# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当用户向大语言模型提出一个简单问题,比如「单词 HiPPO 里有几个字母 P?」,它却正襟危坐,开始生成一段冗长的推理链:「首先,让我们分析 HiPPO 这个词,河马的英文单词为 hippo,河马是一种半水生哺乳动物,这里用户用了大写字母,可能有特殊的含义,对于单词 HiPPO,我们可以将其拆分为 H-i-P-P-O,字母 P 出现在第 3 与第 4 个位置,因此有 2 个字母 P... 让我们简化问题,HiPO 可以拆分为...」
面对这样的「严谨」,用户难免哭笑不得,既浪费了计算资源,也增加了等待时间,甚至更坏的情况是模型被自己冗长的推理链「绕晕了过去」,最终给出了错误的答案,用户只得捶胸顿足地大喊:「这合理吗?」

这种现象,正是当前追求强大推理能力的 LLM 们普遍面临的「过度思考」(Overthinking)困境。
无论是数学计算、代码生成还是逻辑问答,模型似乎习惯了「启动即深思」的模式,即使面对本可直观回答的简单问题,也要展开一番链式思考(Chain-of-Thought, CoT),导致 token 使用量激增、推理延迟变长、部署成本高昂。如何在保持复杂问题解决准确性的同时,避免在简单任务上「空转」、在复杂任务上高效「运转」,成为 LLM 走向实用化的一大关键挑战。
如今,快手 KwaiKAT 团队与南京大学刘佳恒老师 NJU-LINK 实验室、张煜群教授实验室 ARiSE 合作重磅推出HiPO(Hybrid Policy Optimization)框架,为 LLM 装上了智能的「思考开关」。该框架通过创新的混合数据冷启动与混合强化学习奖励系统,使模型能够自主、动态地决策何时该启动详细推理(Think-on),何时该直接给出答案(Think-off)。
这不仅显著提升了推理效率,更在多个核心基准测试上实现了准确率的同步提升,为构建高效、实用的下一代推理大模型提供了解决方案。

大语言模型在复杂认知任务上的巨大成功,很大程度上归功于链式思考(CoT) 推理范式的引入。让模型像人一样「一步一步想问题」,极大地提升了其在数学、编程、科学问题解决等领域的表现。然而,这套强大的推理机制也带来了「认知惯性」:模型倾向于对所有问题都「一视同仁」地进行深度推理。
现有的解决方案试图缓解这一问题,但各有局限:
核心问题在于,缺乏一个原则性的机制,来精细地平衡准确性、回答效率之间的权衡,让模型学会「具体问题,具体分析」。
HiPO 框架的核心思想是将「是否思考」的决策权交给模型自身,并通过系统性的训练方法,确保其决策的智能性与平衡性。其创新性主要体现在两大核心组件上:
组件一:混合数据冷启动—— 为模型装上「智能思考开关」
要让模型学会选择,首先需要让它见识过「思考」和「不思考」两种模式下的高质量回答是什么样的。HiPO 设计了一套精密的自动化数据构建流程,并使用混合数据进行冷启动。
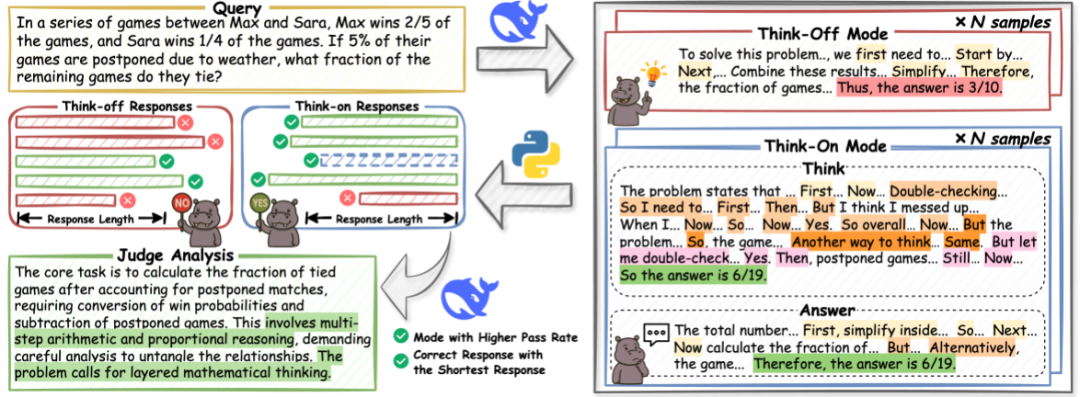
1.数据收集与分类:研究团队整合了多个高质量的公开及专有数学与代码推理数据集(如 AM-Thinking-v1-Distilled, AceReason-Math, II-Thought-RL, Skywork-OR1-RL-Data),构建了一个高质量的训练语料库。
2.双模式响应生成与优选:对于每个问题,使用一个强大的推理模型(如 DeepSeek-V3)分别生成 N 个「Think-on」(带推理)和 N 个「Think-off」(直接回答)的响应。然后,自动验证所有回答的正确性。
3.引入模式解释信号:为了强化模型对模式选择的理解,HiPO 还引入了一个辅助解释信号。对于每个优选出的问答对,会使用 DeepSeek-V3 生成一段理由(Justification),解释「为什么这个问题适合(或不适合)进行深度推理」。这为模型提供了宝贵的元认知信号,帮助其将模式选择与问题内在的复杂性对齐。
这套管道最终产出的数据,每条都包含了问题、最终回答、以及关于思考模式的理由。在这些数据上对模型进行冷启动,使得模型初步具有了「智能思考」的能力。
组件二:混合强化学习奖励系统 —— 精细化引导模型的「决策天平」
有了高质量的数据进行「冷启动」(Cold-Start)训练后,HiPO 通过一个设计精巧的混合强化学习(RL)阶段,对模型进行微调,使其决策能力臻于完善。该奖励系统的核心目标是防止模型过度依赖看似更可靠的「Think-on」模式,实现真正的自适应。
1.基础奖励:每个生成的回答会根据其答案正确性(ACC)和格式正确性(FORMAT)获得一个基础奖励分。
2.偏差调整机制 —— 防止「思考」惯性:这是 HiPO 的一个关键创新。由于 「Think-on」模式通常更准确,模型在 RL 过程中容易产生偏向,无论问题难易都选择「思考」。为了解决这一问题,HiPO 引入了动态的偏差调整机制。
3.混合优势函数 —— 双重监督:HiPO 设计了两个独特的优势(Advantage)函数来提供更精细的指导信号:
最终,这两个优势信号被分别赋予给回答中对应的「理由」部分和「答案」部分的每个令牌,实现令牌级别的精细化优化。整个 RL 过程采用类似 PPO 的算法,在最大化期望奖励的同时,约束策略更新幅度,防止偏离太远。
HiPO 在基于 Qwen3 系列模型(如 8B 参数版本)的实验中,取得了令人瞩目的成果。在 AIME2024/2025、HumanEval、LiveCodeBench(v6)、MATH-500、GPQA-Diamond 等多个权威基准测试上,与多种基线方法进行了全面对比,并进行了充分的消融实验。
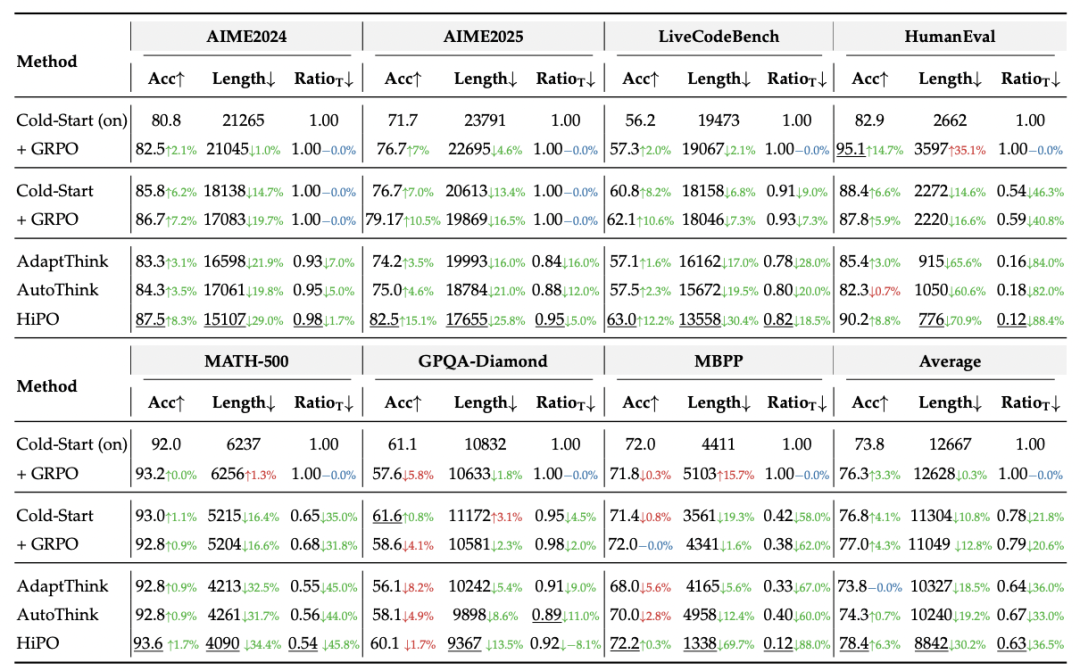
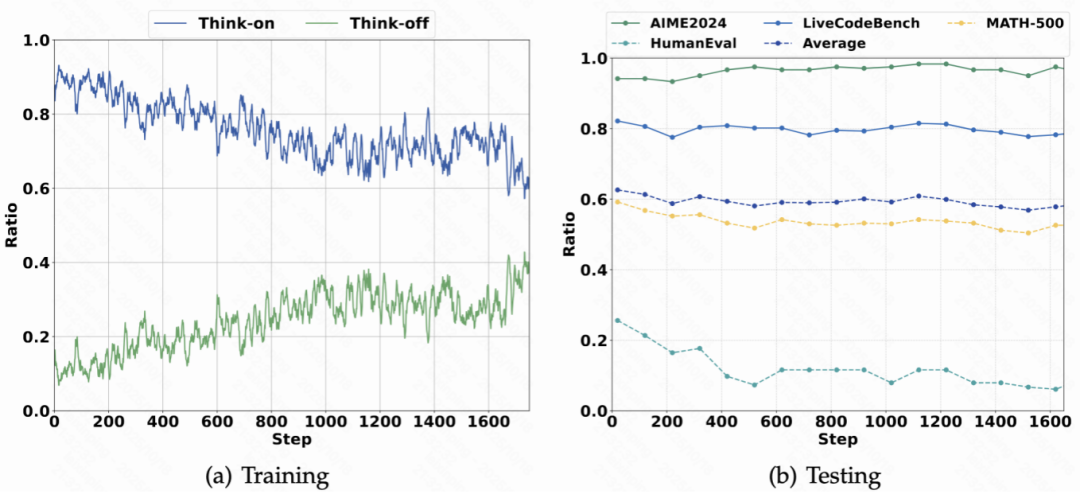
动态决策分析:研究团队还深入追踪了模型在训练和推理过程中的行为演变。
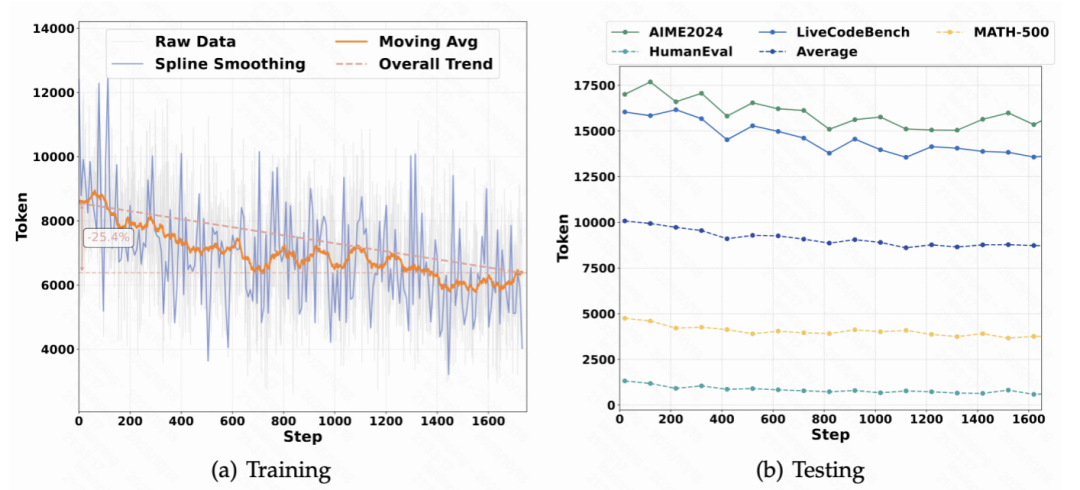
强泛化性:HiPO 的成功不仅在 Qwen3-8B 上得到验证,在 Qwen3-1.7B 和 Qwen3-32B 等不同规模的模型上也展现出一致的性能提升,证明了其方法的普适性。
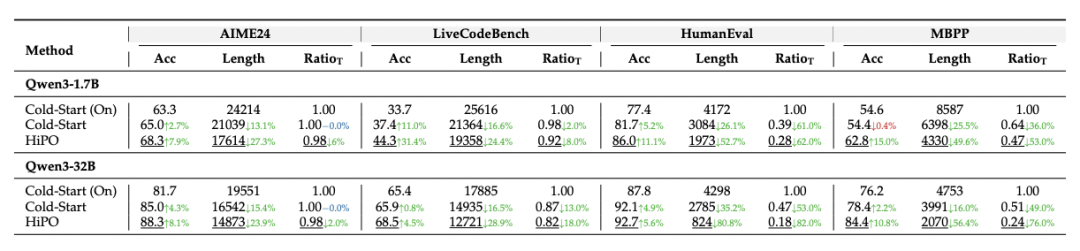
HiPO 框架的提出,不仅仅是一项技术突破,更是为 LLM 的发展方向提供了一个重要的思路转变:从一味追求「更强思考」到追求「更智能地思考」。
当大语言模型陷入「为思考而思考」的认知惯性时,其巨大的潜力被低效的运作方式所束缚。快手与南大团队的 HiPO 框架,如同一位高明的教练,不是粗暴地限制模型的「思考」,而是教会它判断「何时该深思熟虑,何时可一击即中」。
这项研究巧妙地平衡了推理的「质」与「效」,为构建真正高效、可靠、适用于真实世界的下一代人工智能助手奠定了坚实的基础。在 LLM 竞速发展的下半场,「智能效率」 或许将是比「暴力计算」更重要的决胜筹码。
目前,HiPO 的相关模型和资源已在Hugging Face 平台开源,供社区研究和使用。
文章来自于“机器之心”,作者 “机器之心”。



【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
