# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型一个token一个token生成,效率太低怎么办?
微信AI联手清华大学,提出了一个新的解法:
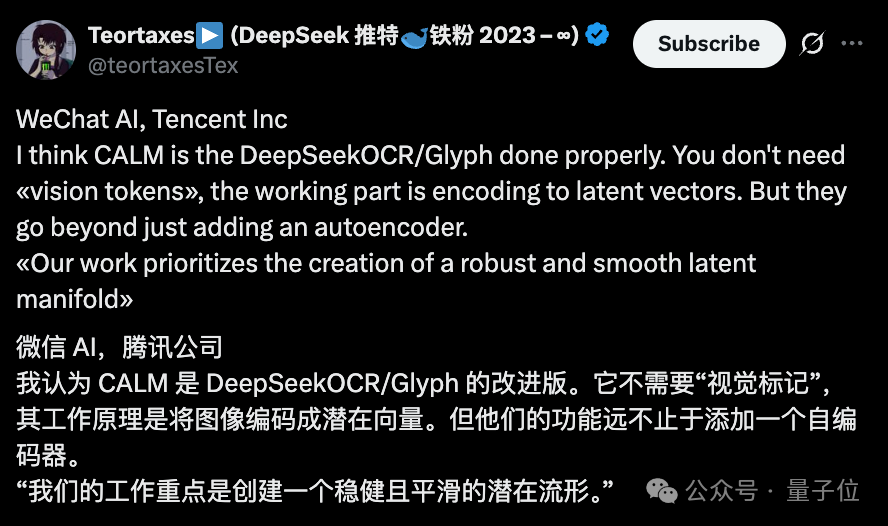
一个token能装下的信息太少,不如把它们打包成连续向量,让大模型从预测下一个token,转变为预测下一个向量。

研究团队给这种新范式取名CALM(连续自回归语言模型)。
实验表明,将K个词元压缩成一个连续向量,可以将语言模型建模为一系列连续向量,生成步骤减少至原来的1/K。
这样一来,模型就能在平衡性能和计算成本时,实现更高的性价比。
有网友认为,这种方法看上去越来越接近大脑实际处理上下文的方式。

还有网友提出,CALM像是DeepSeekOCR/Glyph的改进版。
研究人员指出,预测下一个token的现有模型范式,一开始是因为基于字符级运行的模型计算量太大而被提出的。
也就是说,方法背后的关键思想是:提升每个文本单元的信息密度,能够缩短序列长度并显著提升模型效率。
进一步挖掘本质,可以总结出一条提升大模型生成效率的有效途径:持续提升每个预测单元的语义带宽。
问题在于,如果想让一个token装更多的信息,就得把词表做得超大,反而会让计算量和存储成本爆炸。
微信AI和清华大学团队想了个办法:把多个token打包成一个连续向量,让模型每次处理一个向量,而不是一个token。这样一来,比如一个序列的长度为T,将K个token打包为1个向量,序列长度就会缩短为T/K。
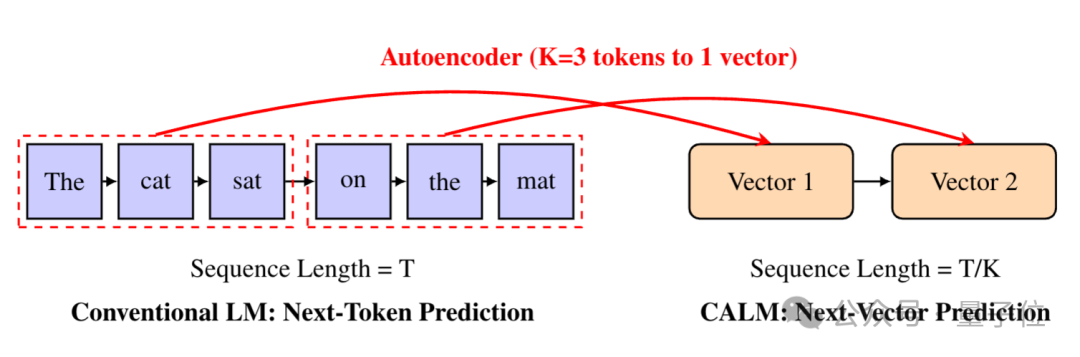
他们设计了一个高保真自编码器,能将K个token压缩成一个连续向量,并能以超过99.9%的准确率从中重构原始token。
不过,从处理token向处理向量转变,还面临着一个重大挑战:
由于不存在有限词汇表,模型将无法借助标准的softmax层,对所有可能结果计算出明确的概率分布。
这也就意味着,需要为此开发全新的建模工具。
于是,研究团队提出了CALM——一套完整的、无需依赖概率似然的框架。
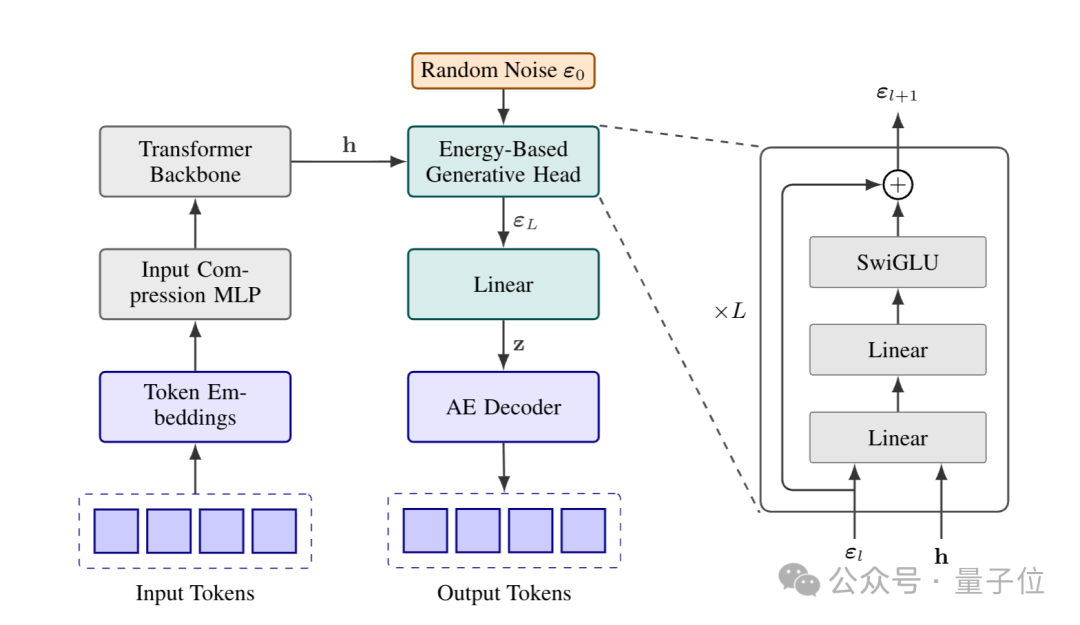
△CALM框架
训练方面,CALM采用“能量损失”来教模型学习连续向量。
不用算概率,而是改用“能量分数”来判断模型生成的向量好不好。
具体来说,为了实现连续向量生成,研究人员采用轻量级生成头作为模型的核心输出组件。该生成头以最后一个隐藏状态为条件,来生成输出向量。
同时,为避免迭代式采样过程造成新的推理瓶颈,研究人员引入了Energy Transformer。
Energy Transformer专为连续向量的高效单步生成设计,无需迭代,仅需1步计算即可输出连续向量。
能量损失是CALM训练Energy Transformer时用的损失函数,不依赖概率计算,而是用“距离”和“多样性约束”两个维度判断向量质量——既让生成的向量贴近真实值,又避免模型只会生成一种向量。
不算概率了,困惑度(Perplexity)这个评估指标也就不好用了。
为此,研究人员提出了BrierLM,一种基于布里尔分数的新型语言模型评估指标。
只需从模型中抽取样本,就能无偏地估算出BrierLM值。
实验证明,BrierLM值和困惑度高度相关,能保证对模型能力的公平比较。
现在流行的大语言模型是通过温度采样来实现可控生成的,但这同样依赖于概率分布。
CALM提出了无似然温度采样,这一算法基于拒绝采样,通过调整样本的接受概率来实现温度控制。

研究人员通过实验验证,CALM在平衡性能和计算成本时更有性价比。
在标准语言建模任务上,CALM-M(K=4,参数量371M)在性能上与Transformer-S(281M参数)相当,但训练浮点运算数(FLOPs)减少了44%,推理FLOPs减少了34%。
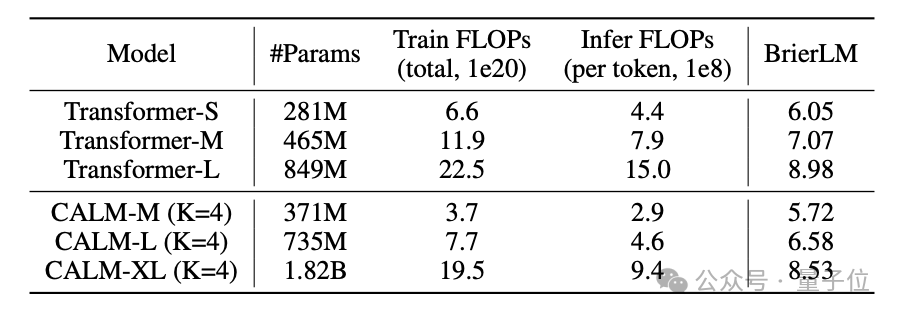
模型越大,CALM的优势越明显。并且随着语义带宽K的增加,CALM的性能-效率比也会更优。
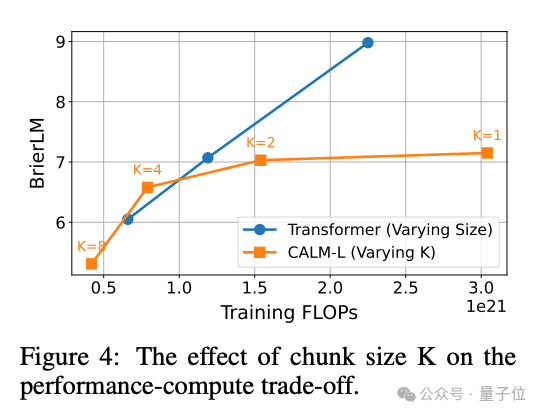
不过,研究人员也提到,压缩的token数K太多时,反而会导致性能下降,可能需要更换更大的模型。
论文地址:
https://arxiv.org/abs/2510.27688
文章来自于“量子位”,作者 “鱼羊”。



【开源免费】茴香豆是一个能够让AI接入第三方的免费开源项目。更可贵的是,即使你不会编程,也可以根据它的教程,将AI接入到微信或者飞书当中使用。
项目地址:https://github.com/InternLM/HuixiangDou
在线使用:https://openxlab.org.cn/apps/detail/tpoisonooo/huixiangdou-web
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
