# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
现代 LLM 通常依赖显式的文本生成过程(例如「思维链」)来进行「思考」训练。这种策略将推理任务推迟到训练后的阶段,未能充分挖掘预训练数据中的潜力。
为解决这一问题,字节 Seed 团队联合多家机构推出了 Ouro,一类被称为循环语言模型(Looped Language Models)的新型预训练模型,其名称源于象征循环与自我吞噬的「衔尾蛇」(Ouroboros)。
Ouro 另辟蹊径通过(i)在潜在空间中进行迭代计算,(ii)采用熵正则化目标以实现学习型深度分配,以及(iii)扩展至 7.7T tokens 的数据规模,将推理能力直接构建到了预训练阶段。 这些设计使得模型能够在预训练阶段直接学习和构建推理能力,而非仅依赖后期微调。

通过对照实验,研究者发现 Ouro 的性能提升并非源于知识存储量的增加,而是得益于其更高效的知识操控与推理能力。进一步分析表明,Ouro 的潜在推理过程相比标准 LLM,更接近真实的人类推理机制。
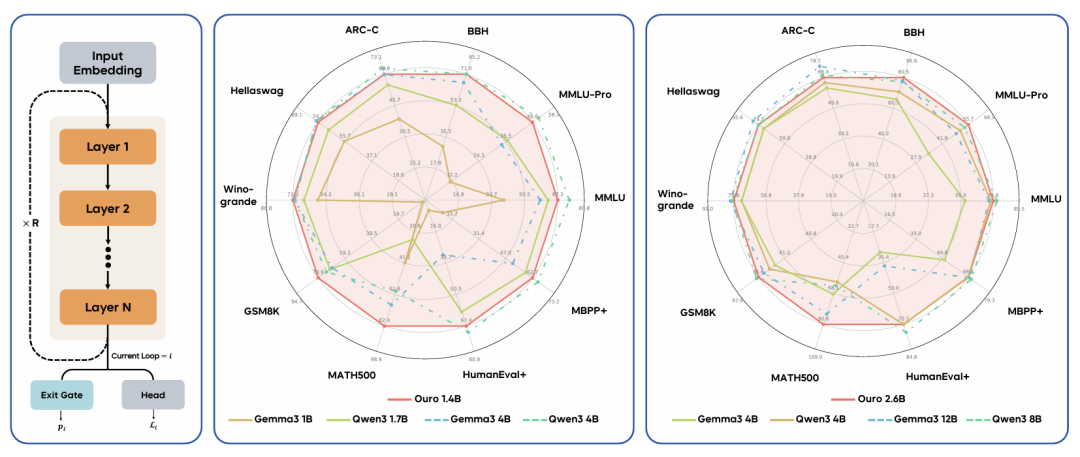
Ouro 循环语言模型的性能。(左)参数共享的循环架构。(中与右)雷达图比较了 Ouro 1.4B 与 2.6B 模型(均采用 4 个循环步,红色)与单独的 Transformer 基线模型。我们的模型表现出强劲性能,可与更大规模的基线模型相媲美,甚至在部分任务上超越它们。
最终,Ouro 的 1.4B 和 2.6B 参数规模的 LoopLM,分别能在几乎所有基准测试中达到与 4B 和 8B 标准 Transformer 相当的性能,实现了 2–3 倍的参数效率提升,显示了其在数据受限时代下作为一种新型扩展路径的潜力。
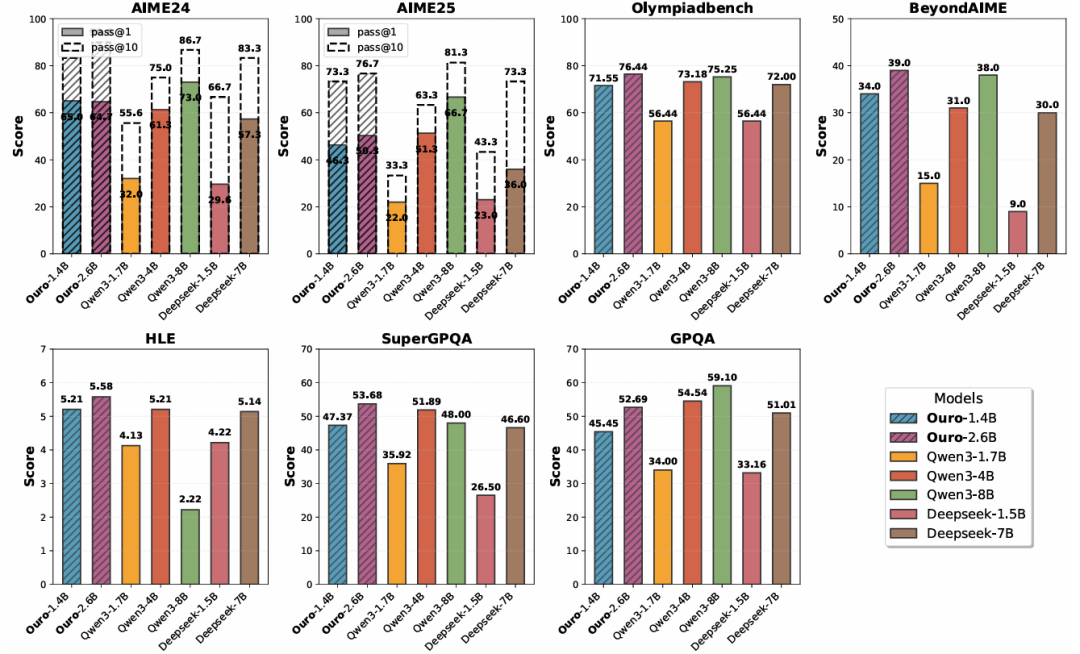
在高级推理基准测试中的表现。Ouro-Thinking 系列模型与强大的基线模型(如 Qwen3 和 DeepSeek-Distill)进行对比。Ouro-1.4B-Thinking R4 的性能可与 4B 规模模型相媲美,而 Ouro-2.6B-Thinking R4 在多个数学与科学数据集上的表现达到或超越了 8B 规模模型。
另外,LoopLM 架构在 HEx-PHI 基准上显著降低了有害性,且随着循环步数(包括外推步)增加,模型的安全性进一步提升。与传统的 CoT 方法不同,研究者的迭代潜变量更新机制产生的是因果一致的推理过程,而非事后的合理化解释。
LoopLM 架构的灵感来源于「通用 Transformer」。其核心思想是在一个固定的参数预算内实现「动态计算」。具体而言,该架构包含一个由 N 个共享权重层组成的「层堆栈」。
在模型的前向传播过程中,这个共享的层堆栈会被循环应用多次,即经历多个「循环步骤」。这种设计将模型的计算规模从「参数数量」解耦到了「计算深度」。
该架构的关键特性是其自适应计算能力。它集成了一个学习到的「退出门」,当模型处理输入时:简单输入可能会在经历较少的循环步骤后就提前退出,从而节省计算资源;复杂输入则会自然地被分配更多的迭代次数,以进行更深层的处理。
这种迭代重用被视为一种「潜在推理」。与 CoT 在外部生成显式文本步骤不同,LoopLM 是在模型的内部隐藏状态中构建了一个「潜在思想链」。每一次循环都是对表征的逐步精炼,从而在不增加参数的情况下提升了模型的知识操纵能力。
Ouro 的训练流程是一个多阶段过程,总共使用了 7.7T tokens 的数据。
如图 4 所示,该流程始于一个通用的预热阶段,随后是使用 3T token 的初始稳定训练阶段。在此之后,模型通过「upcycling」策略分支为 1.4B 和 2.6B 两种参数规模的变体。

两种变体均独立经历后续四个相同的训练阶段:第二次稳定训练(3T token)、CT 退火(CT Annealing, 1.4T token)、用于长上下文的 LongCT(20B token)以及中途训练(Mid-Training, 300B token)。
这个过程产生了 Ouro-1.4B 和 Ouro-2.6B 两个基础模型。最后,为了强化特定能力,模型还额外经历了一个专门的推理监督微调阶段,以创造出专注于推理的 Ouro-Thinking 系列模型。
在训练稳定性方面,团队发现最初使用 8 个循环步骤会导致损失尖峰等不稳定问题,因此在后续阶段将循环步骤减少到 4,以此在计算深度和稳定性之间取得了平衡。
为了让模型学会何时「提前退出」,训练流程采用了新颖的两阶段目标:
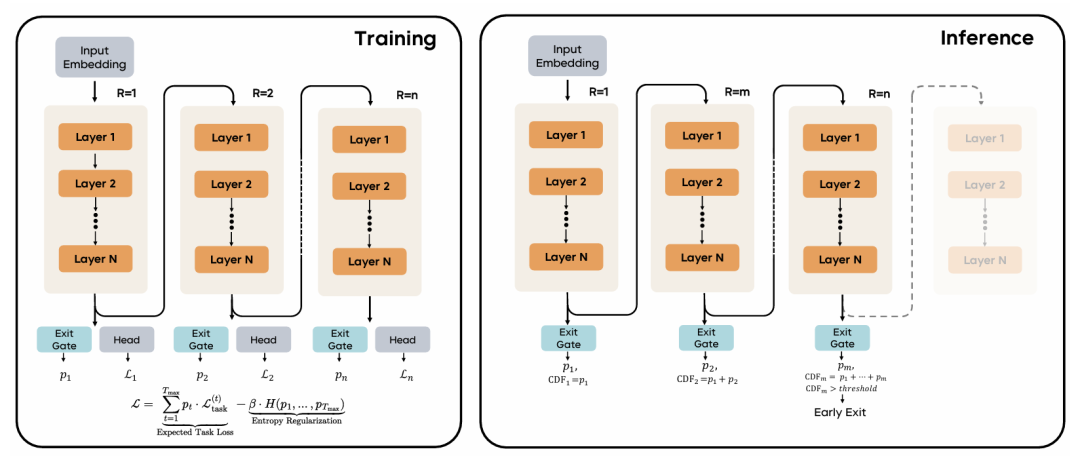
循环语言模型架构概览。
左图为训练阶段。在训练过程中,模型使用共享参数的 N 层堆叠结构,并执行 n 个循环步骤(R = 1 到 R = n)。在每个循环步骤 i,一个退出门预测退出概率 pᵢ,而语言建模头 Lᵢ 则计算对应的任务损失。 训练目标函数结合了所有循环步骤的期望任务损失,并加入熵正则化项 H(p₁,…,pₙ),以鼓励模型探索不同的计算深度。

文章来自于“机器之心”,作者 “机器之心编辑部”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
