# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在几天前,上海交大发布了一篇名为 《上下文工程2.0:上下文工程的上下文》(Context Engineering 2.0: The Context of Context Engineering) 的重磅论文。

论文开篇引用了一句发人深省的格言,巧妙地化用了马克思的名言“人的本质是其社会关系的总和”:
“A person is the sum of their contexts.” (一个人的本质,是其所有上下文的总和。)
这篇论文系统性地梳理了“上下文工程”的演进背景,首次给出了一个严谨的系统化定义,并高屋建瓴地概述了从1.0到4.0的历史概念格局。并且,研究者们深入考察了在当今实践中(Era 2.0)最关键的设计考量——从上下文的收集、管理、抽象到使用。
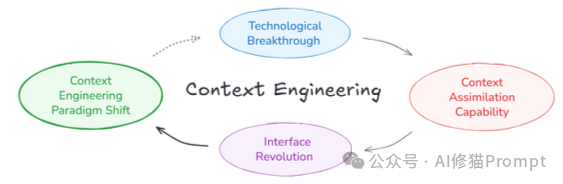
这项工作不仅为我们提供了一张宝贵的“地图”,更是在为未来更高级别的人工智能系统研究,铺设一个坚实的概念地基。它将引领更广泛的社区,开始系统性地思考和建设AI的“上下文”。
在深入探讨这门“艺术”之前,我们必须先回答一个本源问题:到底什么是“上下文”?如果我们的理解仅仅停留在“聊天记录”,那就大大低估了其深刻的内涵。
论文正本清源,追溯到了2001年,也就是“上下文工程1.0”时代的奠基人Anind K. Dey提出的经典定义:


“上下文是任何可用于描述某个实体状况的信息。而实体,则是与用户和应用程序交互相关的任何人、地点或物体,包括用户和应用程序本身。” (Context is any information that can be used to characterize the situation of an entity. An entity is a person, place, or object that is considered relevant to the interaction between a user and an application, including the user and the applications themselves.)
这个定义为我们揭示了三个关键点:
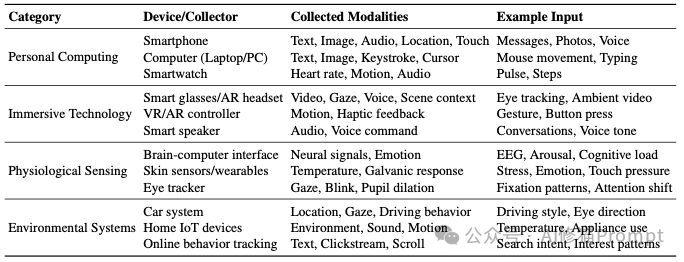
让我们用一个具体的例子来理解。当你在一个AI终端(比如Gemini CLI)里输入“帮我总结一下这个项目里的所有.md文件”时:
read_file、list_directory等工具的定义和描述。所有这些信息加在一起,才构成了AI完成这次交互所需面对的、完整的“上下文”。
论文提出了一个深刻的洞见:上下文工程的本质,是一门关于“熵减”的艺术。
“熵”在信息论中代表着不确定性。人类之间的交流是高效的,因为我们共享着海量的背景知识、文化习俗和情感默契。当朋友对你说“老地方见”,你不需要他提供精确的经纬度。你的大脑会自动利用你们之间的“上下文”(过去的经历、共同的偏好)来消除不确定性(熵减),从而理解“老地方”的具体含义。
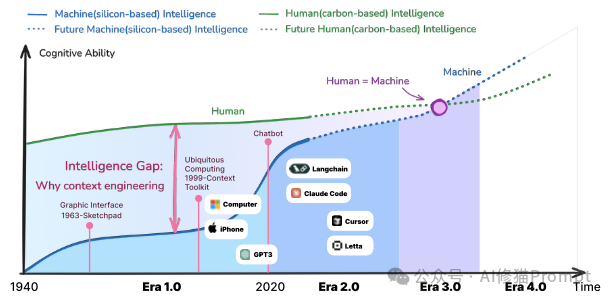
但机器没有这种与生俱来的“常识”。对于AI来说,世界是高熵的、充满不确定性的。因此,上下文工程的核心,就是人类需要付出努力,将高熵(模糊、复杂、非结构化)的人类意图和外部信息,转化为低熵(清晰、简单、结构化)的、机器可以理解和处理的形式。
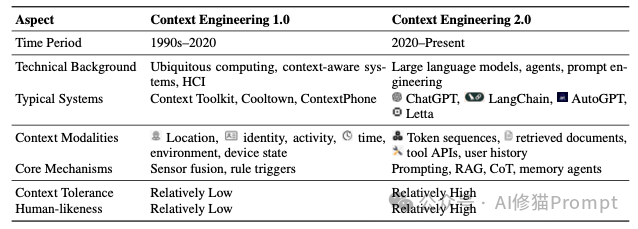
这篇论文构建了一个宏大的历史框架,将这门艺术的演进划分为四个时代,其核心驱动力在于机器智能的飞跃,以及随之而来的人机交互成本的转移。
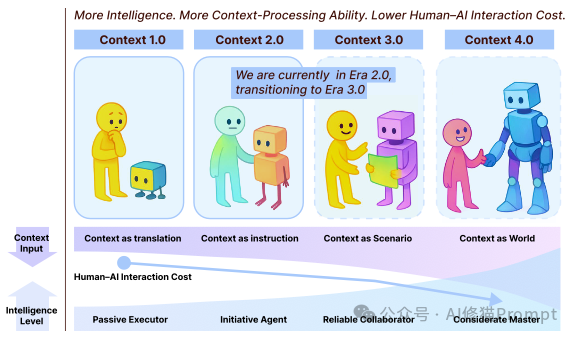
1.0 时代 (1990s-2020):人适应机器。 在这个原始计算时代,机器只能处理菜单、按钮等极其结构化的信息。人类必须将自己的复杂意图“降维”去迎合机器,交互成本几乎完全由人类承担。
如果说LLM是AI的“中央处理器(CPU)”,那么上下文就是它的“内存(RAM)”。但与计算机不同,AI的“内存”是流动的、异构的、且容量有限的。论文的核心之一,就是详细阐述了如何为AI构建一个高效的“第二大脑”来管理这些上下文。
这是将AI从“学徒”变为“助理”最关键的一步。一个只会记录所有原始信息的AI,很快就会被信息的洪流淹没,这被称为“上下文过载”(Context Overload)。“Self-baking”(自我烘焙)就是AI主动将原始、杂乱的情节记忆(比如一次完整的对话历史)提炼、压缩成结构化的语义记忆(比如这次对话的核心结论和关键事实)的过程。
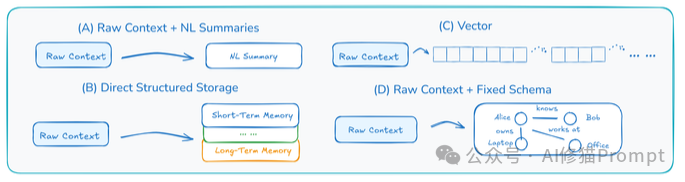
论文总结了四种主流的“烘焙”技术:
在处理复杂任务时,如果所有信息(任务目标、文件内容、工具输出、错误日志)都混在一个上下文窗口里,AI很容易“分心”或“混乱”。“上下文隔离”就是为AI创造一个有序工作环境的关键。
我们当下面临的上下文,正变得越来越“五花八门”。它不再仅仅是文本,而是包含了图像、音频、视频、代码、乃至各种传感器数据的“大杂烩”。一个核心的挑战随之而来:这些不同模态的信息,在结构、信息密度和时间动态上完全不同,AI要如何将它们融合成一个统一、连贯的理解?
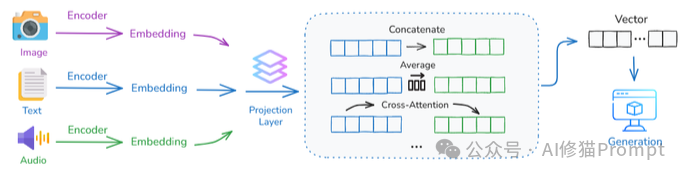
研究者总结了当前(2.0时代)处理这一挑战的三种主流策略:
管理好上下文只是第一步,如何让AI在推理和协作中高效地“使用”这些上下文,是更高阶的艺术。
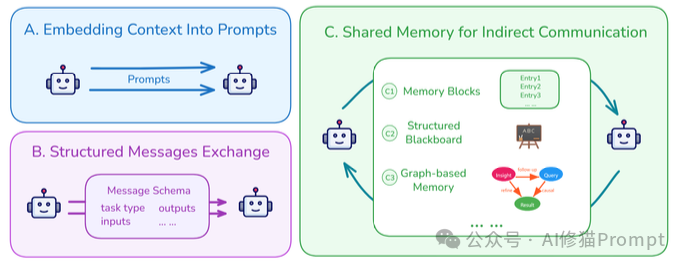
当多个AI智能体协同工作时,它们如何高效、无误地传递信息?这决定了它们是一个“团队”还是一个“乌合之众”。


论文提出了一个至关重要的观点:“在注意力机制之前的注意力”。LLM内部的自注意力机制是被动的,你给它什么它就看什么。而上下文选择,则是在信息进入LLM之前,主动地、智能地筛选出“什么信息值得被关注”。
论文引用了一个惊人的经验观察:当上下文窗口填充超过50%时,AI的编码性能往往会下降。 这雄辩地证明了“上下文并非多多益善”。过多的无关信息会形成噪音,稀释关键信号,干扰模型的判断。
因此,有效的筛选至关重要。除了常见的“语义相似度”搜索,论文更强调了 “逻辑依赖”。系统需要能识别出“当前步骤的输入依赖于上一步的输出”,从而构建一个有逻辑关系的上下文链条,而不是一堆零散的相关片段。
论文最接地气的部分,莫过于总结了大量来自一线的、堪称“黑魔法”的工程实践。这些技巧对于任何AI开发者都极具价值:
todo.md的妙用:在执行长任务时,除了维护一个todo.md文件,还应该让AI在更新文件时,用自然语言“复述”一遍核心目标。这能巧妙地将长期目标“拉回”到模型的近期上下文中,防止它在复杂的执行过程中“跑偏”或“遗忘”。这篇论文对所有AI从业者都提出了一个深刻的挑战和机遇:我们的角色正在发生转变。
过去,我们很多时候是“模型调参师”,关心的是学习率、网络层数等。现在,我们必须成为“AI架构师”或 “上下文架构师”。我们需要将目光从模型本身,扩展到整个信息流和记忆系统。
论文在结尾部分,将讨论提升到了一个令人深思的哲学高度。
它引用马克思的名言“人的本质是其社会关系的总和”,并将其引申到数字时代:一个人的本质,是否正在变成其所有数字上下文的总和?
我们与AI的每一次对话,我们在数字世界留下的每一个痕迹,都在构建一个庞大的、关于“我们是谁”的上下文数据库。研究者提出了一个震撼性的观点:“人类心智或许无法上传,但人类的上下文可以。”
这意味着,这个由你的语言风格、决策模式、知识边界和情感反应构成的“上下文集合”,可以脱离你的物理身体而存在。在你离开后,一个AI可以加载你的“终身上下文”,继续以“你”的方式与世界互动,延续你的“数字存在”(Digital Presence)。
这引出了一系列终极问题:这个“数字化的我”还是“我”吗?为“终身上下文”设计的“语义操作系统”,应该由谁来定义“记忆”和“遗忘”的规则?当AI的智慧大厦完全建立在我们个人和群体的上下文之上时,我们与AI的关系又将走向何方?
《上下文工程2.0》没有给出答案,但它为我们提供了一张至关重要的地图。它冷静地告诉我们,通往更高级别人工智能的道路,并非仅仅是堆叠更多的计算资源和数据,而是要回到那个最古老、也最核心的问题上:我们如何理解世界,以及我们如何让机器也学会理解世界。
而这一切的起点和终点,都在于那看似无形、却无处不在的——上下文。
文章来自于“AI修猫Prompt”,作者 “AI修猫Prompt”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
