# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如果你也在做 RAG 或智能体应用,大概经历过这些瞬间:文档切得太碎,答案失去上下文;切得太大,又召回不准;加了更多提示词,效果可能更不稳定。
Weaviate 团队比我们更早碰到这些问题,这是一家总部在荷兰阿姆斯特丹的向量数据库软件公司,在GitHub上拥有14.9kstar的项目开源数据库(Weaviate OSS),他们每天都在与真实数据和生产流量打交道。久而久之,他们总结了一套完整的方法,并写成《Context Engineering》电子书。

添加官方客服微信 openai178,免费获取《Context Engineering》原文PDF
这本书一共才40页,但信息密度极大,主要研究如何为大语言模型(LLM)设计获取信息、组织信息与保持连贯性的整套系统”。书里把一个“能落地的 AI 应用”拆成六大能力:智能体(Agents)、查询增强(Query Augmentation)、检索(Retrieval)、提示词技巧 (Prompting Techniques)、记忆(Memory)、工具(Tools)。
本文将继昨天上海交大的论文继续深入讲解Context Engineering,让我们就沿着这支团队的视角,一层层把书里的技术路径剥开。

Weaviate团队认为问题的真正核心在于:上下文窗口的挑战。

上下文窗口是模型的“活动工作记忆”,一个有限的空间,用于容纳当前任务的指令和信息。就像一块白板,一旦写满,旧信息就会被擦除。
一个诱人但错误的假设是:“只要上下文窗口足够大,问题就解决了。”
Weaviate 的这份电子书明确地驳斥了这一点。它警告说,一味追求更长的上下文(例如 100 万 token)并不能解决问题,反而会引入全新的、更隐蔽的故障模式。

当上下文变得过长时,模型的性能会开始下降,它们会变得困惑、产生更高的幻觉率,或者干脆停止正常工作。这份电子书总结了上下文过载引发的四种主要“故障模式”:
1.上下文中毒 (Context Poisoning):不正确或幻觉出的信息进入了上下文。由于智能体(Agent)会复用并建立在此基础上,这些错误会持续存在并被放大,导致系统不断重复同样的错误。

2.上下文分心 (Context Distraction):智能体被太多过去的信息(如历史记录、工具输出)所淹没,导致它过度依赖并重复过去的行为,而不是针对新情况进行“新鲜”的推理。

3.上下文混淆 (Context Confusion):不相关的工具或文档挤满了上下文,分散了模型的注意力,导致它使用了错误的工具或遵循了错误的指令。

4.上下文冲突 (Context Clash):上下文中存在相互矛盾的信息,这会误导智能体,使其在冲突的假设之间“卡住”,无法做出决策。

因此,“上下文工程”的真正目标,不是盲目地“塞满”上下文,而是要智能地“管理”它。Weaviate 将这个管理系统拆解为六个协同工作的核心模块。
智能体是整个系统的“决策大脑”,它负责协调其他所有组件,决定“何时”以及“如何”使用信息。

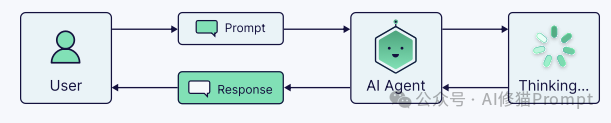
它不是一个固定的“检索-生成”管道,而是一个可以动态决策、保持状态(记忆)、自适应地使用工具,并根据结果修正策略的系统。
其中也分单智能体Single-Agent

以及多智能体Multi-Agent

根据这份电子书的定义,一个真正的 AI 智能体拥有四项核心能力:
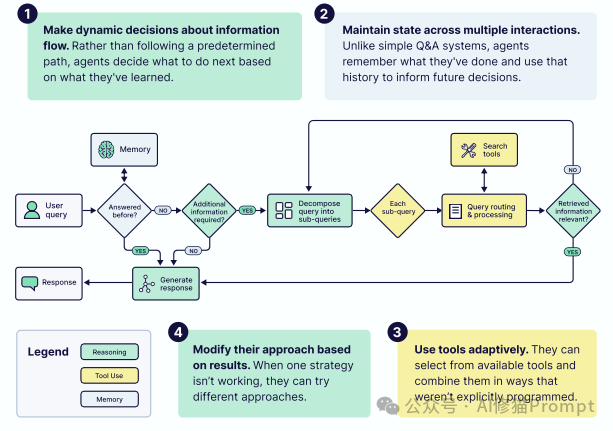
智能体最重要的工作,是执行“上下文卫生” (Context Hygiene)即主动监控和管理其自身上下文的质量。这包括一系列关键的“上下文管理”策略:
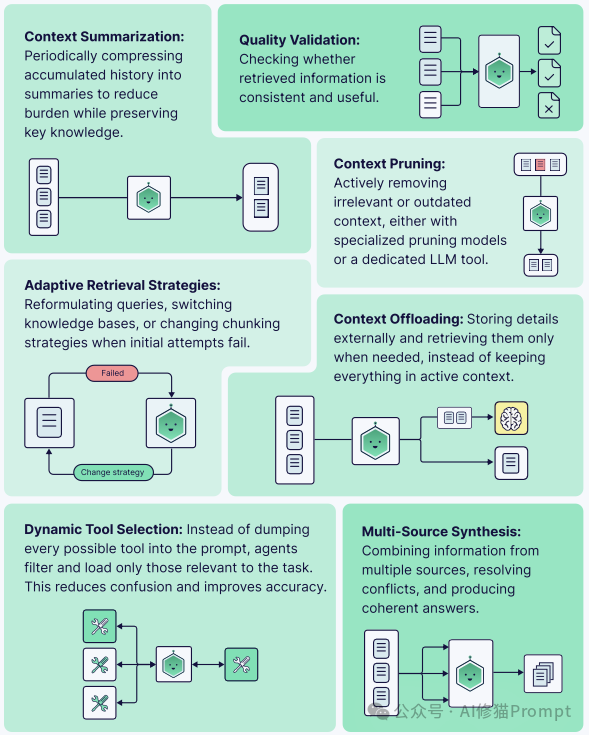
如果缺乏这种主动管理,系统就会立刻陷入前文提到的“上下文中毒”、“分心”和“混淆”等故障模式中。
上下文工程的起点,是理解用户的意图。而用户的请求往往是“混乱的、模糊不清的”。

“查询增强”要解决的就是“垃圾进,垃圾出”的问题。如果系统从一开始就误解了用户的意图,那么后续再强大的检索或提示词也无法弥补。
这份电子书详细介绍了几种从简单到高级的“意图翻译”技术:
1.查询重写 (Query Rewriting) 这是最直接的方法。它将用户模糊的自然语言,转换为精确的、机器可读的意图。
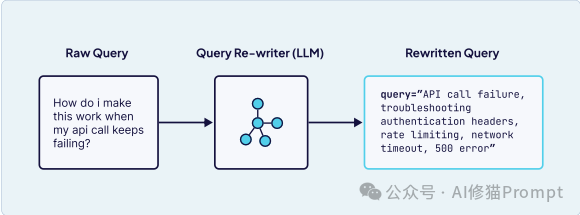
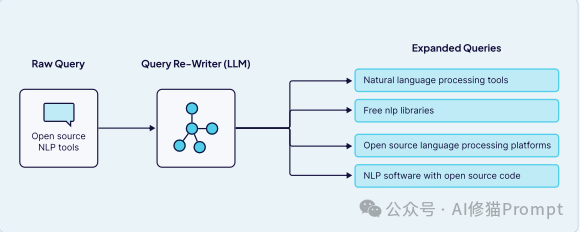
query="API call failure, troubleshooting, authentication headers, rate limiting, network timeout, 500 error" 这个过程包括重组问题、删除无关信息和增强关键词。2.查询扩展 (Query Expansion) 它不是“重写”,而是从一个查询“生成多个”相关查询,以提高检索系统的召回率,尤其适用于模糊或格式不佳的查询。
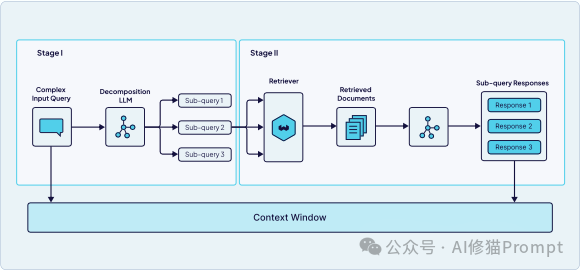
3.查询分解 (Query Decomposition) 用于处理复杂的多方面问题,例如需要从多个来源获取信息或涉及多个概念的问题。它将一个大问题分解为多个可以独立处理的子查询,分别检索后再进行合成。
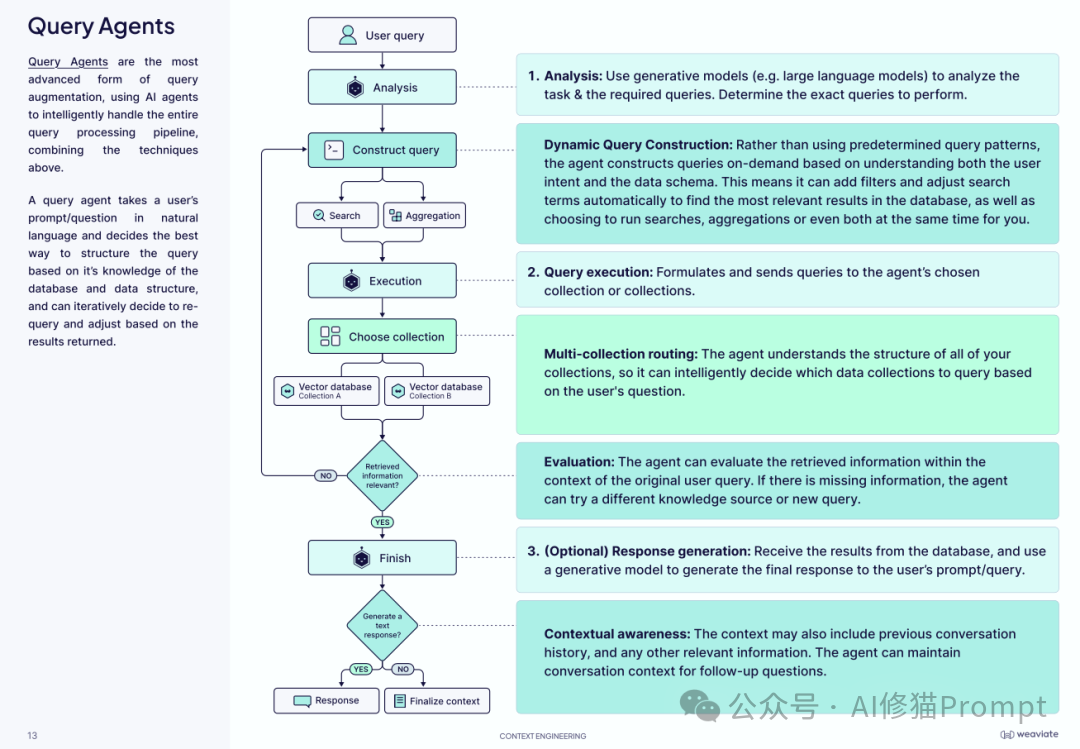
4.查询智能体 (Query Agents) 这是最先进的形式。它是一个专门的 AI 智能体,负责整个查询处理流程。它拥有更高级的能力:
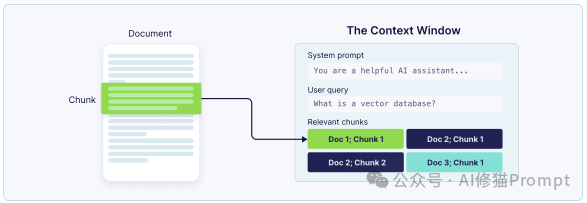
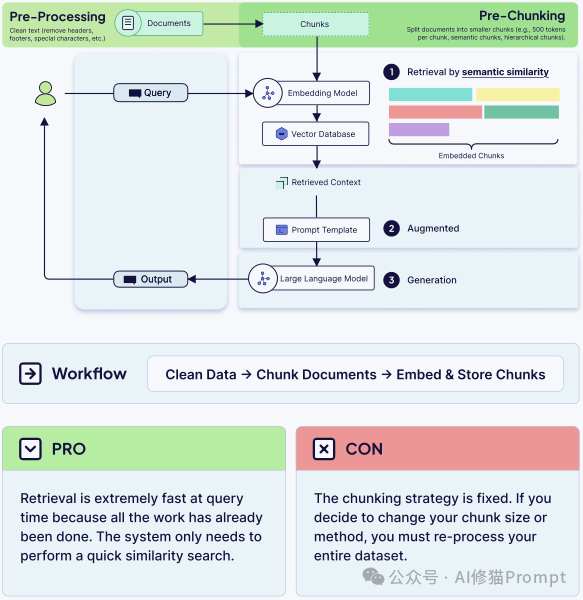
检索(Retrieval)是连接 LLM 与你的特定知识库的“桥梁”。这是实现检索增强生成(RAG)的核心。但原始文档(如 PDF、Word)通常太大,无法直接放入上下文窗口。

因此,RAG 系统中最重要的工程决策就是“分块” (Chunking)——即将大文档分解为更小的、可管理的片段。
分块的成败,在于平衡两个相互冲突的目标:
你的目标是找到“甜蜜点”。你必须避开“精确但信息不完整”(块太小) 和“丰富但无法找到”(块太大,向量嵌入“嘈杂”) 的陷阱。
为了达到这个“甜蜜点”,你需要根据文档类型选择合适的分块策略:
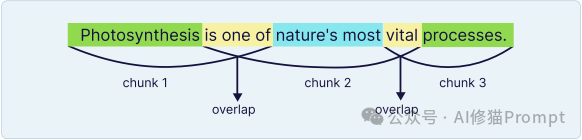
递归 (Recursive):更智能的方法,它会尝试按一个优先的分隔符列表(如:段落、句子、单词)来拆分,以尽可能尊重文档的自然结构。

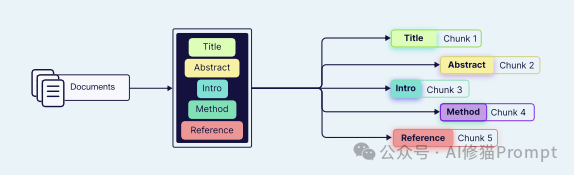
基于文档 (Document-Based):按文档的固有结构(如 Markdown 的标题 #、HTML 的标签 <p>)来拆分。


分层 (Hierarchical):创建多个层级的块(例如:顶层摘要、中层章节、底层段落)。这允许系统从宏观“钻取”到微观。
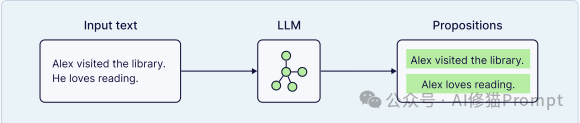
基于 LLM (LLM-Based):使用 LLM 来智能地处理文档,生成语义连贯的块,例如识别逻辑命题或总结章节。
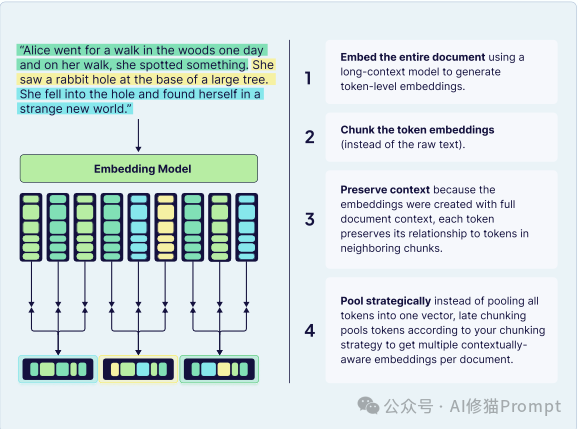
延迟分块 (Late Chunking):这是一种颠覆标准流程的架构模式,它不是先分块再嵌入,而是先嵌入整个文档 ,使用长上下文模型生成具有完整上下文的“Token 级嵌入”。然后,它才将这些上下文丰富的“Token 嵌入”(而非原始文本)分割成块。
智能体分块 (Agentic Chunking):这是最高级的方法。一个 AI 智能体动态分析文档的结构和内容,并为该特定文档选择最佳的分块策略(或策略组合)。
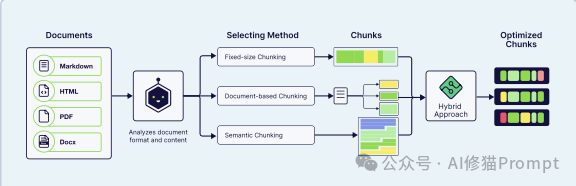
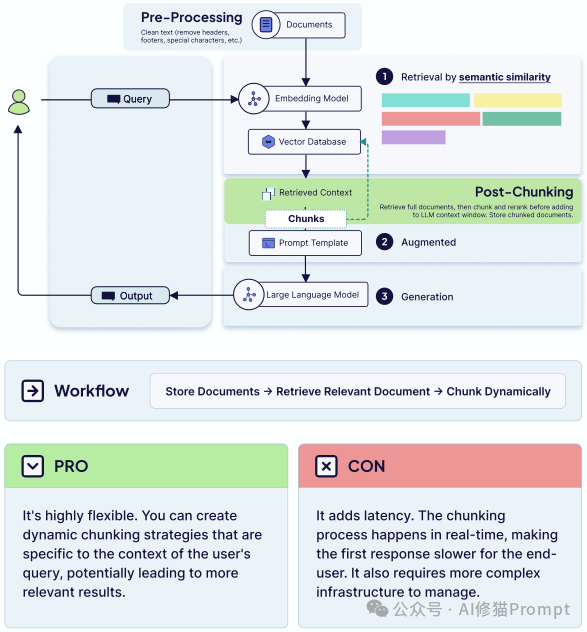
电子书还提出了一个关键的架构决策:何时进行分块。
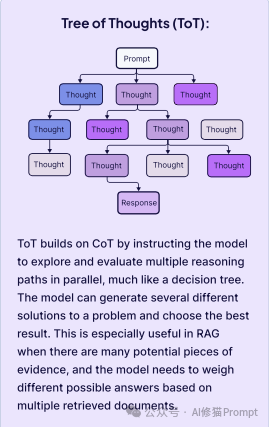
如果说“上下文工程”是关于提供信息,那么“提示词工程”就是关于下达指令。它是引导模型推理的技巧。

电子书强调了几种对 RAG 和智能体系统至关重要的技术:

对于与外部世界交互的智能体而言,最重要的是“为工具使用编写提示词”。LLM 能否正确使用你提供的工具,几乎完全取决于你如何描述这个工具。一个有效的工具描述必须:

get_current_weather 而不是 weather_data)。city (string), date (string, YYYY-MM-DD))。如果说 LLM 是 CPU,那么上下文窗口就是 RAM(内存)。但 RAM 是易失的、有限的。为了让 AI 拥有“历史感”和“学习能力”,我们必须为其构建一个更持久、更智能的记忆系统。

Weaviate 提出了一个优雅的“记忆分层架构”:
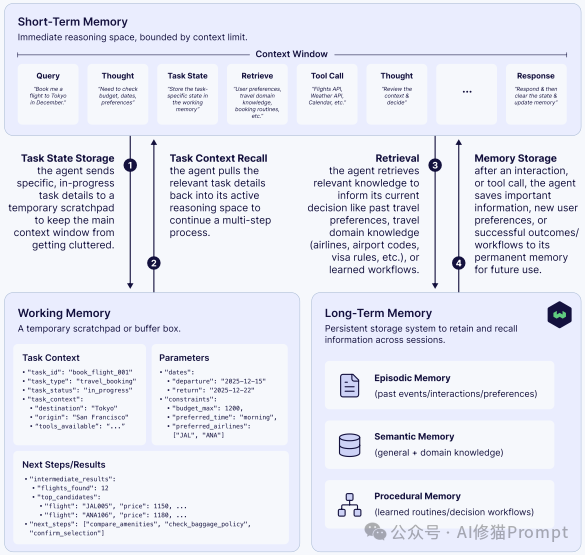
仅仅拥有记忆层是不够的;糟糕的记忆实践会导致“错误传播”。电子书强调了四个关键的管理原则:
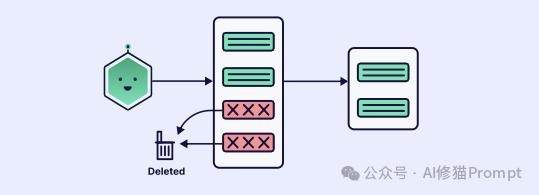
1.有选择地存储 (Be Selective About What You Store):不是每次交互都值得永久保存。必须实施过滤标准来评估信息的质量和相关性。一个坏信息会导致“上下文污染”。一种方法是让 LLM 在存储前进行“反思”(reflect) 并分配一个重要性得分。
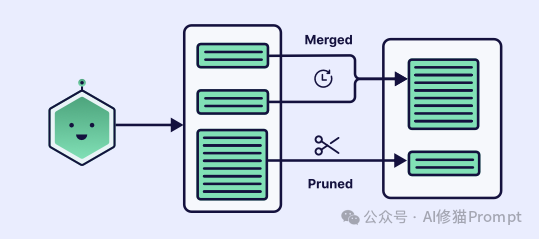
2.修剪和提炼你的记忆 (Prune and Refine Your Memories):记忆需要定期维护。定期扫描长期存储,以删除重复条目、合并相关信息或丢弃过时的事实。可以使用“新近度”和“检索频率”等指标来决定是否删除。
3.掌握检索的艺术 (Master the Art of Retrieval):有效的记忆不在于你存储了多少,而在于你能在正确的时间检索到正确的信息。这需要使用重排序 (Reranking)(让 LLM 重新排序检索结果的相关性)和迭代检索(多步骤优化搜索查询)等高级技术。
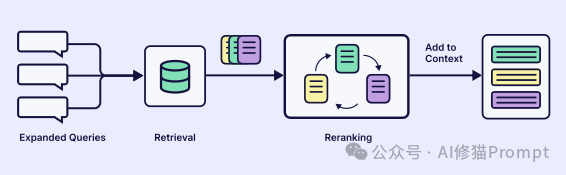
4.根据任务定制架构 (Tailor the Architecture to the Task):没有万能的记忆方案。客服机器人需要强大的情景记忆来回忆用户历史,而财务分析机器人则需要强大的语义记忆来填充领域知识。
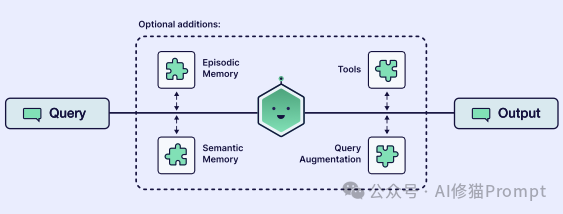
如果说记忆给了智能体“自我感”,那么工具就给了它“超能力”。工具将 LLM 从一个“文本处理器”转变为一个可以“采取行动”并与现实世界交互的执行者。

这得益于“功能调用”(Function Calling)的突破。LLM 不再是猜测答案,而是可以输出结构化的 JSON,来请求调用一个外部函数(例如 search_flights(city, date))并传入参数。
给予智能体一个工具很简单,但让它可靠、安全、有效地使用这个工具,才是真正的难题。这就是“编排”的艺术。
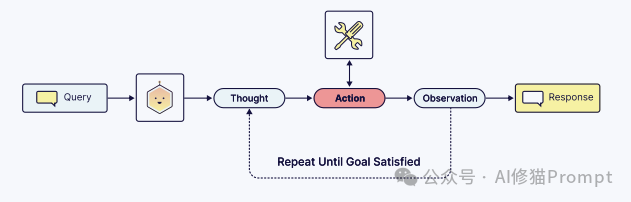
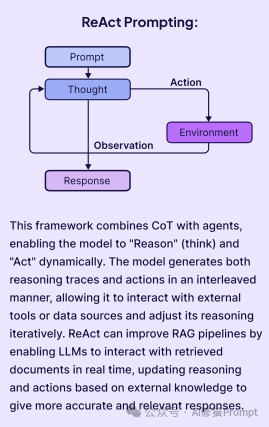
电子书将这个编排流程,总结为一个强大的反馈循环:“思考-行动-观察”循环 (Thought-Action-Observation cycle)。
以电子书中一个名为 Glowe 的护肤应用为例:
1.思考 (Thought):用户提问“我这种肤质最适合哪种洁面乳?”智能体进行推理,决定需要使用 product_agent 工具。
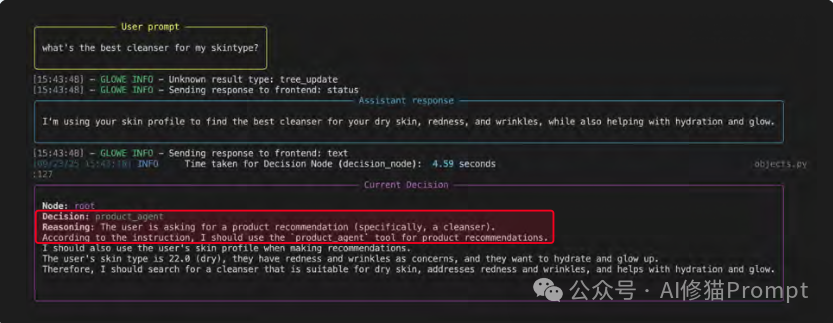
2.行动 (Action):智能体从用户查询和记忆中提取并格式化工具所需的参数。它制定了搜索查询 “cleanser for dry skin and hydration”。
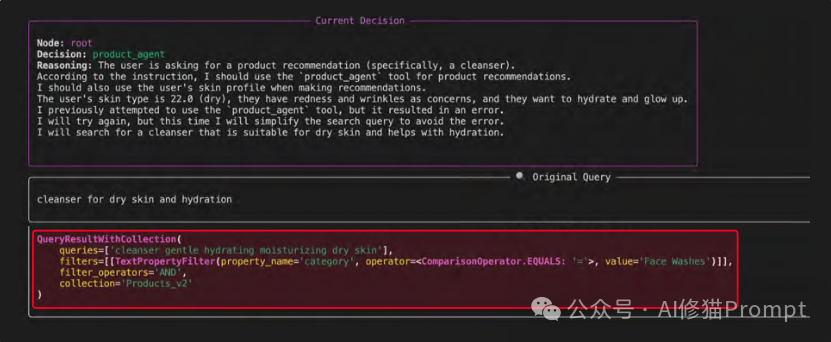
3.观察 (Observation):工具执行后,其输出结果(即产品列表)被反馈回智能体的上下文窗口。智能体反思这个结果,并决定下一步行动(即为用户生成最终的推荐答案)。
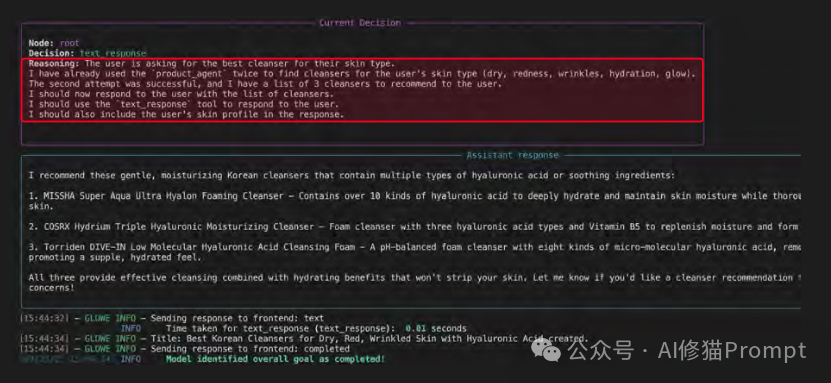
电子书还展示了一个更高级的“自愈” (self-healing) 案例:当智能体第一次调用工具因参数错误而失败时,它在“观察”到错误后,在下一次“思考”中自动修正了参数,并成功完成了任务。
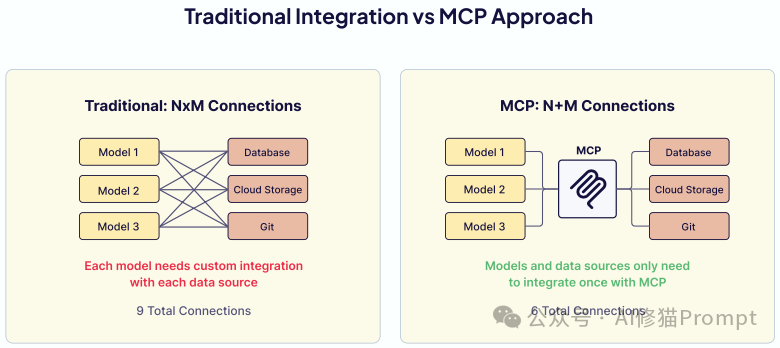
当前工具的使用方式(每个应用为每个工具编写自定义集成)造成了一个“碎片化的生态系统”。
电子书介绍了工具使用的下一个前沿:模型上下文协议 (Model Context Protocol, MCP)。
把系统想象成一座城市:提示词是路标,检索是道路,记忆是档案馆,工具是公共设施,而智能体就是城市管理者。Weaviate《Context Engineering》这本书教的不是某条捷径,而是城市的规划法。 我们从“RAG切得太碎答不全、切得太大找不准、提示词越写越乱”出发,也以它作结:
当检索、记忆与工具在智能体手里形成闭环,系统的稳定与可维护性就回来了。下一次再遇到类似问题,先把信息流理顺,别急着加token。你会发现:变强的不是模型,而是你的工程。
添加官方客服微信 openai178,免费获取《Context Engineering》原文PDF
文章来自于“AI修猫Prompt”,作者 “AI修猫Prompt”。



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
