体验的应用来说,这简直是灾难。

Dhravya 从自己的实际需求出发,意识到这个问题的严重性。他当时正在疯狂学习各种知识,在网上收集大量信息。他需要一个工具来管理这些知识,并能够在需要时快速调取。更重要的是,他希望 AI 能够记住这些信息,而不是每次都要重新输入。这个痛点不仅他自己有,成千上万的用户也面临同样的困扰。
我观察到,现在市面上的 AI 应用主要分为两类:一类是像 ChatGPT 这样有记忆功能的大厂产品,但这些记忆被锁定在特定平台上,无法迁移。另一类是各种垂直领域的 AI 工具,它们往往没有记忆能力,每次使用都像从零开始。这就造成了一个悖论:AI 越来越智能,但用户体验却没有相应提升,因为缺少了个性化和连续性。
Supermemory 要解决的正是这个问题。它提供了一个通用的记忆 API,让任何 AI 应用都能拥有记忆能力。不管是写作工具、日记应用、邮件客户端还是视频编辑器,都可以通过 Supermemory 来理解用户的历史行为和偏好。这种记忆不是简单的数据存储,而是能够提取洞察、理解上下文、建立知识图谱的智能系统。
一个19岁创业者的不寻常之路
Dhravya 的创业故事充满了意外和转折。他最早接触编程是在疫情期间,那时他还在上十年级。他开始做的第一个项目是一个 Discord 机器人,这个机器人在 ChatGPT API 出现之前就已经有了 AI 功能,这让他至今引以为傲。这个机器人最终被数千个服务器使用,有数十万用户。这是他第一个真正成功的产品,也让他意识到编程的魅力。
紧接着,他和朋友一起做了一个 Discord 机器人托管服务,意外地开始了第一次创业。他们有 8000 个客户,这个业务后来也被收购了。但更有意思的是,在同一台服务器上,他还运行着一个小项目:自动把 Twitter 推文转成好看的截图,然后发到 Instagram 上。他把这个功能做成了一个 Twitter 机器人,结果吸引了大量用户关注。
这个 Twitter 机器人最终被社交媒体工具 Hypefury 收购。当时 Dhravya 正在准备 IIT(印度理工学院)的入学考试,这次收购让他赚到了一笔不错的钱。他做了一个大胆的决定:放弃考 IIT,转而去美国亚利桑那州立大学读书。他的逻辑很简单:他看到 IIT 毕业生的工资水平,发现自己现在已经赚到了那个数字,那还有什么理由非要去 IIT 呢?
到了美国之后,Dhravya 给自己设定了一个挑战:连续 40 周,每周都要做出一个新东西。这期间他做了各种各样的项目,从数据库到消费级应用,从 AI 工具到基础设施,什么都尝试。他参加了多个黑客马拉松,包括 Cal Hacks、Hack Princeton 和 Stanford 的 Tree Hacks,其中一些赢了,一些输了。但每一次尝试都让他学到新东西,积累了大量的技术经验。
在这个过程中,有一周他做了一个叫 Any Context 的工具,可以让你和自己的 Twitter 书签对话。他把代码开源到 GitHub 上,结果这个项目意外走红。他在推文中说:"这可能价值一百万美元,因为我在上面花了很多心血,但你可以免费拿去用。"这条推文带来了大量关注,项目迅速增长。
但更戏剧性的事情发生了。他另一个项目 dumb.place 遭到了攻击,每秒收到数百万次请求。为了保护自己的网站,他不得不研究如何绕过 Cloudflare 的防护机制进行反向工程。这个经历让 Cloudflare 的 CTO Dane Knecht 注意到了他,直接在 Twitter 上给他发了私信,邀请他加入 Cloudflare。就这样,他意外地获得了一份工作。
在 Cloudflare 工作期间,Dhravya 学到了如何在大规模场景下构建基础设施。他甚至还申请了一项专利,用于提高 AI agent 的速度。更重要的是,他的直属经理在他入职前就离开公司去创业了,所以 Dane 成了他的实际导师。Dane 会坐在他旁边看他写代码,有时会说"这代码写得很糟糕,但没关系,我们周一再改"。这种轻松但深入的指导方式让 Dhravya 快速成长。
在这段时间里,Cloudflare 的各种顾问,包括 CTO Dane Knecht,都鼓励他把 Supermemory 做成一个真正的产品。2025 年,他决定全职投入 Supermemory 的开发。这时候他面临一个实际问题:他的钱已经花光了。他从朋友那里借了 1000 美元,从女朋友那里借了 800 美元,就靠这点钱维持生活。
我特别欣赏他女朋友的故事。当时他在大学里疯狂搞建设,给自己定下的原则是"不谈恋爱、不参加派对、不放松,只专注于建设"。但他的女朋友看到他发的一条关于失败的推文后,主动走过来问他要不要一起散步。就这样他们开始交往。她一直支持他的创业梦想,在他最困难的时候借钱给他。这种理解和支持对创业者来说无比珍贵。
Supermemory 为什么能脱颖而出
我深入研究了 Supermemory 的技术方案后,发现它和市面上其他记忆解决方案有本质区别。大多数所谓的"记忆"系统,本质上只是一个数据库,提供基本的增删改查功能。你可以保存一个实体,给它设定用户范围,然后查询出来。这很有用,但这只是基础功能,任何数据库都能做到。
而 Supermemory 的设计理念完全不同。它是一个记忆引擎,模仿人类大脑的工作方式,而不是简单的数据库。这意味着它不仅能存储信息,还能理解信息之间的关系,进行推理,甚至知道什么时候该忘记什么信息。这听起来很玄乎,但其实非常实用。
首先,Supermemory 内置了数据接入和连接器。文档、图片、PDF、视频等各种数据可以自动从 Google Drive、Notion、OneDrive 等平台导入。你不需要自己构建同步层,这些功能都是开箱即用的。更重要的是,它会详细记录同步周期,精确到分钟级别,让开发者完全了解数据流动的情况。
其次,它会分析和推断关系。每个导入的项目不仅会被嵌入向量空间,还会被构建成知识图谱。实体之间的关系会被映射出来,所以你得到的不仅仅是"相似文本",而是真正智能的推断,就像人类大脑那样思考。比如你问一个模糊的问题,Supermemory 仍然能找到相关的项目,因为它理解了深层的语义关系。
第三,智能检索逻辑是系统的一部分。查询重写、重新排序、过滤这些功能都内置在技术栈中。如果用户问了一个模糊的问题,Supermemory 仍然能找到相关信息。而如果你用其他记忆解决方案,你需要自己在原始向量的基础上编写这些逻辑,这非常耗时且容易出错。
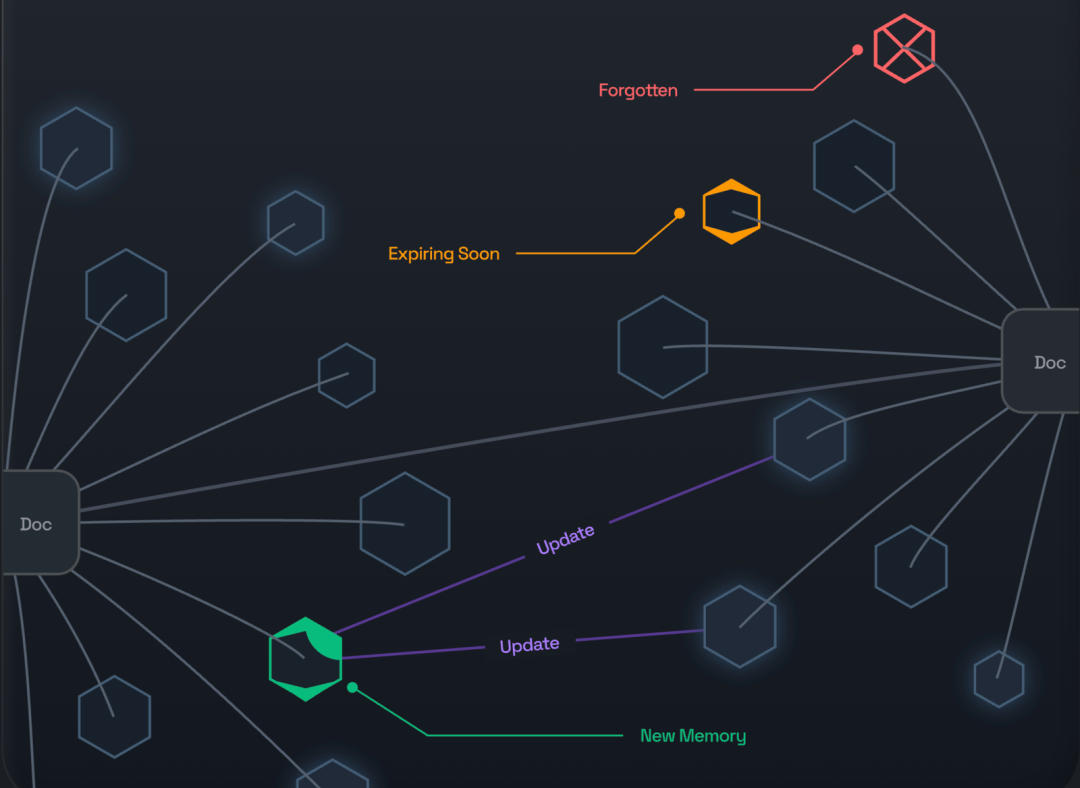
第四,也是最独特的一点:遗忘和推断机制。遗忘不重要的信息实际上是一个功能特性。Supermemory 会自动忘记一定时间后不再重要的东西。比如用户问"最好用的洗衣液是什么",这不是 AI 应该永远记住的信息。人类大脑也是这样工作的,我们会自然地忘记不重要的细节,只保留有价值的信息。
第五,它提供了 Memory Router 功能。这不仅仅是存储层,而是应用层级的产品。Memory Router 能为用户的对话提供几乎无限的上下文窗口。这是在用户体验层面的记忆,而不仅仅是基础设施层面的。
最后,在性能方面,Supermemory 专门为高容量数据接入设计,可以处理超过 10 万 token 的文档和多模态数据。延迟目标是 400 毫秒以下,即使在高负载情况下也能保持。这不是那种"在基准测试中表现好,在生产环境中就不行"的系统。它已经在 Flow、Montra、Cluely、Rube 等实际应用中经过了实战检验。
真实客户案例说明一切
我特别关注了一个叫 Scira AI 的案例,因为它完美展示了 Supermemory 的实际价值。Scira 是一个开源的 Perplexity 替代品,专为需要深度研究的用户设计。它的用户会运行并行查询、构建结构化研究计划,并且越来越需要记忆功能:能够调取自己的笔记、过去的搜索,或者连接 Notion 和 Google Docs 的数据。

一开始,Scira 尝试使用 Mem0 来实现记忆功能。但创始人 Zaid Mukaddam 的评价非常直白:"Mem0 不太好用。很高兴找到了 Supermemory。"整个体验简直是灾难。延迟非常糟糕,导入数据会拖慢整个研究流程。索引不可靠,每次尝试添加记忆时,系统都无法正常工作。上下文召回失败,用户试图把过去的结果带入新查询时,经常什么都没返回。扩展性很弱,随着更多用户添加数据,性能就会下降。连接器根本不可用,用户最想要的集成都没有。
记忆本应该让研究更流畅,结果却成了产品最薄弱的环节。Zaid 受够了,决定迁移到 Supermemory。差异立刻显现出来。集成过程非常简单,Zaid 说 API 稳定且易于使用。测试过程中出现了几个小 bug,但很快就被修复了。
更重要的是稳定性一夜之间改善了。Supermemory 能够持续存储和召回条目,解决了 Mem0 的索引失败问题。延迟大幅下降,Scira 从一个笨重的应用变成了即使启用记忆功能也能流畅运行的工具。连接器开箱即用,Notion、Google Docs、推文等数据源终于可以被引入搜索了。技术支持响应迅速,Zaid 说:"我遇到了一些问题,他们修复得非常快。"或者用他更直白的话说:"比 Mem0 好一千倍。"
切换到 Supermemory 的影响非常明显。使用量增长了约 32%。记忆功能上线后,采用率上升了。有 10 个客户就是因为记忆功能而注册的,他们都是重度研究用户,非常在意上下文。用户反馈变得更好了,记忆从弱点变成了大家重视的功能。性能提升了,应用感觉更轻量,延迟下降,在规模化场景下召回也很可靠。

从技术对比来看,Supermemory 在延迟方面的优势非常明显。在 602 个样本的测试中,使用 LoCoMo 数据集进行对比,平均改进 37.4%,中位数改进 41.4%,P95 改进 22.9%,P99 改进 43.0%,稳定性提升 39.5%。这些数字不是营销话术,而是实际测试结果。
我认为 Scira 的案例说明了一个重要问题:在 AI 应用开发中,基础设施的选择至关重要。一个糟糕的记忆层不仅会拖累用户体验,还会限制产品的发展潜力。而一个优秀的记忆引擎则能释放应用的全部能力,让用户真正感受到 AI 的个性化和智能化。
顶级投资人为什么押注这个19岁少年
Dhravya 能获得如此豪华的投资人阵容,不是偶然的。我研究了他的融资过程后,发现这背后是多年积累的结果。他不是突然出现在投资人面前要钱的,而是通过多年建设和社区贡献,逐渐建立起了强大的人脉网络。
故事要从 buildspace 说起。Supermemory 参加了 buildspace 项目,并且获胜。之后 Dhravya 在社交媒体上获得了大量关注,推文有大约 30 万次浏览。虽然按今天的标准这不算特别火,但足以让很多人注意到他。有投资人开始给他发私信,有创始人甚至专门飞到纽约见他,用商务舱把他接过去,提供 VIP 服务,劝他辍学加入他们公司。还有人跟他说"等你融资的时候告诉我"。

2025 年 1 月,a16z 主动联系他,表示想要投资。与此同时,他还获得了 YC 的 summer fellows grant,这是为想在夏天做研究的个人提供的资助。Dhravya 意识到,自己只是兼职在做这个项目,还有一份工作,却已经得到了这么多关注和机会。那他为什么不全职去做呢?
于是他开始认真对待这件事。他拒绝了 a16z 的 offer,告诉 YC 不要给他那个 grant,因为他不再是学生了,他要融资并把它做成一家真正的公司。YC 的反应是:"那你为什么不直接从我们这里融资呢?"Gary Tan 给他打了电话,劝他加入 YC。但这时候已经太晚了,他已经拿到了很多估值更高的 offer。
更有趣的是,Julian Weisser 这个人物的出现。Julian 当时正住在他楼上,给他打电话说:"我知道你参加过 ODF 项目。如果你要创办公司,是一个人做还是在找联合创始人?"Dhravya 说他在找联合创始人,但主要是因为投资人要求。Julian 说:"我正在考虑创办一个 solo founders house(独立创始人之家),如果你答应,你会是第一个加入的人。你可以有一个地方度过夏天并建立公司。"
Dhravya 面临一个实际问题:他没有签证可以辍学。Julian 也帮他解决了这个问题。Julian 先作为投资人给 Supermemory 投了钱,然后 Supermemory 用这笔钱赞助了他的签证。所以 Julian 成了第一个投资人,早于 a16z 和所有其他人。
之后 Dhravya 开始联系那些之前说过"等你融资就投资"的人。他告诉他们自己正在融资,这在旧金山引发了连锁反应。大家都在传"Dhravya 在融资"。因为 Dane 和 Cloudflare 的人已经看到并谈论过他,说"等他融资的时候会很有意思"。于是 VC 开始主动联系他,各种介绍和对接开始发生,融资就这样完成了。

Jeff Dean 的故事更特别。在 buildspace 期间,Supermemory 快速增长,DeepMind 的产品经理 Logan Kilpatrick 给他发消息问他有没有兴趣加入 Google。Dhravya 当然说有兴趣。但因为他当时还在上学,无法全职加入,所以没成。他还收到了 xAI 和 Anthropic 的 offer。然后他联系所有这些人说:"你们本来要雇我的,为什么不投资呢?"结果大家都同意了。就这样他拿到了 Jeff Dean 的投资。
Joshua Browder,DoNotPay 的创始人兼 CEO,通过 Browder Capital 投资了 Dhravya。他说让他印象深刻的是 Dhravya 的执行力:"我在 Twitter 上和他联系,让我印象深刻的是他行动和建设的速度有多快,这促使我投资了他。"
这对AI行业意味着什么
我认为 Supermemory 的成功代表了 AI 行业的一个重要转折点。我们正在从"模型时代"进入"应用时代",从关注模型能力转向关注用户体验。在这个转变过程中,记忆成为了最关键的基础设施之一。
现在每个 AI 应用都需要记忆层。不管是邮件客户端、代码编辑器、视频编辑软件还是客户支持系统,都需要理解用户的历史行为和偏好。但构建一个好的记忆系统非常困难,需要深厚的基础设施知识、AI 技术理解和实际应用经验。大多数公司没有资源从头开始构建这样的系统。
Supermemory 提供了一个标准化的解决方案。它让任何公司都能在几天内为自己的应用添加记忆能力,而不需要投入几个月甚至几年的开发时间。这种基础设施级别的创新,往往能够释放整个行业的潜力。就像云计算让每个公司都能轻松部署服务器一样,Supermemory 让每个 AI 应用都能拥有记忆能力。
目前 Supermemory 的客户包括 a16z 支持的桌面助手 Cluely、AI 视频编辑器 Montra、AI 搜索 Scira、Composio 的多 MCP 工具 Rube 和房地产初创公司 Rets。他们甚至还在和一家机器人公司合作,帮助机器人保留视觉记忆。这些多样化的用例说明了记忆的通用性:不管你在构建什么类型的 AI 应用,你都需要记忆。
当然,这个领域的竞争也很激烈。像 Felicis Ventures 支持的 Letta 和 Mem0 都在为 AI agent 构建记忆层。Susa Ventures 还投资了 Memories.ai,这家公司可以从数千小时的视频中提取洞察。但 Dhravya 认为 Supermemory 的优势在于更低的延迟和更好的性能。在 AI 应用中,延迟往往决定了用户体验的好坏。
我特别关注 Supermemory 的开放性策略。他们不仅提供云服务,还准备发布本地优先版本,可以部署在用户的手机、笔记本或浏览器上。这解决了很多企业对数据隐私和安全的担忧。你可以享受 AI 记忆的好处,同时保持对数据的完全控制。
对于消费者来说,Supermemory 正在改名为 Supermemory Noa,定位为"一个了解你一切的 AI agent"。这个产品会汇集你在所有应用和客户端中的活动,提供跨平台的记忆能力。想象一下,不管你用什么工具,AI 都记得你的偏好、习惯和历史,能够提供真正个性化的体验。这才是 AI 应该有的样子。
我对这个故事的思考
Dhravya 的故事给了我很多启发。他不是那种按部就班读书、工作、然后创业的典型路径。他在高中时期就开始建设各种项目,有些成功了被收购,有些失败了成为教训。他没有完成传统意义上的教育,但通过大量实践积累了远超同龄人的经验。
我特别欣赏他的学习方法。他不是系统地学习某门课程,而是有问题就解决问题,需要什么就学什么。他会在 Discord 社区提问,会疯狂阅读文档和技术文章,会跟随各个领域的专家学习。这种实战驱动的学习方式,让他能够快速掌握新技术并应用到实际项目中。
他的连续建设能力也让我印象深刻。40 周每周做一个新项目,这需要极强的执行力和创造力。很多人可能只是做完就扔掉了,但 Dhravya 会认真对待每一个项目,参加黑客马拉松,开源代码,在社交媒体上分享。正是这种持续的输出,让他建立起了强大的个人品牌和人脉网络。
他的创业故事也证明了一点:机会往往隐藏在意外之中。他因为网站被攻击而学会了反向工程,结果获得了 Cloudflare 的工作机会。他因为想管理自己的知识而做了一个工具,结果这个工具成了一家有数百万美元融资的公司。关键是要保持开放的心态,抓住每一个可能的机会。
我也注意到他对失败的态度。他在社交媒体上公开分享了所有失败的项目,毫不避讳。这种坦诚不仅让他获得了社区的支持,也帮助他从失败中学习。每一次失败都是下一次成功的垫脚石。正是那些失败的项目,让他知道什么行得通、什么行不通。
最后,我想说的是,Dhravya 解决的问题——AI 的记忆——是真实而紧迫的。随着 AI 应用越来越普及,个性化和上下文理解将成为核心竞争力。没有记忆的 AI 就像患了失忆症的人,永远无法真正理解用户。Supermemory 提供的不仅仅是一个技术解决方案,更是通向下一代 AI 应用的基础设施。
Joshua Browder 说得好:"越来越多的 AI 公司将需要记忆层。Supermemory 的解决方案提供了高性能,同时让你能够快速调取相关上下文。"这正是问题的核心。记忆不是可有可无的功能,而是 AI 应用的必需品。谁能提供最好的记忆解决方案,谁就能在这场竞赛中胜出。
我相信 Dhravya 和 Supermemory 正走在正确的道路上。他们不是在追逐概念或炒作,而是在解决真实的问题。他们的客户正在使用他们的产品,每周发送数十亿个 token。这些都是实实在在的数据,证明了市场需求的真实性。
更重要的是,Dhravya 展示了新一代创业者的特点。他们不需要等到大学毕业或工作多年才开始创业。他们从很早就开始建设,通过实践学习,在社区中成长。他们不害怕失败,不害怕公开分享,不害怕向他人求助。他们用行动证明,年龄不是创业的障碍,经验可以通过快速迭代来积累。
从一个在孟买家里折腾 Discord 机器人的少年,到获得硅谷顶级投资人支持的创业者,Dhravya 用了短短几年时间。但这几年里,他建设了数十个项目,完成了两次收购,在 Cloudflare 申请了专利,创建了一个拥有数万用户的开源项目,最终融资 300 万美元。这个速度和强度,正是这个时代创业的缩影。

我们正处在 AI 变革的关键时刻。模型越来越强大,应用越来越多样,但用户体验的提升却没有跟上技术进步的速度。记忆是缩小这个差距的关键。当 AI 真正能够记住你的偏好、理解你的上下文、预测你的需求时,它才能从工具变成助手,从助手变成伙伴。
Supermemory 正在构建这个未来的基础。而 Dhravya 的故事告诉我们:改变世界不需要等到你准备好了才开始,你可以边做边学,边学边成长。只要你解决的是真实的问题,只要你持续建设和迭代,机会就会到来。19 岁不是限制,而是优势。因为你有更多的时间去尝试,更少的包袱去冒险,更强的动力去证明自己。
接下来会发生什么?Supermemory 正在扩大团队,招聘工程、研究和产品方面的人才。他们计划发布本地优先版本,让记忆可以在设备端运行。他们正在改造消费者应用,打造一个真正了解你一切的 AI agent。这些都只是开始。随着越来越多的 AI 应用接入 Supermemory,随着记忆能力变得越来越强大,我们将看到全新的用户体验和应用场景。

这不仅仅是一家创业公司的故事,这是整个 AI 行业进化的信号。从推理到记忆,从一次性交互到持续关系,从工具到伙伴。Dhravya 和他的团队正在书写这个故事的新篇章。而对于那些还在观望的人,现在是时候关注这个领域了。记忆不再是未来,它已经是现在。
文章来自于微信公众号 “深思圈”,作者 “深思圈”


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
