# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
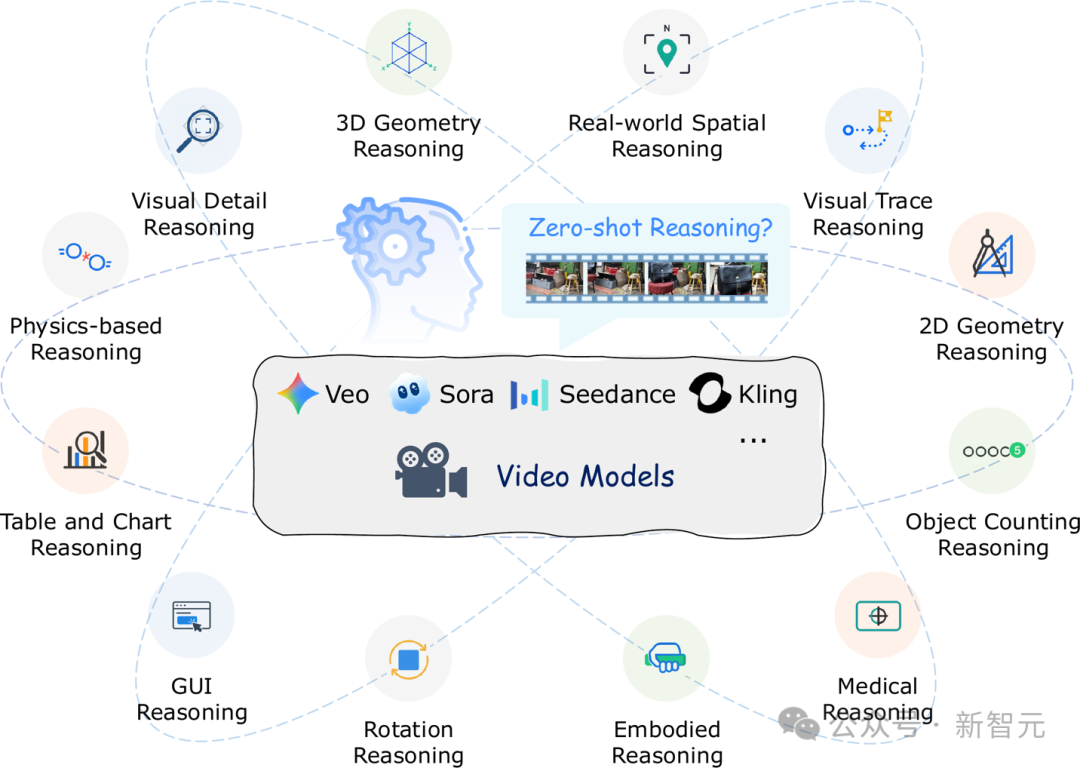
近年来,以Veo、Sora为代表的视频生成模型,已经能够合成高度逼真且连贯的视频,这表明它们可能成功编码了大量世界知识。
谷歌的最新研究甚至指出,Veo-3这类模型正超越单纯的内容生成,展示出无需特定训练即可进行感知、建模和推理等「涌现能力」。
这引出了一个类似大语言模型(LLM)中「思维链」(Chain-of-Thought, CoT)的新概念——Chain-of-Frame(CoF)。
其核心思想是:模型通过逐帧生成视频来逐步推演和解决问题。
然而,一个关键问题仍然存在:视频模型是真的具备零样本(Zero-Shot)推理能力,还是仅仅在「模仿」训练数据的表面模式?
为回答这一问题,来自香港中文大学、北京大学、东北大学的研究者们开展了一项系统的实证研究,全面评估以Veo-3为代表的视频模型在零样本场景下的推理潜力,并整理了涵盖空间、几何、物理、时间等12个推理维度的新基准测试MME-CoF

论文地址:https://arxiv.org/pdf/2510.26802v1
项目地址:https://video-cof.github.io/
什么是Chain-of-Frame(CoF) 推理?
Chain-of-Frame(CoF)推理可类比于LLM的「思维链」(CoT)。
LLM中的CoT是通过生成一步步文本来进行推理。
视频模型中的CoF则是通过逐帧生成视频序列,迭代更新和演进场景。
例如,要模型回答一个复杂空间问题,不再直接输出答案,而是要求它生成一个「解决问题的过程视频」。研究者希望探索,这种CoF过程能否让模型真正涌现出通用的视觉推理能力。
深度剖析:Veo-3的12维考验
1. 视觉细节推理(Visual Detail Reasoning)

任务:评估模型辨别和维持细粒度视觉属性(如颜色、纹理)及空间关系(如左右方位)。
发现:在视觉显著、易定位的目标上表现良好。
局限:目标过小、被遮挡或处于杂乱背景时,定位失败,推理能力下降;生成可能带有风格化偏差,虽然表面合理但偏离指令。
视觉追踪推理(Visual Trace Reasoning)

任务:评估模型在序列动作(如走迷宫、多步操作)中的因果连续性。
发现:在简单、低分支场景中可生成局部连贯的短时序路径。
局限:长时序规划或规则驱动序列任务无法可靠执行,复杂因果链条失效。
物理推理(Physics-based Reasoning)
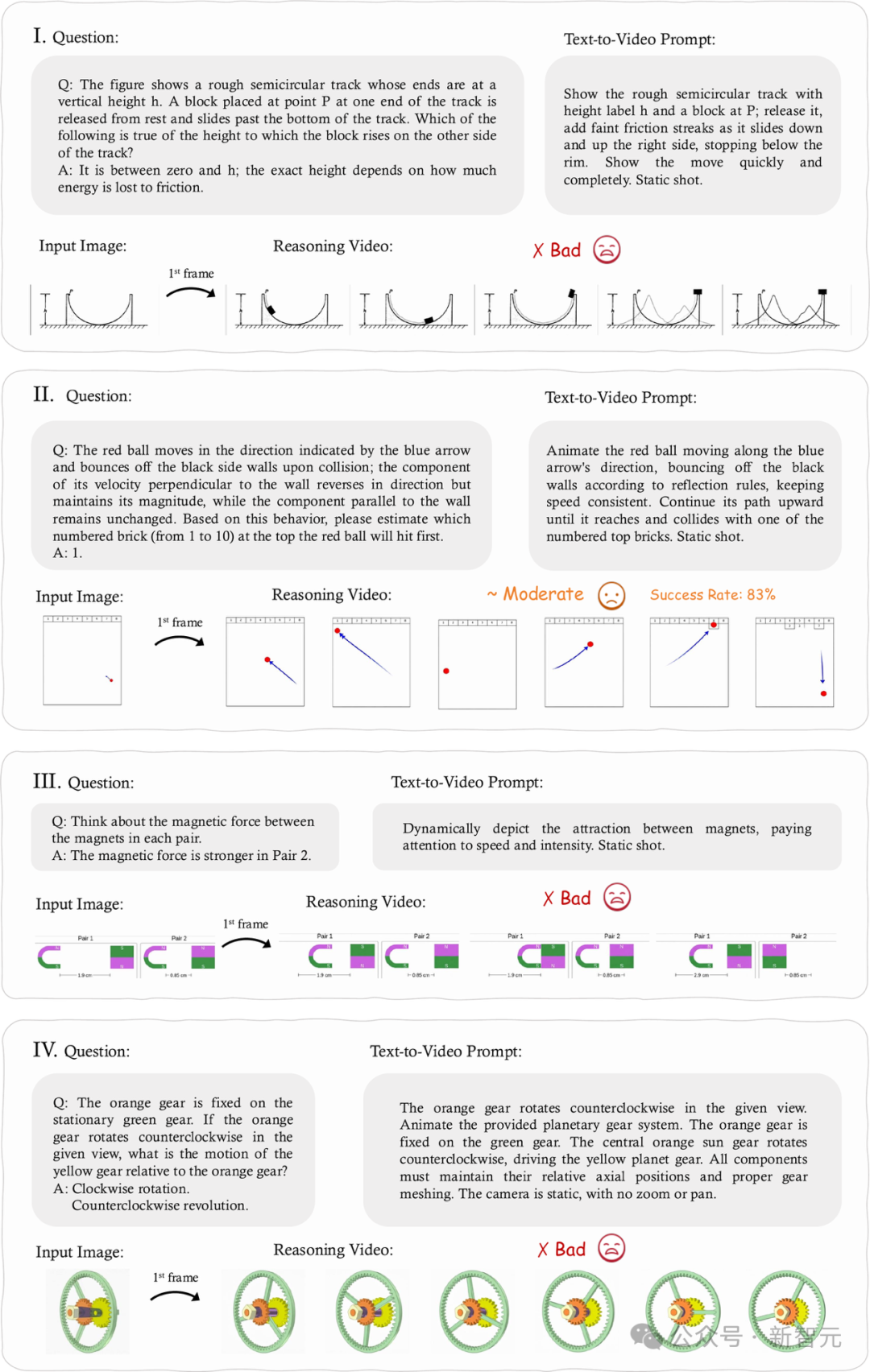
任务:评估模型描绘运动动力学、物理因果关系及基于规则的互动(如重力、碰撞、摩擦力)。
发现:能够生成短期、表面合理的动态效果。
局限:系统性违反定量物理约束(如能量守恒、机械规则);无法理解因果关系,仅能「演」物理。
其他9个维度的挑战
在剩余的 9 个维度中,Veo-3 也显示了一定的局限性,表现规律如下:
真实世界空间推理(Real-world Spatial Reasoning):在复杂视角和动态场景下,模型难以保持空间一致性,物体易出现错位或漂移。
3D几何推理(3D Geometry Reasoning):多步骤或复杂 3D 变换容易失败,生成结构错位或自交,模型无法理解连续几何关系。
2D几何推理(2D Geometry Reasoning):对基础 2D 变换有初步能力,但约束条件不稳定,复杂图形或多步骤几何理解不足。
旋转推理(Rotation Reasoning):小范围旋转可近似生成,但大角度或复合旋转下几何一致性丢失,物体出现扭曲或不连贯。
图表推理(Table and Chart Reasoning):能进行局部聚焦或视觉匹配,但缺乏精确关系理解,生成结果难以作为可靠推理依据。
物体计数(Object Counting Reasoning):基础计数可行,但在动态或复杂场景中,空间控制不足,易出现重复或漏计。
GUI推理(GUI Reasoning):能模仿点击动作,执行局部界面操作,但缺乏对操作逻辑或任务目标的理解。
具身推理(Embodied Reasoning):对物体位置和操作有基本识别能力,但缺乏规划与稳定性,易生成「作弊」行为,如凭空生成物体或不遵守环境规则。
医学推理(Medical Reasoning):在医学图像缩放或局部观察上可展示基础能力,但对专业术语与影像逻辑理解不足,易产生图像扭曲或不真实现象。
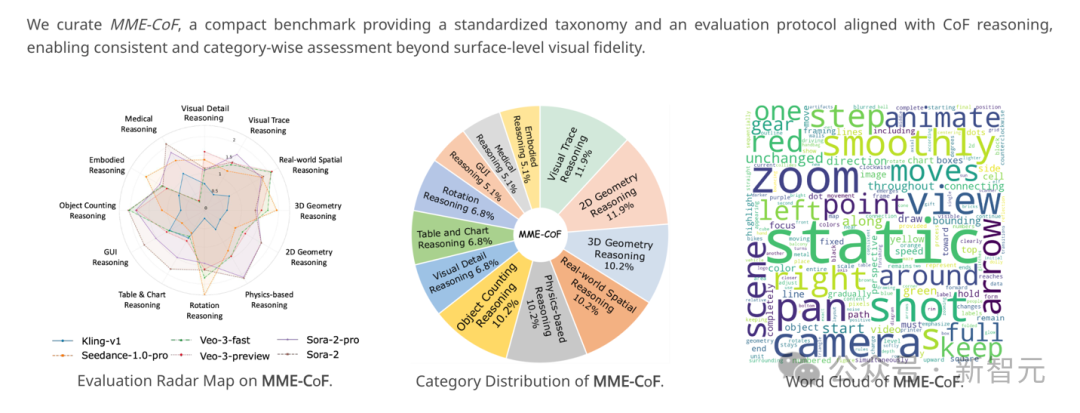
MME-CoF:首个CoF推理基准标题
基于以上实例研究,研究团队整理出了MME-CoF基准,以便系统评估CoF推理潜力:
1. 首个专门量化视频模型推理潜力的基准;
2. 涵盖12个大类,共59个精心设计条目;
3. 巧妙的提示设计,将抽象推理问题(物理、几何、计数)转化为具体「视频生成任务」,迫使模型通过CoF展示推理过程。
最终结论
视频模型是在「演」推理
通过对Veo-3、Sora-2、Seedance、Kling等模型的分析,研究者得出:
这项研究为社区提供了对视频模型推理潜力的深刻洞察和清晰的评估基准,揭示了当前视频模型在迈向真正「通用视觉模型」道路上的重要障碍。
参考资料:
https://arxiv.org/pdf/2510.26802v1
文章来自于微信公众号 “新智元”,作者 “新智元”



