
李飞飞学生发起国际具身人类数据标准,光轮智能成唯一参与中国企业
李飞飞学生发起国际具身人类数据标准,光轮智能成唯一参与中国企业2009年,李飞飞团队正式发布ImageNet。
来自主题: AI资讯
10520 点击 2026-07-24 11:34
 搜索
搜索
2009年,李飞飞团队正式发布ImageNet。

国防科技大学虚拟现实与视觉计算团队(SAW Lab)联合先进制导与控制技术国家级重点实验室等推出面向航拍几何 3D 视觉的统一大规模数据集与评测基准 「AirZoo」。
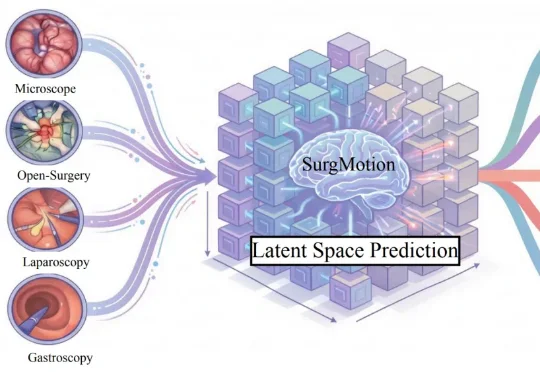
手术 AI 正在从 “单帧感知” 迈向 “全流程视频理解” 的全新时代!近日,由中国科学院香港创新研究院人工智能与机器人创新中心领衔,发布了全球首个十亿级参数、最大规模数据集练成的手术视频原生基础模型 ——SurgMotion!
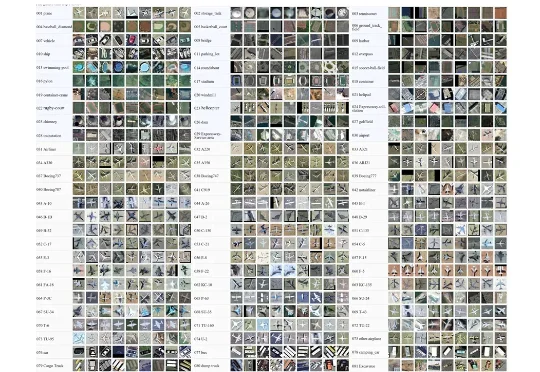
近日,北京航空航天大学史振威教授和邹征夏教授团队发布了一个面向通用遥感目标检测的大规模数据集与基础模型框架 ——LEVIRDet。该研究构建了目前最大规模、最全面的遥感目标检测数据集 LEVIRDet-159,并在此基础上提出了面向通用遥感检测的基础模型 LEVIRDetNet。

看《堡垒之夜》的游戏录像,也能训练AI?没错,一家靠着海量游戏录像训练AI的公司General Intuition,刚刚完成3.2亿美元(约合人民币21.77亿元)融资。General Intuition公开披露的融资总额已达4.54亿美元,估值23亿美元。

DeNovoSWE是一个用于训练代码智能体从零生成完整仓库的数据集,包含4818个真实任务实例。它通过结构化文档和严格验证机制,帮助智能体掌握复杂系统构建能力,而不仅仅是修复代码。这为代码智能体迈向更高阶的软件工程任务提供了关键支持。
本研究由快手科技语言大模型团队完成,核心作者吕民轩、梅铁桦、杜坦隆等。快手科技与中国科学院大学联合提出 GoLongRL,一套完全开源的长上下文强化学习后训练方案,包含 23K 样本 RLVR 数据集

硬氪获悉,具身智能企业穹彻智能(Noematrix)近日完成新一轮数亿元融资,本轮融资由无锡数据集团领投,投资方包括上海交通大学AI未来基金(创业基金)、上海创之智科技有限公司(上海创智学院全资子公司)、一村资本等。
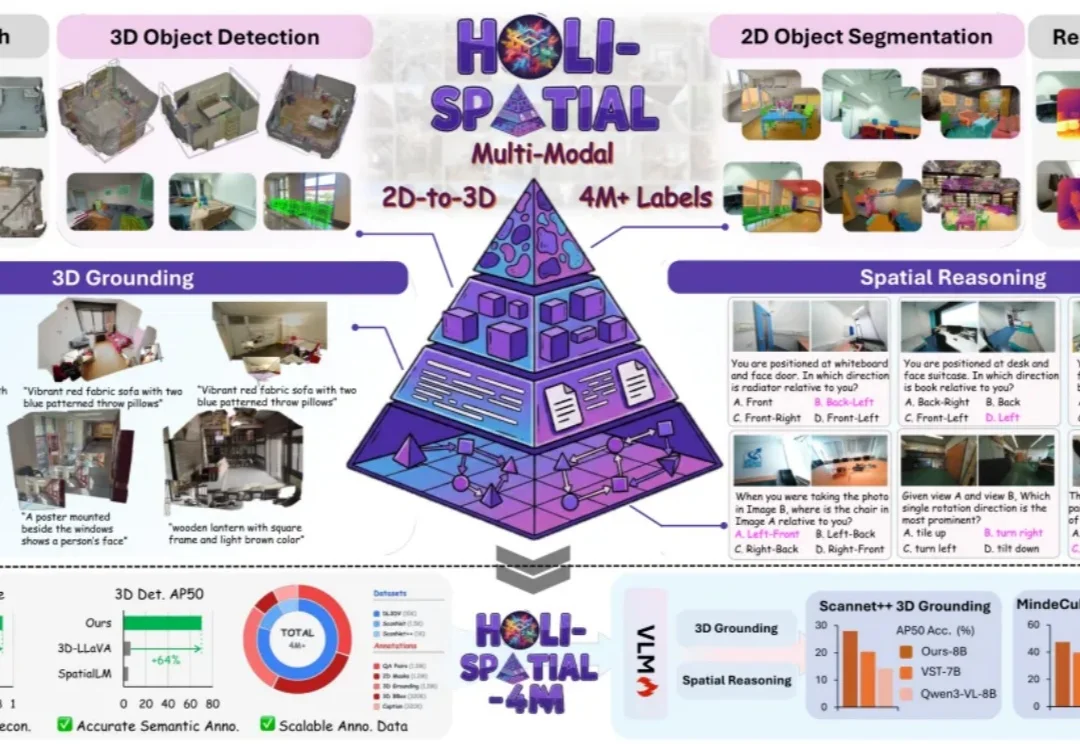
从原始视频出发,无需人工介入,自动生成 3D 重建、深度、2D mask、3D 框、实例描述、3D grounding 和空间问答。Holi-Spatial 试图把「空间智能」的数据生产,推进到自动化、可扩展的新阶段。

北大彭宇新团队提出「美学照片重构」新任务,从摄影教学视频中自动构建数据集AesRecon,并开发两阶段模型AesFormer,通过优化构图、视角与人物姿态,提升照片的美感与艺术表现力。