# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
现在AI都懂文物懂历史了。
一项来自北京大学的最新研究引发关注:他们推出了全球首个面向古希腊陶罐的3D视觉问答数据集——VaseVQA-3D,并配套推出了专用视觉语言模型VaseVLM。
这意味着,AI正在从“识图机器”迈向“文化考古Agent”。

传统视觉语言模型(VLM)如GPT-4V、Gemini等,擅长描述日常图像,在开放域视觉理解方面效果显著,但在面对文化遗产类复杂对象时——它们几乎“一脸茫然”。受限于训练数据的领域覆盖和语义建模能力,其对复杂纹饰、器形及文化背景的理解仍存在明显不足。
为什么?因为缺乏高质量、结构化的专业数据。
此次,北大牵头团队带来了突破性解决方案。
以往的视觉语言模型(VLM)如CLIP、LLaVA、GPT-4V等,虽然能识别日常图片,却在文化遗产这类专业领域失灵。
北大团队指出:“AI能认猫狗,却认不出陶罐的时代、风格与技法。”
于是他们构建了一个庞大的新基座VaseVQA-3D。


△VaseVQA-3D中的陶罐3D模型与问答示例:每个模型都能被AI“旋转、观察、回答”
从现有资源里找了3万多张古希腊陶器的2D照片,先通过:
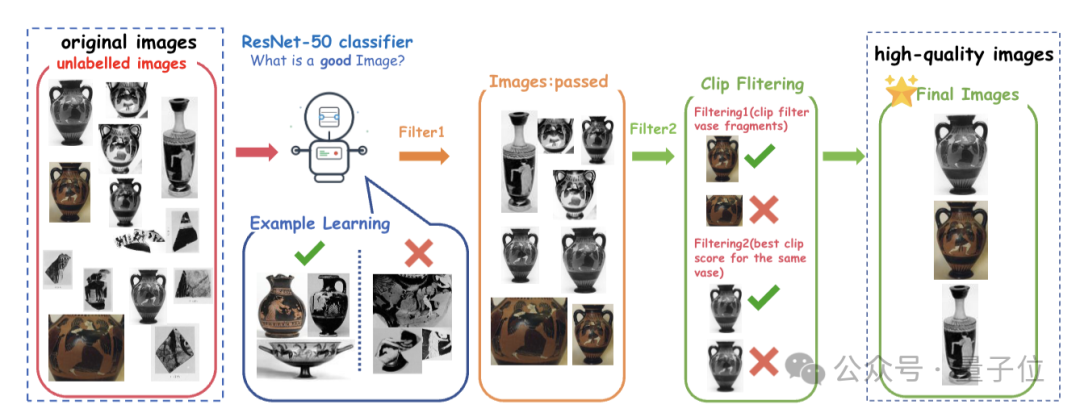
再用TripoSG技术把这些2D图转成664个高保真的GLB模型(像真的陶器一样能看前后上下);
最后还通过GPT-4o生成问答与增强描述,配了4460组「问题-答案」(比如 “这个陶器的制作工艺是什么?”“是黑绘工艺”),甚至给每个3D模型写了详细说明。
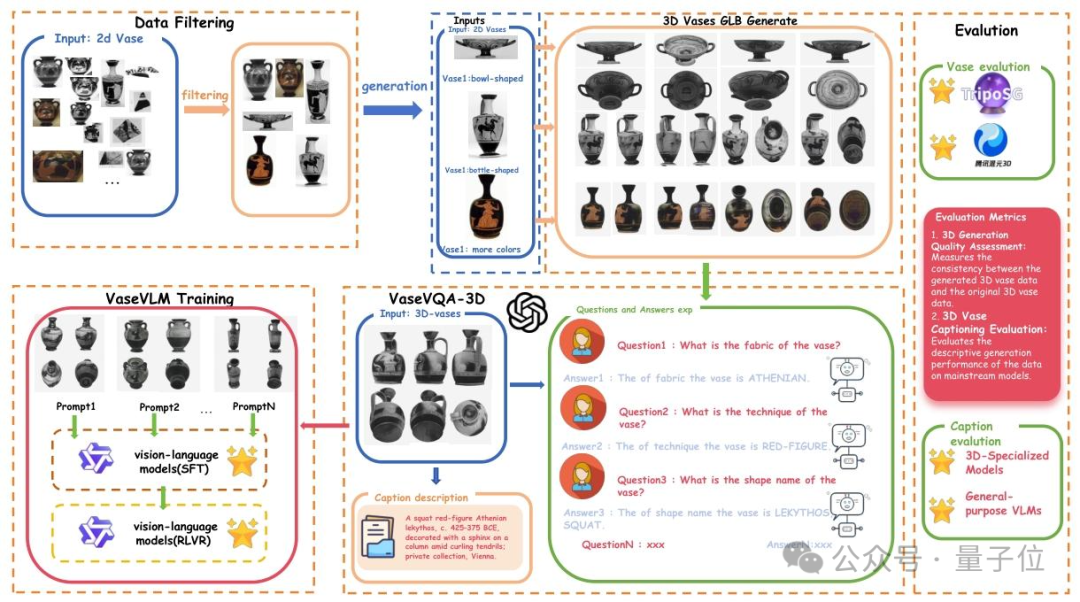
为了保证3D模型质量,专门挑了24个高质量3D陶器当标准样板,用来检验生成的3D模型好不好。
总结下来就是:
有了数据,团队进一步训练了专用模型 VaseVLM。
以Qwen2.5-VL为基底,通过两阶段强化:
这种“可验证奖励机制”让模型的回答更专业、更贴近学术标准。
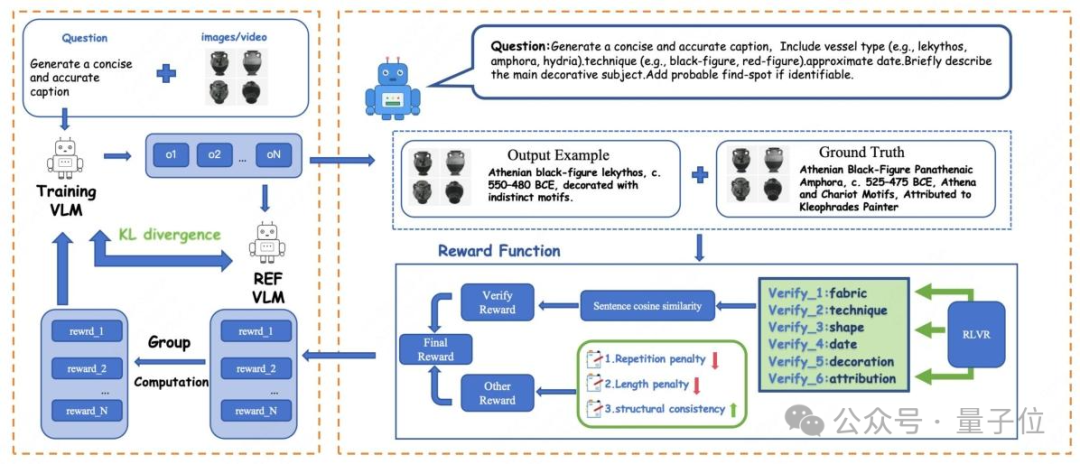
△RLVR奖励机制:AI像考古学家一样分维度分析陶罐特征
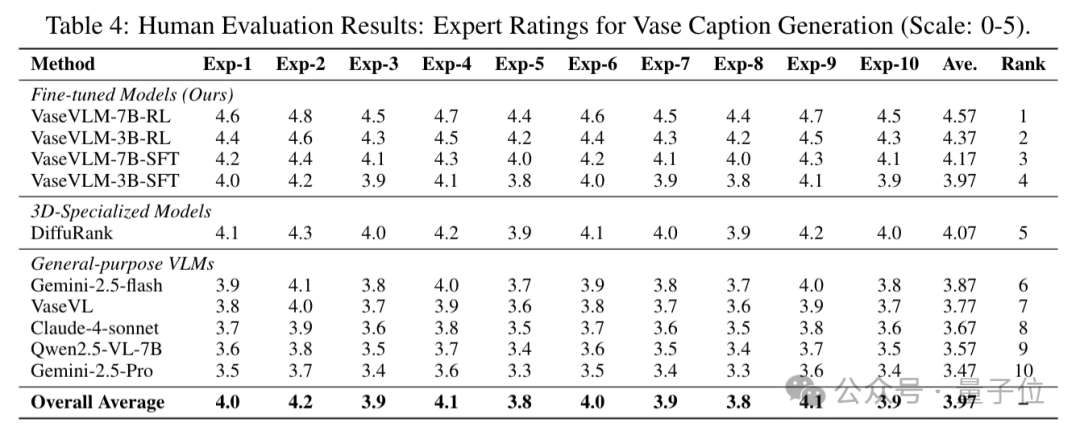
在多项Vase-3D视觉问答任务上,VaseVLM的表现大幅超越现有模型。相比最强基线模型,VaseVLM在R@1准确率提升12.8%;词汇相似度提升 6.6%;专家人工评分平均达4.57/5(10位考古专家评分)。
VaseVLM生成的描述更自然、学术准确,显著优于通用大模型。
未来,该项目计划拓展到更多文化遗产领域,并建立更完善的数字遗产展示形式,为数字考古提供全新技术路径。
论文原文:https://arxiv.org/abs/2510.04479
官方网站: https://aigeeksgroup.github.io/VaseVQA-3D
代码开源: https://github.com/AIGeeksGroup/VaseVQA-3D
数据集:https://huggingface.co/datasets/AIGeeksGroup/VaseVQA-3D
文章来自于微信公众号 “量子位”,作者 “量子位”



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
