# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在计算机科学领域, CSRankings 曾被视为一次划时代的改进。它摒弃了早期诸如 USNews 那样依赖调查问卷的主观排名体系,转而以论文发表数量这一客观指标来评估各大学的科研实力。
然而,理想往往伴随着隐忧——当论文发表数量成为唯一的标准,学术评价异化为一场比拼篇数的竞赛。论文越多,排名越高;但数量的增长,真的代表质量的提升吗?近年来,有越来越多的个人和机构视论文为数字游戏,动辄一年发表数十篇论文并广为宣传。然而,发表的论文数量真的可以代表个人或者机构的学术影响力吗?
科研领域多年以来一直希望评价学术影响力。因此,我们有了影响因子,有了 Google Scholar。然而,只数论文引用的数量带来了其它的问题,例如,论文中经常会有很多并非对当前工作很重要的引用。
同时,有些类型的论文会有较高的引用数量,但是并不一定代表其学术价值。比如,综述文章经常被引用,但并不总意味着此综述是本论文的必要基石。或许某个前置工作(算法,模型, codebase, etc)才是本论文能完成的前提。
一个关键问题是:如何抛开发表数量和引用数量,来真正衡量科研的「质量」?
我们认为答案可能来自两个方向:
其实,真正在每一个领域中的研究者,写论文的时候已经在他们的论文里或明确或暗含地揭示了哪些论文是领域中真正重要的文献。
但这种「重要」往往是双重的:它既包含作者在写作时主观认可和强调的前置工作(比如综述帮助了信息获取),也包含那些在技术上或思想上奠定了客观基石的工作。前者蕴含在写作中,而后者更是要结合技术背景来捕捉。
然而,这些信息隐含在海量的论文中,光靠人力是无法读完所有文献,将这些信息提取出来的。
基于这一思路,俄勒冈州立大学 (Oregon State University) 和加州大学圣 CRUZ 分校 (University of California Santa Cruz) 的学者构建了一个全新的学术排名系统:让大语言模型读出学者们心中对论文影响力的评价。
网页:https://impactrank.org/
学者们选用了 DeepSeek-R1-Distill-Llama-8B 大语言模型,让它阅读来自 2020-2025 年顶级 AI 会议的论文,并提出一个简单的问题:
「这篇论文认为对它最重要的 5 篇参考文献是什么?」
换句话说,让 AI 来帮我们阅读参考文献,找出哪些研究是当今学术论文背后的灵魂。
通过反复分析数万篇论文,我们就能描绘出整个 AI 研究版图中,哪些作者、哪些论文、哪些机构最常被视为创新的根基。
接下来,学者将所有论文找到其在 DBLP 中匹配的论文和作者,防止 AI 产生幻觉生成不存在的参考文献。然后再将这些「Top 5 关键参考文献」的作者映射回其所在的大学。
每当一篇论文被另一篇新论文选为「Top 5 关键参考文献」,该论文的作者及其机构便会获得相应的学术影响力积分。为了公平起见,积分会平均的分配给每个作者。
最终,学者们得到了一个不以数量取胜,而以影响力见长的排名体系。
它奖励那些激发新发现、奠定研究基石、推动学科前行的研究机构。
这种方式,让我们看到的不再是「谁发得最多」,而是——
「哪些论文真正的影响了领域的发展。」
检视 CSRanking 和 Research Impact Ranking,我们发现,他们有非常大的区别。如 Computer Vision 领域:
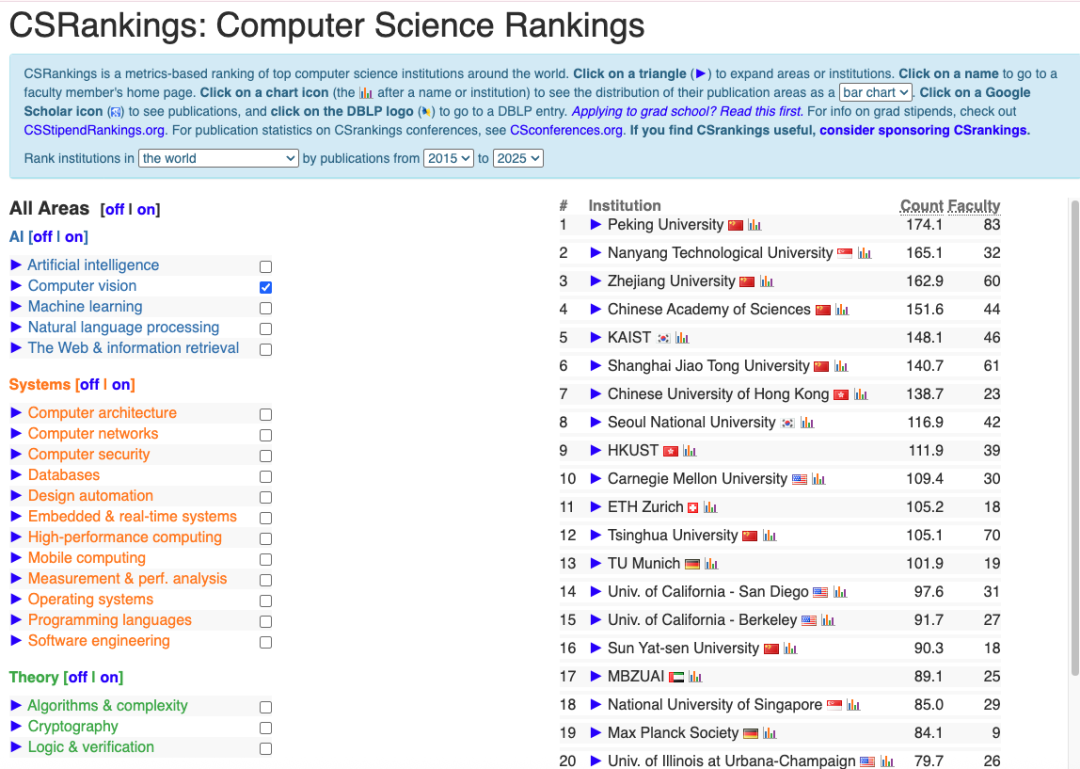
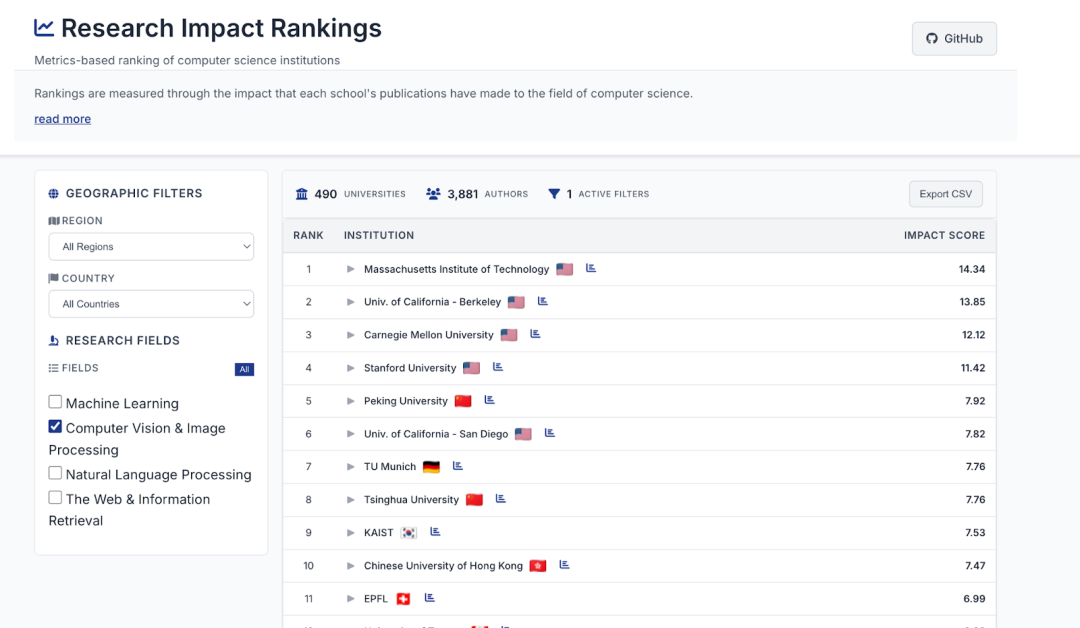
AI Research Impact Rankings:
自然语言处理领域:
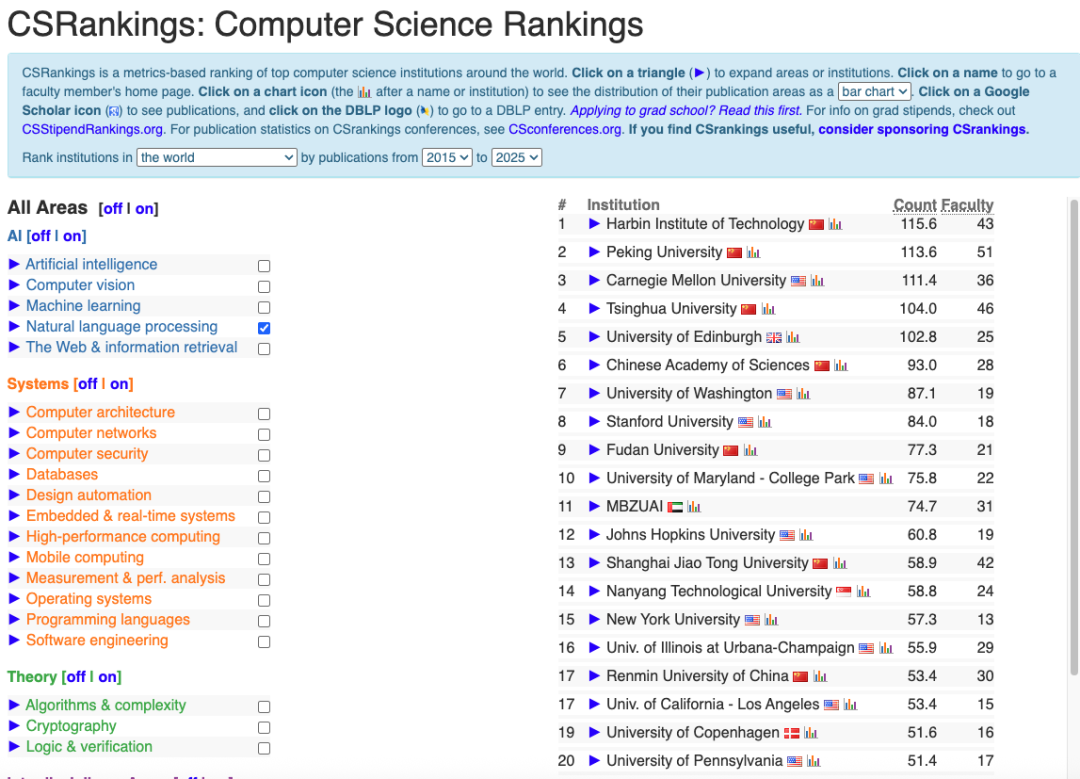
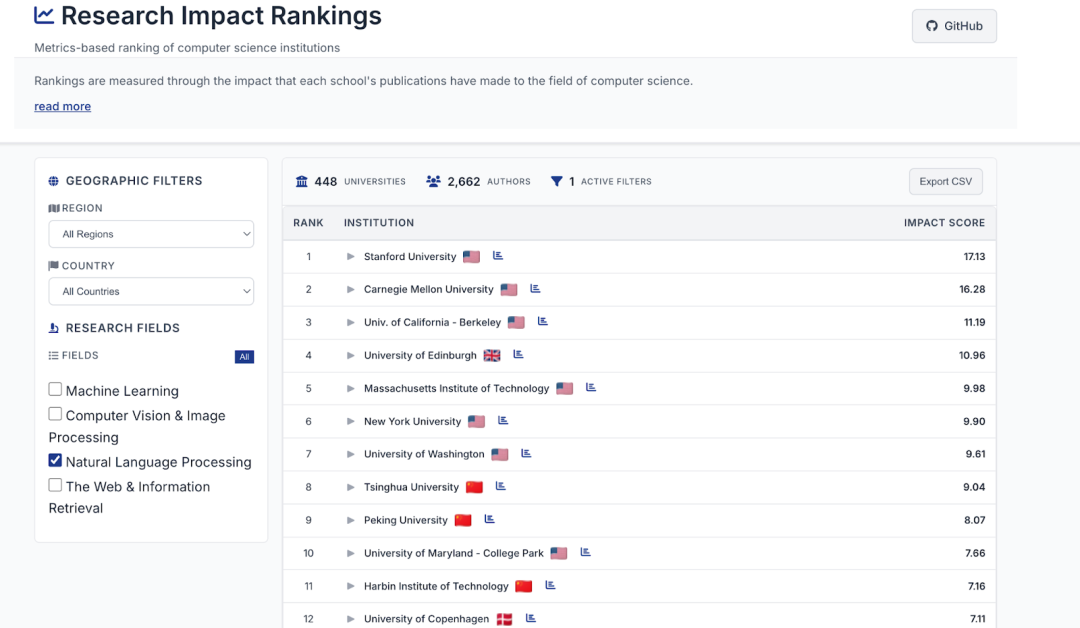
AI Research Impact Ranking:
是否该让 AI 帮助我们,重新定义科研的「质量」?专业读者们觉得哪个排名更符合您心中的观点?
文章来自于微信公众号 “机器之心”,作者 “机器之心”


