# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
我们长期把LLM当成能独闯难关的“单兵”,在很多任务上,这确实有效。
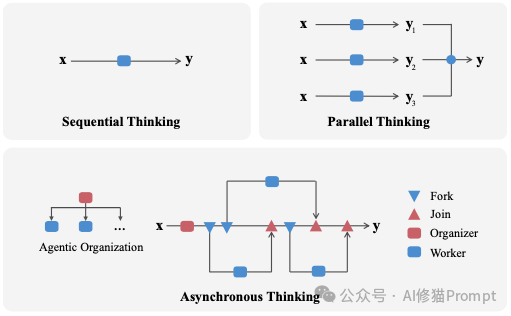
可一旦问题牵涉多步依赖、分支探索和中途验证,顺序思考 (Sequential Thinking)的推理链条就开始吃力,甚至崩溃,链条越长,越慢、越脆弱;为补救而采取的人海战术“并行思考 (Parallel Thinking)”让模型针对同一个问题,独立地生成多个不同的思考路径,最后通过“少数服从多数”的投票方式选出最终答案,又彼此不沟通,常常被最慢的一条拖住整体效率,成本也直线上升。所以与其继续在“更长的单链”和“更多的平行样本”之间取舍,不如换个思路!能不能让模型像一个公司,小型组织那样工作?

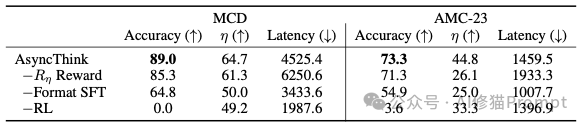
微软研究院的一篇论文给出了具体做法。他们提出“智能体组织(Agentic Organization)”的设想,并给出一套可执行的文本级动作协议,把“并发”写进推理过程,同一个模型既能当“组织者”,也能当“工作者”。组织者在需要时分派子任务(Fork),让多个工作者各自推进;当关键节点到来,再取回并合并这些中间结论(Join);必要时继续分派新的方向,直到收尾作答(Answer)。这不是额外再堆几个模型,也不需要改网络结构,全靠规范化的文本标签把推理拆解、调度和同步起来。实证结果表明:在数学等基准上,这种“组织化思考”不仅提升了正确率,还把关键路径时延显著拉短,约下降 28%,也就是在更短的“必经串行部分”里得到更好的答案。
如果说过去的两种做法分别代表“埋头拉长一条链”和“各走各的路最后投票”,那么这项工作要解决的是第三件事:教会模型规划、分工、同步与合并。从这一点开始,LLM 不再只是一个会推理的个体,而是一个会组织推理的系统。
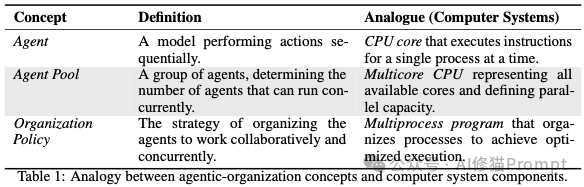
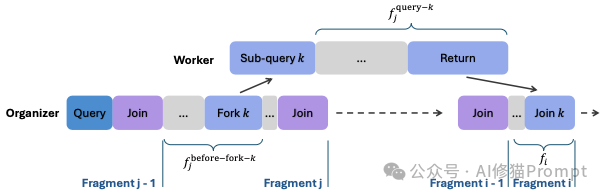
AsyncThink范式的核心,是一种精妙绝伦的 “组织者-工作者 (Organizer-Worker)” 协议。它彻底颠覆了AI作为单一思考实体的传统设定,让同一个语言模型在解决问题时,能够动态地扮演两种截然不同的角色:
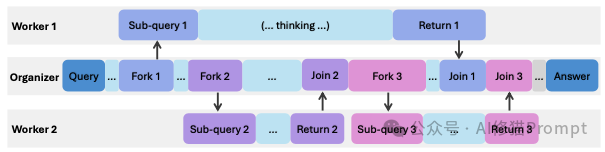
Fork (分叉/派工): 当“组织者”识别出一个可以独立处理的子任务时,它会立即使用 <FORK-i> 指令,将这个任务连同清晰的描述,分配给一个空闲的“工作者”去执行。这里的 i 是任务的唯一编号,方便后续追踪。Join (合并/验收): 当“组织者”的思考主线需要某个子任务的结果作为输入时,它会发出 <JOIN-i> 指令。此时,它会暂停自己的思考,耐心等待并接收指定编号 i 的“工作者”返回的成果,然后将这些新知识融入自己的思考上下文中,继续推进。<RETURN> 标签返回给“组织者”。这个协议的真正威力,体现在其 “异步 (Asynchronous)” 的特性上。这与我们现实世界中最高效的团队管理模式如出一辙:
想象一位项目经理(组织者)正在规划一个复杂的软件项目。他首先将“数据库设计”这个任务 Fork 给了工程师A。派发完任务后,他无需原地等待,而是立刻转向下一个模块,将“前端UI开发”任务 Fork 给了工程师B。与此同时,工程师A和B并行开工。项目经理则可以继续思考项目的整体架构,或者 Fork 第三个任务给工程师C。只有当他需要数据库的最终表结构来设计后端API时,他才会执行 Join 操作,调取工程师A的工作成果。
这种异步、并行的协作模式,相比于“顺序思考”(经理自己干所有活)和“并行思考”(三个工程师各自从头到尾开发整个软件,最后投票哪个版本好),其效率和灵活性实现了指数级的提升。它允许AI动态地构建一个可并发执行的“思考结构图”,在广度探索和深度挖掘之间取得了完美的平衡。
拥有了“组织者-工作者”的先进架构,下一个核心问题便是:如何将一个只懂得遵循指令的普通AI,训练成一个懂得审时度势、知人善任、高效规划的“金牌管理者”?这并非易事,因为“组织能力”是一种高度抽象的智慧,无法通过简单的规则来定义。
为此,论文设计了一套巧妙的、分为两个阶段的“管理者养成计划”。
这个阶段的目标,是让模型先学会“公司的规章制度和工作黑话”,也就是 Fork 和 Join 这套协议的语法和基本用法。
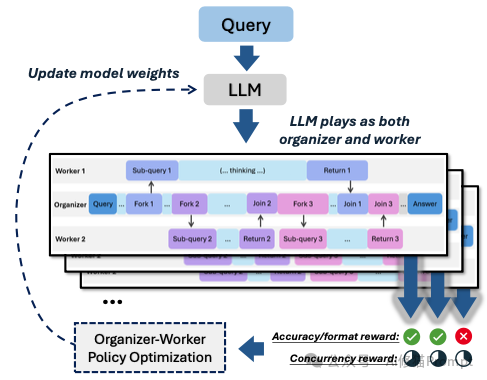
Fork-Join 结构的管理式思考痕迹。模型无从学习。这是将“实习生”锤炼成“金牌管理者”的关键阶段。模型被推向真实的战场,通过不断的试错和反思,来学习“管理”这门艺术。其背后的核心驱动力,是一套精心设计的奖励与惩罚机制 (Reward System)。
在每一次尝试解决问题后,模型生成的整个“组织思考”轨迹都会被系统进行评估,并给予一个综合分数。这个分数由三部分构成:
Fork 新任务导致“编制溢出”;或者 Join 一个根本不存在的任务。一旦出现这类低级错误,就会被扣除“合规罚款”。这确保了组织运行的基本秩序。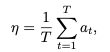
如果组织者能巧妙地安排任务,让多个工作者在大部分时间里都处于并行工作的状态,那么它就会获得高额的“效率奖”。
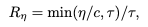
反之,如果它的指挥导致工作者们轮流上班、大部分时间都在空闲等待,这个奖励就会很低。

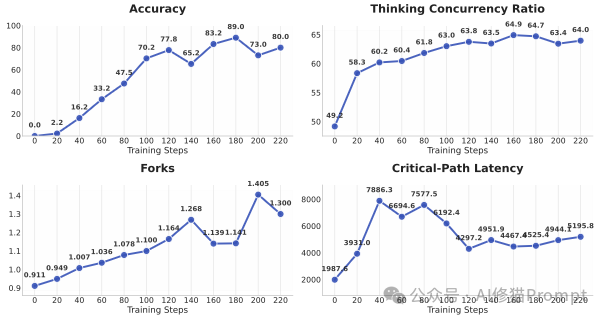
通过最大化最终的综合奖励,模型被迫进行深刻的“管理学反思”。它会逐渐领悟到:仅仅得出正确答案是不够的,还必须用最有效率、最合理的方式来组织团队。简单的任务或许不需要分工,复杂的任务则需要精心设计并行路径。在一次次“复盘”中,模型内在的“组织策略”不断进化,最终从一个生硬的指令发布者,蜕变为一个真正懂得运筹帷幄的智慧核心。
理论的优雅,终需实践的检验。研究者们在三个难度各异的“战场”上,对经过完整训练的AsyncThink模型进行了严格的实战考核。
这是一个对思维广度要求极高的任务。模型需要用给定的几个数字,通过加减乘除,找出四种不同的运算组合,使其结果等于一个目标数。
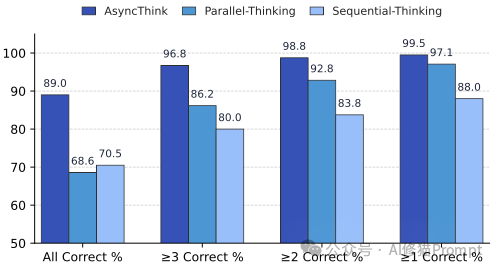
Fork 一个任务给工作者,指令其“专门寻找基于乘法和除法的组合”;与此同时,组织者自己则专注于探索加减法。当工作者返回结果后,组织者会分析已有的解法,并根据“战况” Fork 出新的、更具针对性的探索任务,比如“尝试使用数字X和Y进行组合”。这种动态、迭代的探索,极大地提升了寻找多解的覆盖率和效率。最终,AsyncThink在所有评价指标上都遥遥领先。这是对逻辑深度和严谨性要求极高的奥赛级数学竞赛题。
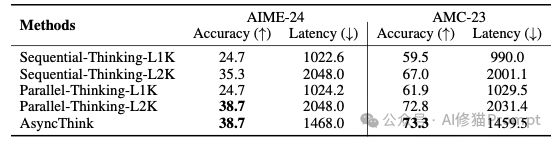
这是整个研究中最高光、最令人震撼的部分。它旨在回答一个终极问题:AsyncThink学到的,究竟是解决特定任务的“套路”,还是一种通用的、可迁移的“组织智慧”?
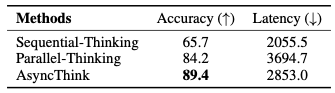
Fork-Join 组织能力。它的“组织者”会分析棋盘,然后 Fork 任务给工作者,比如“请填充第一行,并检查是否合法”。通过这种方式,它将复杂的数独问题分解、并行处理、验证,最终的求解准确率竟然也超越了为数独任务专门训练的传统模型。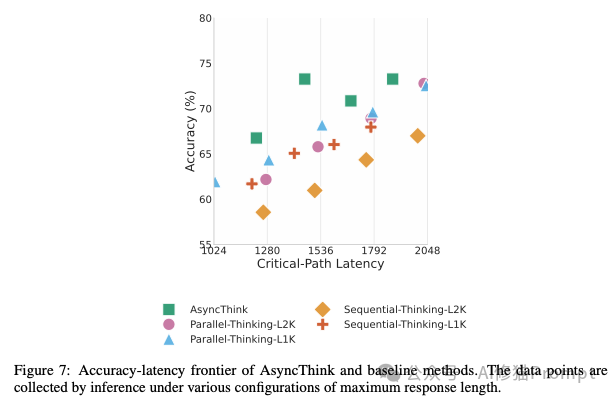
这项研究如同一声惊雷,为当前以“模型越大、数据越多就越好”为主流的AI发展范式,开辟了一个全新的、充满想象力的维度。它对每一位AI领域的从业者和关注者,都带来了深刻的启示。
1. 重新定义“模型能力”: 模型的强大,不仅在于其“个体知识”的渊博,更在于其“组织智能”的高低。未来,评价一个AI系统优劣的标准,或许将不再仅仅是参数量的大小,更要看它能否高效地进行任务分解、并行协作和结果整合。
2. AI开发的新思路: 对于AI工程师而言,这意味着我们的工作重点可能需要从“如何更好地微调一个单体模型”,转向“如何设计和训练一个高效的、由多个智能体组成的协作系统”。AsyncThink提供了一个即插即用的“组织框架”,未来的应用开发者可以直接利用这套协议,来构建能够解决特定领域复杂问题的“AI专家团队”。
3. 通往更鲁棒、更可信AI的阶梯: 一个懂得组织的系统,天然比一个单体系统更具鲁棒性。在AsyncThink的框架下,如果一个“工作者”在执行任务时出错或陷入死循环,“组织者”可以及时发现问题,或中止该任务,或将其重新分配给另一个工作者。这种内在的容错和纠错机制,是构建真正可靠、可信赖AI系统的关键。
AsyncThink的研究,让我们得以一窥人工智能未来的壮丽图景。在这个图景中,AI不再是孤岛式的“超级大脑”,而是演化成一个庞大、高效、动态演进的“超级有机体”。
论文的研究者们在文末进一步畅想了更为激动人心的可能性:
Fork 出自己的“子工作者”团队,形成一个可以无限嵌套的、灵活的层级化组织,以应对极端复杂的系统性问题。Fork 给人类,而人类管理者也可以 Fork 海量的数据处理和计算任务给AI“工作者”军团。从模仿到理解,从计算到推理,从个体到组织。人工智能的进化之路,正踏入一个全新的纪元。AsyncThink或许只是这场伟大变革的序曲,但它所奏响的“协同”与“组织”的主旋律,无疑将成为定义下一代人工智能的核心乐章。我们要的,或许不再是一个更聪明的“爱因斯坦”,而是一个懂得如何领导无数“爱因斯坦”协同工作的“超级组织者”。而那个时代,正悄然拉开序幕。
文章来自于“AI修猫Prompt”,作者 “AI修猫Prompt”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
